
0. Abstract
- 지도 파인튜닝 (Supervised Fine-tuning, SFT)와 강화학습 (Reinforcement Learning, RL)은 기반 모델 (Foundation Model)의 사후 학습 (Post-training)을 위해 널리 사용되는 기법들
- 그러나 모델의 일반성 (Generalization) 향상을 위한 각 모델의 역할은 아직 불분명함
- 본 논문에서는 SFT와 RL의 일반성과 기억력 (memorization)에 대한 효과를 비교 → 텍스트 기반과 시각적 환경
- 두개의 검증 환경 사용
- GeneralPoints: 수학적 추론이 필요한 카드 게임
- V-IRL: 실제 네비게이션 환경 → SFT과 RL로 학습된 모델이 텍스트와 이미지 도메인에서 본적 없는 변화에 일반화 될 수 있는지 평가
- 위 검증을 통해 RL을 결과 기반의 보상 (outcome-based reward)으로 학습한 경우 규칙 기반의 텍스트와 이미지 환경 모두에서 일반화 성능을 보임
- SFT는 이와 대조적으로 학습 데이터를 외우는 경향을 보였으며 두 검증 모두 훈련 데이터를 벗어난 (out-of-distribution, OOD) 데이터에 대해 좋지 못한 일반화 성능을 보임
- 이런 분석들은 RL이 시각적인 도메인의 일반화 성능을 강화하여 시각적인 인지 성능을 향상시킨다는 것을 보임 → 복잡한, 멀티모달 문에에서 일반화 된 지식을 취득
- 하지만 SFT도 여전히 효과적인 RL 학습에 도움이 된다는 것을 보임 → SFT는 모델의 출력 형식을 안정화하며 이후의 RL이 성능 향상을 달성할 수 있도록 함
1. Introduction
- SFT와 RL은 기반 모델 학습에 널리 사용됨 → 하지만 해당 기법들의 일반화에 대한 성능은 불분명
- 본 논문에서는 SFT나 RL이 학습 데이터를 외우는데 주요한 역할을 하는지, 혹은 일반화 되어 새로운 변형된 문제에 적응할 수 있는지를 검증
- 일반화에 대해 2개의 측면에 집중
- 규칙 기반의 텍스트 일반화 (Textual rule-based generalization)
- 학습된 규칙과 변형된 규칙을 적용했을 때 모델의 능력 검증
- 시각적인 일반화 (Visual generalization)
- 색이나 공간적인 외형과 같은 시각적 입력에 대한 변형에 대해 일관적인 성능을 보이는지 측
- 규칙 기반의 텍스트 일반화 (Textual rule-based generalization)
