반응형

0. Abstract
- 강화학습 알고리즘은 밀집되고 (dense) 잘 형성된 보상 함수가 없는 것이 일반적인 문제점
- 이런 한계를 극복하기 위해 내적 동기부여 (intrinsically motivated) 탐험 기법이 사용됨 → 에이전트가 새로운 상태에 방문하는 경우 보상을 제공
- 하지만 이런 방법은 매우 규모가 큰 환경에서 탐색된 새로운 상태가 실제 문제 해결과 무관한 경우가 많을 때에는 별 도움이 되지 못함
- 본 논문에서는 탐험을 위한 사전 지식으로 텍스트 정보를 사용하는 기법을 제안 → ELLM (Exploring with LLMs)
- 에이전트의 현재 상태를 묘사한 정보를 프롬프트로 한 언어 모델이 제안한 목표를 달성하는 경우 보상 제공
- 대규모의 언어 모델 사전학습을 통해 ELLM은 사람에게 유의미하고 유용한 행동을 사람의 개입 없이 에이전트에게 가이드 할 수 있음
- ELLM은 Crafter 게임 환경과 Housekeep 로봇 시뮬레이터를 통해 평가 수행
- ELLM으로 학습된 에이전트가 사전학습 동안 더욱 상식적인 행동을 잘 수행함
1. Introduction
- 강화학습은 학습자가 목표 행동을 위한 과정에 대해 빈번하게 보상을 받는 경우 잘 동작하지만 직접 보상함수를 설정하는 것은 간단한 문제에 대해서도 많은 공학적 노력이 필요
- 실제적인 복잡한 문제를 풀기 위해서 강화학습 에이전트는 외적으로 정의된 보상 없이도 뭔가를 배워야 함
- 내적 동기부여 강화학습 (Intrinsically Motivated RL) 기법은 새로움, 놀라움, 불확실성, 예측 에러와 같은 보조적인 목표에 기반하여 보상을 제공
- 하지만 새롭거나 예측하지 못하는 것이 유용한 것은 아님 → 사람에게 의미있는 행동으로 유도하지 않음
- 이에 따라 새로움만을 최적화하는 것으로는 충분하지 않음 → 학습된 행동은 “유용”해야함
- 본 논문에서는 언어 기반의 표현 (representation) 뿐만 아니라 사전학습된 언어 모델 (LLM)을 유용한 행동을 위한 정보 제공에 사용
- 본 논문의 기법인 Exploring with LLMs (ELLM)은 언어 모델에게 현재 에이전트의 상태가 주어졌을 때 가능한 목표를 질문하고 에이전트가 해당 제안을 달성한 경우 보상을 제공
- 결과적으로 탐험이 다양하고 사람에게 의미있는 목표를 달성하는 쪽으로 유도됨
2. Structuring Exploration with LLM Priors
- 우선 백그라운드로 다음과 같은 내적 동기부여 RL 기법들에 대해 간단히 살펴보자
- 내적 동기부여 강화학습 알고리즘 (Intrinsically Motivated RL, IM-RL): 행동보다 결과에 대한 탐험을 선택
- 지식 기반 IM (Knowledge-based IMs, KB-IMs): 상태의 다양성을 최대화하는데 집중
- 기술 기반 IM (Competence-based IMs, CB-IMs): 에이전트에 의해 숙련되는 기술들의 다양성을 최대화 (대부분의 행동 시퀀스들은 결과 공간의 굉장히 제한된 부분으로 유도됨: ex. 다양한 이유로 컵이 바닥에 떨어지는 경우 한가지 결과로 이어짐)
2.1. Problem Description
- Partially Observable Markov Decision Process (POMDP) 적용 고려 → $(\mathcal{S}, \mathcal{A}, \mathcal{O}, \Omega, \mathcal{T}, \gamma, \mathcal{R})$로 정의됨
- 환경의 상태 $s \in \mathcal{S}$와 행동 $a \in \mathcal{A}$로 부터 얻어진 관측 $o \in \Omega$ → $\mathcal{O} (o|s,a)$
- $\mathcal{T}(s'|s,a)$는 환경의 역학 (dynamics)을 나타냄
- $\mathcal{R}, \gamma$는 각각 환경의 보상함수와 감가율
- IM 에이전트는 내적 보상 $\mathcal{R}_{int}$를 최적화
- CB-IM 기법은 $\mathcal{R}_{int}$를 목표 조건부 보상 함수 (goal-conditioned reward function)의 일종으로 정의