- 텍스트 기반과 시각적 기반 일반화를 위해 2개의 다른 문제를 통해 검증 수행
- GeneralPoints: 모델의 산술적 추론 능력을 평가하기 위해 디자인
- V-IRL: 실제 네비게이션 문제로 모델의 공간적인 추론 능력을 평가
- 본 논문에서는 멀티 스텝 RL 프레임워크를 적용 → 백본 (backbone) 모델에 SFT를 적용 후 RL 적용
- GeneralPoints와 V-IRL 모두 RL이 규칙을 일반화 → 훈련 데이터를 통해 얻은 성능을 본적 없는 규칙에 대해서 전이
- 이와 대조적으로 SFT는 학습된 규칙을 외우고 일반화 하지 못하는 경향을 보임 → 그림 1의 예시 참고

- 또한 텍스트 규칙 기반의 일반화를 넘어 시각적인 도메인의 일반화에서 RL이 시각적인 OOD 문제에서 일반화를 달성하는 것을 확인, 반면 SFT는 여전히 나쁜 성능을 보임
- 시각적인 OOD 일반화 성능에서 멀티턴 RL은 SoTA (State-of-the-art) 성능을 달성 → V-IRL mini 벤치마크에서 33.8%의 성능 향상을 보임 (44.0% → 77.8%)
- 어떻게 RL이 모델의 시각적 능력에 효과를 주는지 이해하기 위해 GeneralPoints에서 추가적인 분석수행
- 출력 기반 보상 함수를 사용하여 RL을 학습 → RL이 SFT에 비해 뛰어난 일반화를 달성
- 하지만 RL이 SFT에 비해 뛰어난 일반화 성능을 보여도 SFT는 여전히 모델의 출력 형식 안정화에 도움을 주며 이것이 RL이 추가적인 성능 향상을 달성할 수 있도록 함
2. Preliminaries
Standard RL terminology
- 유한한 시간 범위에서의 결정 문제 (finite horizon decision making)를 고려 → 일반적인 RL의 개념을 적용할 수 있음
- $\mathcal{S}$: 상태 공간
- $\mathcal{A}$: 행동 공간
- $r: \mathcal{S} \times \mathcal{A} \rightarrow \mathbb{R}$: 보상함수
- $T$: 에피소드 당 최대 스텝 수
- 목표: 전체 반환값 $\max_{\pi \in \Pi} \mathbb{E}{\pi} [\sum{t=0}^{T} r_t]$를 최대화하는 정책 $\pi : \mathcal{S} \rightarrow \mathcal{A}$를 학습하는 것
- $\pi(a|s) \in [0,1]$을 사용 → 상태 $s$에서 $a$를 선택할 확률 = $\pi$
Adapting RL terminology to LLM/VLM with a verifier
- 기반 모델 학습에 멀티턴 RL 세팅을 채택
- $\mathcal{V}$: 이산적이고 유한한 단어 (토큰) 공간
- $\mathcal{V}^m, \mathcal{V}^n$: 입력과 출력 텍스트 공간 → $m, n$은 입력 시퀀스 $v^{in}$과 출력 시퀀스 $v^{out}$의 최대 토큰 길이
- $\mathcal{O}$: 모델이 시각적 입력을 요구하는 경우 (VLM) RGB 이미지의 공간
- VLM에 대한 상태 공간은 $\mathcal{S} := \mathcal{V}^m \times \mathcal{O}$로 정의하며 LLM에 대해서는 $\mathcal{S} := \mathcal{V}^m$으로 정의
- $VER: \mathcal{V}^n \rightarrow \mathbb{R} \times \mathcal{V}^k$를 검증자 (Verifier)로 정의 → $v^{out}$의 출력을 평가하고 텍스트 정보 $v^{ver}$와 출력 기반의 보상 함수 $r$을 생성
- 수학적으로 시간 $t$에 대해 $VER(v_t^{out}) \rightarrow (r_t, v_t^{ver})$로 정의
- 파라미터 $\theta$를 가지는 모델을 정책 네트워크 $\pi_{\theta}:\mathcal{S} \rightarrow \mathcal{V}^n$으로 정의하고 PPO를 강화학습 모델로 사용하여 $\pi_{\theta}$를 업데이트
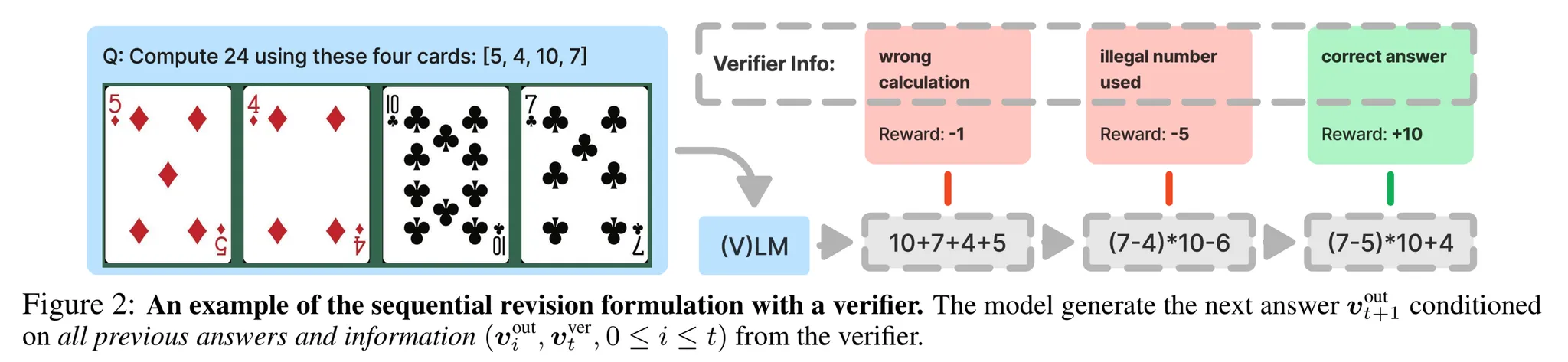
Sequential revision
- 상태-행동 변환을 모델링 하기 위해서 sequential revision formulation 사용
- 시간 스텝 $t=0$에서 초기 입력 $v_0^{in}$은 시스템 프롬프트로 구성되어 있음
- 이후 시간 스텝 $(t \geq1)$에 대해 입력 프롬프트 $v_t^{in}$는 모든 모델의 시스템 프롬프트와 verifier 출력을 연결한 형태 → $[v_k^{out}, v_k^{ver}]_{k=0}^{t-1}$
- Sequential revision을 도식화 한 것은 그림 2 참고
- 상태-행동 전이의 예시는 그림 3 참고

3. Evaluation Tasks
- 서로 다른 사후 학습 기법의 일반성을 평가하기 위해 2개의 문제를 적용
- GeneralPoints: 산술적 추론 능력을 평가하기 위해 디자인 된 새로운 환경
- V-IRL: 실제 시각적 네비게이션 문제에서 모델의 추론 능력을 평가하기 위한 환경
3.1. The General Points Environment
- GeneralPoints는 산술적 추론의 일반화를 평가하기 위해 디자인 된 환경
- 환경의 각 상태 $s$는 4장의 카드를 포함
- 이를 텍스트로 설명하는 경우의 환경을 GP-L로 표기
- 이를 이미지로 나타내는 경우의 환경을 GP-VL로 표기
- 환경의 각 상태 $s$는 4장의 카드를 포함
- 그림 2의 왼쪽을 보면 GeneralPoints의 시각적인 예시를 살펴볼 수 있음
- 목표는 4장의 카드들의 숫자를 사용하여 타겟 숫자 (예시: 24)를 달성하는 수식을 만드는 것
Rule variation
- 모델은 사후 학습 데이터 단순히 외우거나 산술적인 연산을 학습
- 이를 검증하기 위해 규칙에 변화를 줌
- 규칙1: J, Q, K와 같은 문양을 각각 숫자 11, 12, 13으로 사용
- 규칙2: J, Q, K를 모두 동일한 10으로 사용
- 이런 변경은 다양한 세팅에서 모델의 산술적인 추론의 일반화 성능을 평가할 수 있음
- 각 규칙은 입력 프롬프트에 텍스트 형태로 제공 → 그림 3의 [tasks rule] 부분에 사용
- 규칙 기반 일반화를 살펴보기 위해 하나의 규칙으로 모델을 사후 학습하고 다른 규칙을 사용하여 평가를 수행
Visual variation
- 시각적 변화에 대한 일반화 성능을 평가
- 주요한 시각적 도전과제 → 카드의 색에 관계 없이 각 카드의 숫자를 인지하는 것
- 이에 따라 다른 색을 시각적인 변화로 설정 → 시각적 일반화 세팅을 위해 하나의 색으로 모델을 학습하고 다른 색으로 일반화 성능 검증
3.2. The V-IRL Environment
- V-IRL 환경은 실제 네비게이션에서 실제적인 시각 입력을 사용하여 공간적인 추론 능력을 검증
- 두 버전의 환경 사용
- V-IRL-L: 순수하게 글로만 설명한 환경
- V-IRL-VL: 시각-언어적인 입력 사용
- V-IRL의 주요한 시각적 도전은 시각적인 관측으로부터 다른 랜드마크들을 인지하는 것
- 목표: 공간적인 정보를 포함한 명령의 세트를 따라서 타겟 위치까지 이동하는 것
Rule variation
- 모델이 공간적인 지식을 가지게 되는 것인지, 단순히 학습 데이터를 외우는 것인지 검증하기 위해 2개의 행동 공간을 설정
- 절대 방향 행동 공간 (absolute orientation action space) 사용 (”북”, “북동”, “동”, “남동”, “남”, “남서”, “서”, “북서”)
- 상대 방향 행동 공간 (relative orientation action space) 사용 (”왼쪽”, “오른쪽”, “약간 왼쪽”, “약간 오른쪽”) → 90도나 45도 회전
- V-IRL의 네비게이션 문제는 그림 4에서 살펴볼 수 있음

- 또한 V-IRL의 상태-행동 변화에 대한 자세한 설명은 그림 13을 참고

Visual variations
- V-IRL의 주요한 시각적인 어려움은 랜드마크를 인지하는 것 → 그림 4의 초록색 부분 참고
- V-IRL 환경은 여러 다른 도시들의 시각적인 관측을 포함하고 있으므로 한 위치에서 네비게이션을 하도록 모델을 학습하고 해당 모델의 성능을 다른 도시에서 평가
4. Results
- Llama-3.2-Vision-11B를 백본 모델로 사용
- 표준 RLHF와 RL4VLM 파이프라인을 따름 → 모델은 RL 적용 전에 SFT로 초기화
4.1. Generalization across Rules
- GeneralPoints와 V-IRL에 대해 순수한 언어 (-L)와 비전-언어 (-VL)에 대한 변형을 사용 → 규칙에 대한 변형도 포함
- 학습 분포 내부 데이터에 대한 (In-Distribution, ID) 학습 성능과 본적 없는 규칙을 적용한 학습 분포 외부 데이터에 대한 (Out-Of_Distribution, OOD) 일반화 성능을 살펴볼 예정
- GenenralPoints
- ID: J, Q, K를 10으로 설정
- OOD: J, Q, K를 11, 12, 13으로 설정
- V-IRL
- ID: 절대 방향 행동 공간 사용
- OOD: 상대 방향 행동 공간 사용
RL generalizes, SFT memorizes
- 그림 5에서 나온 것 처럼 RL은 지속적으로 LLM, VLM 등의 모든 문제에서 OOD 성능을 개선

- 특히 그림 6에서 볼 수 있듯이 LLM에서 RL은 다음과 같이 성능 개선
- GP-L: +3.5% 성능 개선 (11.5% → 15%)
- V-IRL-L: +11% 성능 개선 (80.8% → 91.8%)
- VLM에서는 RL이 다음과 같이 성능 향상을 보임
- GP-VL: +3% 성능 개선 (11.2% → 14.2%)
- V-IRL-VL: +9.3% 성능 개선 (35.7% → 45%)
- 이와 대조적으로 SFT의 경우 모든 문제의 OOD 평가에서 성능 하락을 보임
- GP-L: -8.1% 성능 하락 (11.5% → 3.4%)
- V-IRL-L: -79.5% 성능 하락 (80.8% → 1.3%)
- GP-VL: -5.6% 성능 하락 (11.2% → 5.6%)
- V-IRL-VL: -33.2% 성능 하락 (35.7% → 2.5%)
4.2. Generalization in Visual Out-of-Distribution Tasks
- 다음으로 시각적인 변화를 주었을 때 OOD 일반화 성능을 살펴보자
- GeneralPoints의 경우 검정 문양 (클로버, 스페이드)으로 VLM을 학습하고 빨간 문양 (다이아몬드, 하트)을 사용하여 OOD 성능을 테스트
- V-IRL에 대해서는 뉴욕에서 수집된 데이터를 학습을 수행하고 원본 V-IRL VLN 미니 벤치마크에서 평가 수행 (전세계 다양한 도시들의 거리를 포함)
RL generalizes in visual OOD tasks
- 그림 7을 살펴보면 시각적인 OOD 문제에 대해 SFT는 어려움을 겪지만 RL은 여전히 일반화를 잘 수행하는 것을 확인할 수 있음
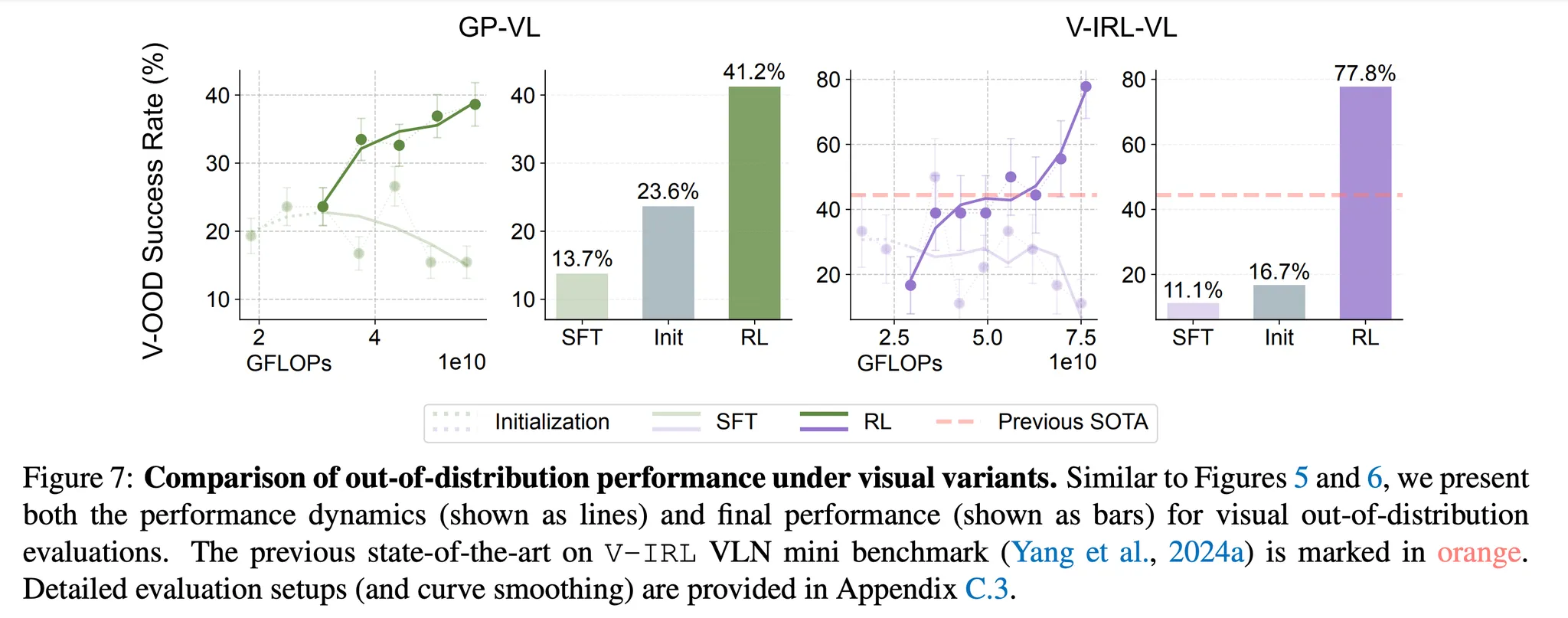
- 특히 GP-VL과 V-IRL-VL에서 RL은 다음과 같은 성능 향상을 보임
- GP-VL: +17.6% 성능 향상 (23.6% → 41.2%)
- V-IRL-VL: +61.1% 성능 향상 (16.7% → 77.8%)
- 반면 SFT는 다음과 같은 성능 저하를 보임
- GP-VL: -9.9% 성능 하락 (23.6% → 13.7%)
- V-IRL-VL: -5.6% (16.7% → 11.1%)
- 본 논문의 멀티턴 RL은 V-IRL 미니 벤치마크에서 SoTA 성능을 보임 → 33.8% 성능 향상 (44.0% → 77.8%)
4.3. RL Improves Visual Capabilities
- 다음 질문: 어떻게 RL이 VLM의 시각적 능력에 영향을 미칠까?
- 이 질문에 대해 알아보기 위해 GP-VL에서 추가적인 ablation study 진행
- 모델의 시각적인 인지 정확도를 통해 검증 → 입력 이미지에 있는 4개의 카드를 인지하는지 확인
- RL과 SFT를 통해 사후 학습 계산량을 늘리는 것이 규칙 기반 OOD의 일반화와 (그림 8 왼쪽) 시각적 인지 정확도, 시각적 OOD에 (그림 8 오른쪽) 영향을 미치는지 확인
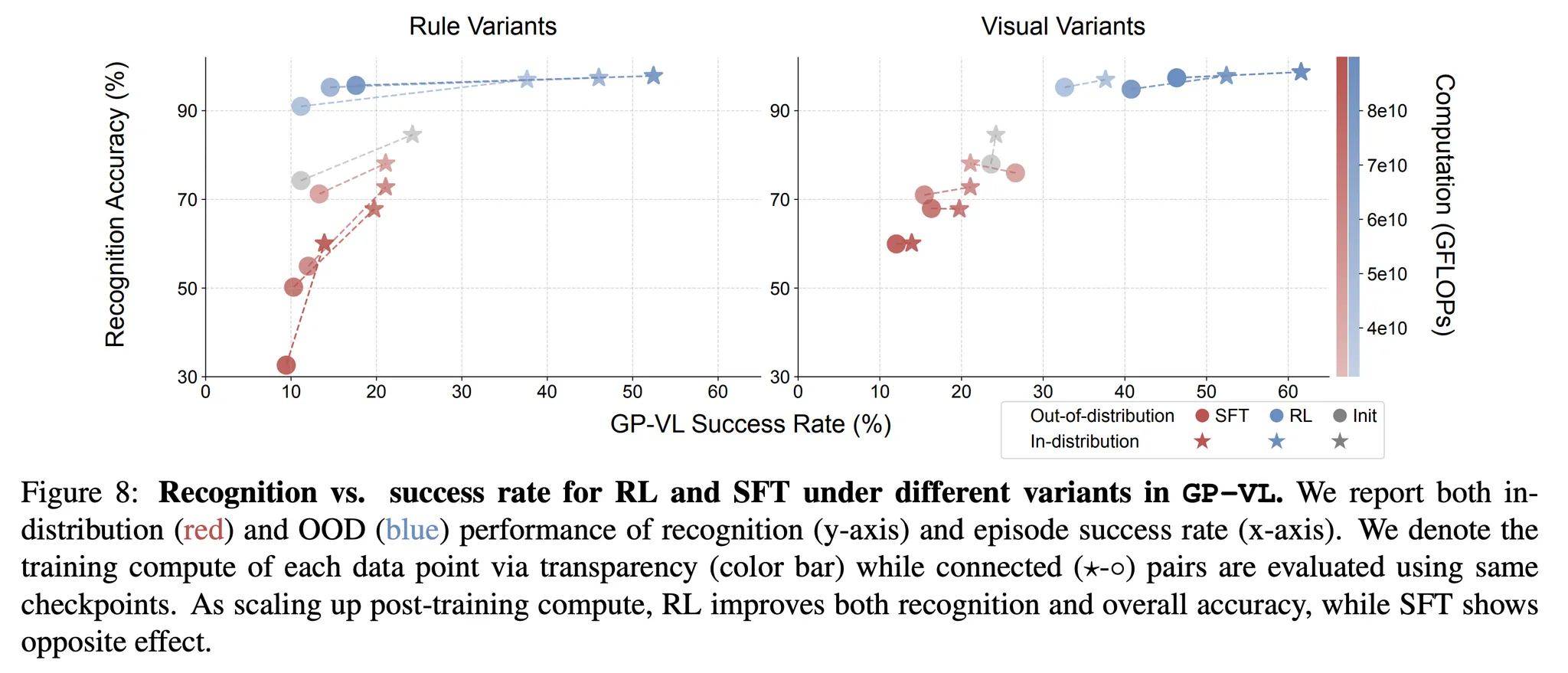
Scaling RL improves visual recognition accuracy in VLM training
- 그림 8에서 볼 수 있듯이 VLM의 시각적 인지 정확도는 전체적인 성능에 큰 형양을 미침
- 추가적으로 RL 계산량을 증가시키는 것은 시각적인 인지 정확도를 개선하는 반면 SFT의 계산량을 증가하는 것은 시각적 인지 정확도와 전반적인 성능을 저하시킴
4.4. The Role of SFT for RL Training
- 모델의 추론과 시각적 능력의 일반화에 RL의 우수성을 확인했지만 실험 파이프라인은 여전히 SFT 이후에 RL을 수행하는 방식을 사용
- 이에 따라 다음과 같은 질문을 할 수 있음 → SFT가 RL 학습을 위해 필요할까?
- 이에 대해 응답하기 위해 GeneralPoints의 언어 버전을 사용하여 Llama 3.2를 기반으로 end-to-end RL만을 사후 학습에 직접 적용한 추가 실험을 수행 → 그림 9 참고
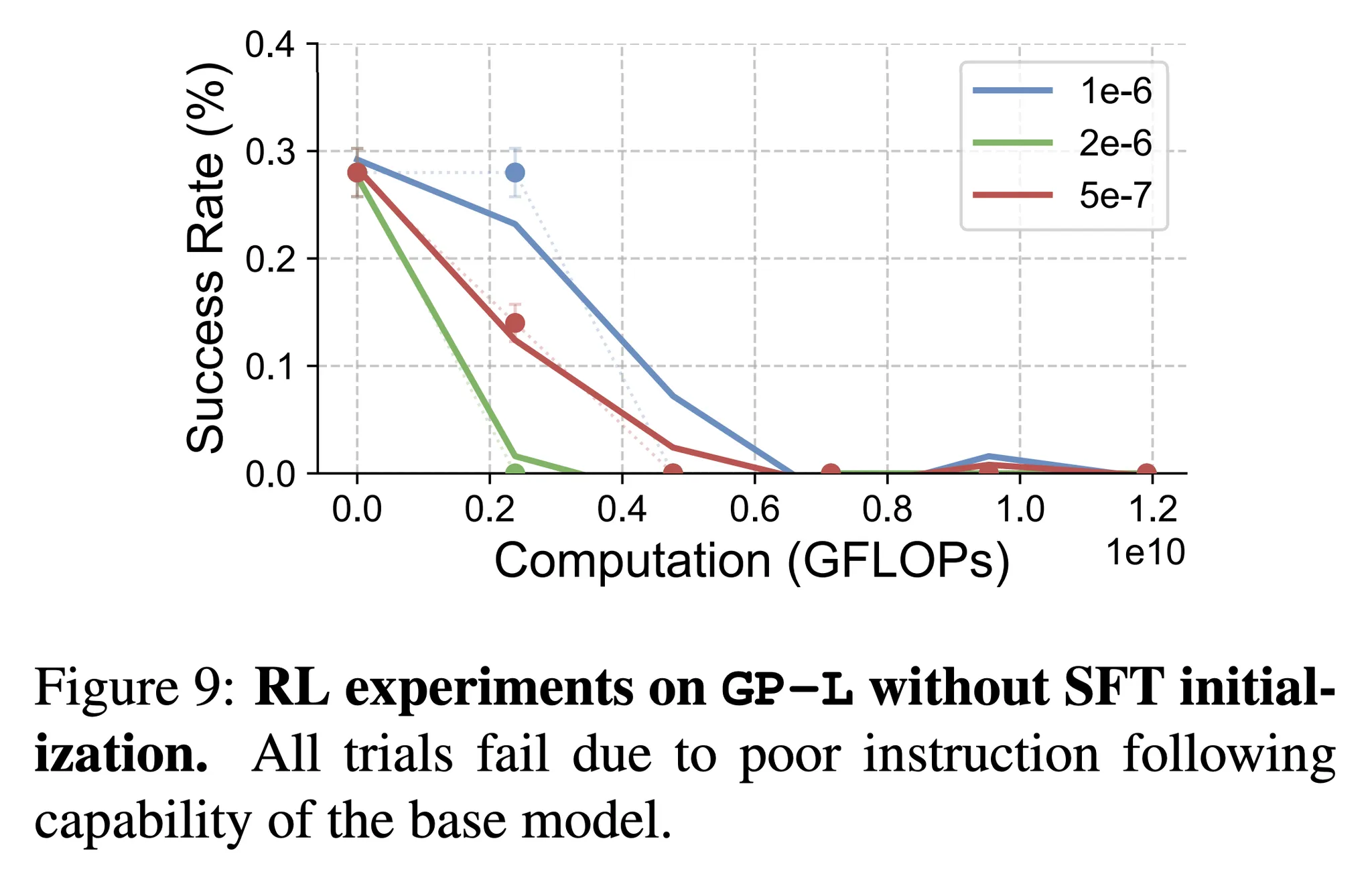
SFT is necessary for RL training when the backbone model does not follow instructions
- 그림 9는 SFT 없이 end-to-end RL만을 적용했을 때 개선에 실패한 결과를 보임
- 더 자세히 살펴보면 SFT를 적용하지 않은 경우 기반 모델은 명령을 따르는 능력에 있어 나쁜 성능을 보임 (실패 케이스는 그림 20을 참고)

- 위 결과는 기반 Llama-3.2-Vision-11B 모델이 길고, 주제를 벗어나며 구조화되지 않은 응답을 하는 것을 보임
- 해당 문제는 문제와 관련된 정보를 검색하거나 강화학습을 위한 보상을 제공하지 못하도록 함
4.5. Role of Verification Iterations
- 검증 (Verification)은 본 논문의 멀티스텝 학습과 평가 파이프라인에 주요한 요소 (그림 2, 3 참고)
- 검증의 필요성과 효과를 더 잘 이해하기 위해 GP-L에서 검증 반복 횟수를 다르게 하며 (1, 3, 5, 10) 실험을 수행 (그림 10 참고)

Scaling up verification improves generalization
- 그림 10을 보면 RL이 더 많은 검증 스텝을 수행할수록 일반화를 잘 하는 것을 확인할 수 있음
- 동일한 계산량 하에서 +2.15% (3 스텝), +2.99% (5 스텝), +5.99% (10 스텝)의 성능 개선을 확인
- 이와 대조적으로 1스텝 검증의 경우 OOD 성능에서 +0.48%의 개선을 보임
5. Conclusion, Discussion and Limitations
- 본 논문에서는 기반 모델에 대해 RL, SFT와 같이 사후 학습을 수행하는 것의 일반화 효과를 분석
- GeneralPoints와 V-IRL 문제를 통해 성능 검증을 수행했고 RL이 일반화 된 지식을 학습하는데 뛰어난 성능을 달성함을 보였지만 이에 반해 SFT는 학습 데이터를 외우는 경향을 보임 (규칙, 시각 변환 모두)
- 이 현상은 멀티모달 산술 능력이나 공간적 추론 능력 등에도 지속적으로 적용됨
- 또한 본 논문에서는 시각적인 인지에서 RL의 효과와 SFT의 역할, 검증 스텝의 역할 등을 살펴봄
- 하지만 본 논문에서는 아래와 같이 2개의 풀지못한 과제들이 남아있음
Failure of SFT on GP-VL
- 그림 5를 살펴보면 GP-VL에서 SFT가 RL과 달리 ID 성능을 달성하는 것에 실패함
- 추가적으로 다른 학습률과 튜닝 파라미터를 수정하며 10번의 실험을 수행했지만 (그림 16) 어떤 것도 RL과 같이 성능이 향상되는 경향을 보이지 않음 (그림 17)

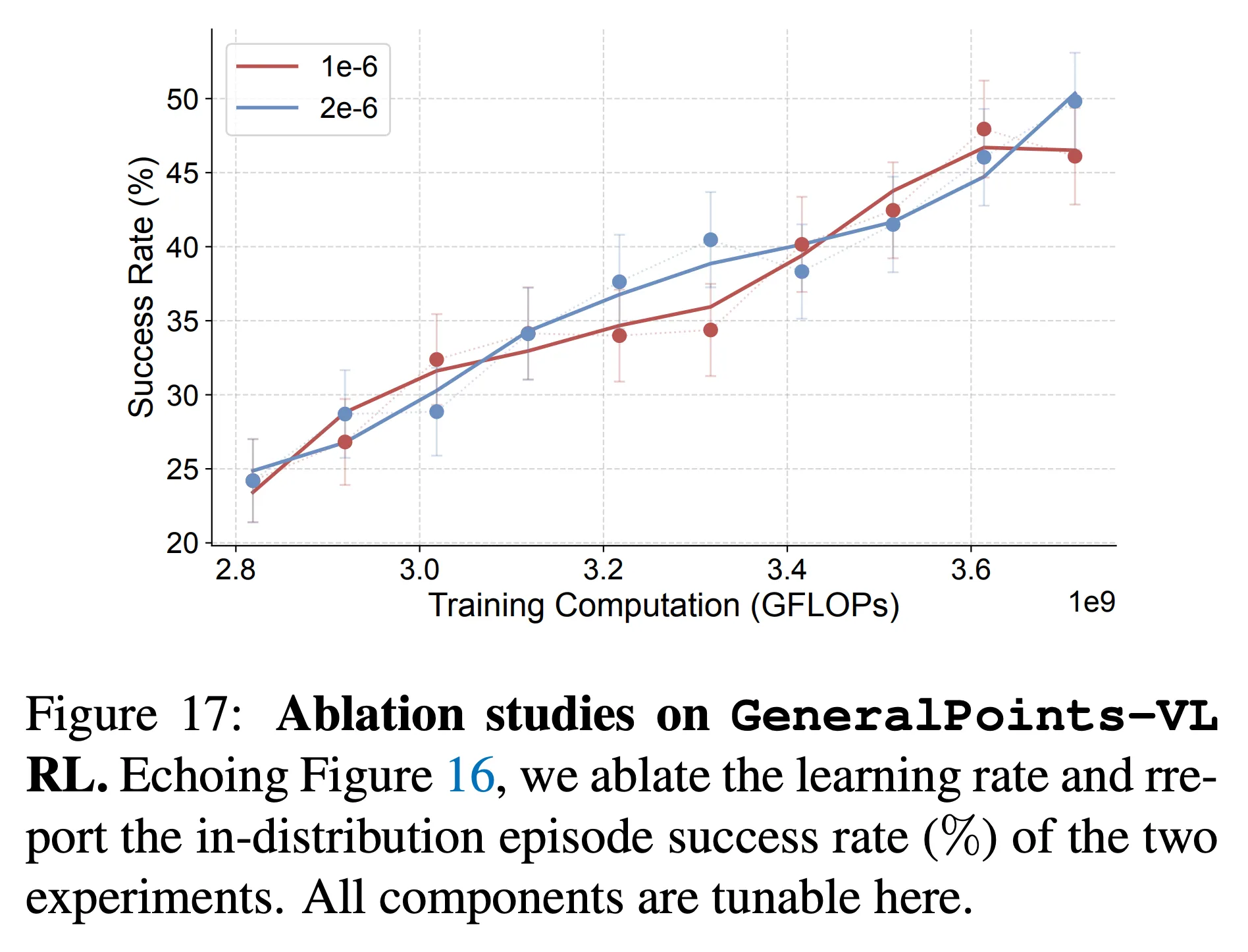
- 또한 그림 8을 참고하면 SFT 연산을 더 수행하는 것은 시각적인 인지 능력의 성능 감소를 보임
- 본 논문의 가설
- SFT는 추론 토큰의 높은 빈도 때문에 지역적으로 추론 토큰을 과적합하고 인지 토큰을 무시 (그림 11 참고)
Limits of RL in corner cases
- SFT는 Llama-3.2의 효과적인 RL 학습을 위해 필요함 → RL을 과하게 튜닝된 SFT 체크포인트에 적용해봄
- 그림 19와 같이 이런 체크포인트에서 학습했을 때는 RL이 OOD 성능을 회복하지 못함
- 실패 케이스는 그림 21에서 살펴볼 수 있음

- Future work → 어떤 SFT가 효율적인 RL 학습을 촉진시킬 수 있는지 살펴볼 것