- 모든 CB-IM 알고리즘은 식 1에서 두가지 요소를 반드시 정의해야함
- 샘플링 할 목표의 분포 (e.g. $\mathcal{G}$)
- 목표 조건부 보상 함수 $\mathcal{R}_{int}(o,a,o'|g)$
- 위 요소들이 주어졌을 때 CB-IM 알고리즘은 $R_{int}$를 최대화하기 위해 목표 조건부 정책 $\pi (a|o,g)$를 학습
- 모든 CB-IM 알고리즘은 식 1에서 두가지 요소를 반드시 정의해야함
2.2. Goal-based Exploration Desiderata
- 어떻게 에이전트가 일반적인 보상함수 $\mathcal{R}$에 대한 목표를 달성하기 위해서 돕는 $\mathcal{G}$와 $\mathcal{R}_{int}(\cdot|g)$을 선택해야할까?
- 탐험 동안 목표에 타겟팅 되도록 하려면 다음의 세가지 특성을 만족해야함
- Diverse: 다양한 목표를 타겟팅하면 이들 중 하나가 타겟 행동과 유사해질 가능성이 증가함
- Common-sense sensitive: 학습이 가능한 목표에 집중해야 하며 (나무 자르기 > 나무 마시기) 사람이 필요로 할만한 분포 하에서 고려 필요 (물 마시기 > 용암으로 걸어가기)
- Context sensitive: 현재 환경의 구성에서 가능한 목표에 집중하도록 학습해야 함 (e.g. 나무가 시야에 보이는 경우에 나무를 자르기)
- 기존의 CB-IM 알고리즘
- 보상 함수 $\mathcal{R}_{int}(2)$를 사람이 직접 정의하며 (1)이 기존 문제의 $\mathcal{R}$과 일치하도록 하면서 목표인 (1)로 유도하기 위해 내적 보상을 사용
- 제안하는 ELLM 알고리즘
- 언어 기반의 목표 표현(representation)과 언어 모델 기반의 목표 생성을 통해 (1)과 (2)에 대해 각 환경에 따라 사람이 직접 정의할 필요성을 감소시킴
- 본 논문에서는 LLM의 지식이 다양하고 사람에게 의미있으면서도 컨텍스트를 고려한 목표를 자동으로 생성할 것으로 가정

2.3. Goal Generation with LLMs ($\mathcal{G}$)
- 사전학습된 언어 모델은 넓게 3개의 카테고리로 고려할 수 있음
- Autoregressive, masked, encoder-decoder 모델
- Autoregressive 모델 (e.g. GPT)
- 이전 단어들이 주어졌을 때 다음 단어의 log-likelihood를 최대화 하도록 학습
- Encoder-only 모델 (e.g. BERT)
- 마스킹 된 목표를 기반으로 학습 → 문장의 의미를 효과적으로 인코딩
- 큰 텍스트 덩어리로 사전학습한 언어 모델은 다양한 언어 이해와 생성 문제에서 인상적인 제로- 혹은 퓨샷 능력을 보임
- ELLM은 autoregressive 언어 모델을 사용하여 목표를 생성하고 masked 언어 모델을 사용하여 목표의 벡터 표현 (representation)을 생성
- 본 논문에서는 에이전트의 가능한 행동의 리스트와 현재 관측에 대한 텍스트 설명을 LLM에 프롬프팅하여 목표를 취득
- 현재 관측은 state captioner $C_{obs}: \Omega \rightarrow \Sigma^$을 통해 취득 ($\Sigma^$은 모든 문자열의 세트 → 그림 2 참고)
- LLM으로부터 목표를 도출하는 2개의 구체적인 방법을 사용
- 개방형 생성(open-ended generation) → LLM이 제안된 목표 (e.g. 다음으로 너는 …. 해야함)의 텍스트 설명을 출력
- 폐쇄형 (closed-form) → QA 문제로 LLM에 가능한 목표들이 주어짐 (e.g. 에이전트가 X 해야되나? → 네/아니오)
- 여기서 LLM의 목표 제안은 Yes의 log-확률이 No 보다 높을 때 선택됨
- LLM이 모든 가능한 목표에 대해 사전지식이 없으므로 퓨샷 프롬프팅을 통해 원하는 제안에 대한 가이드를 제공할 수 있음 → 전체 프롬프트는 부록 D 참고
2.4. Rewarding LLM Goals ($\mathcal{R}_{int}$)
- 다음으로 목표 조건부 보상 (2)에 대해 생각해보자
- 주어진 목표 $g$ (식1의 $\mathcal{R}{int}$)를 위한 보상 생성 방법 → LLM이 생성한 목표와 transition captioner ($C{transition}: \Omega \times \mathcal{A} \times \Omega \rightarrow \Sigma$)에 의해 계산된 환경에서 에이전트의 변화 (transition)에 대한 설명 간의 의미적인 유사도 (semantic similarity)를 계산

- 여기서 의미적인 유사도 함수 $\triangle(\cdot , \cdot)$은 캡션과 목표에 대해 언어 모델 인코더 $E(\cdot)$으로부터 얻은 표현 간의 코사인 유사도 (cosine similarity)로 정의
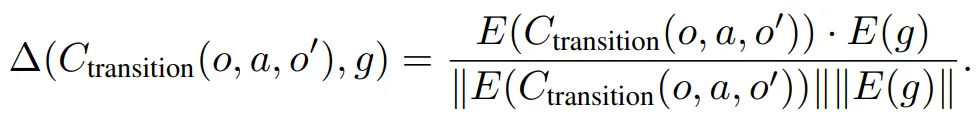
- $E(\cdot)$를 위해서는 사전학습 된 SentenceBERT 모델을 사용
- 변화의 캡션이 목표의 묘사와 충분히 가까운 경우 ($\triangle > T$, 여기서 $T$는 유사도에 대한 기준 하이퍼파라미터) 에이전트는 해당 유사도에 비례하여 보상을 제공
- 또한 다수의 목표가 제안될 수 있기 때문에 k개의 제안에 대해 목표 기반 보상의 최대값을 취하는 방식을 사용
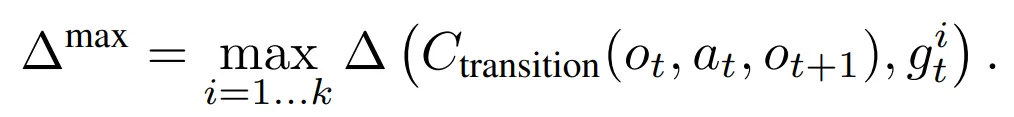
- 결과적으로 식 1의 CB-IM 기법의 일반적인 보상함수를 다음과 같이 정의

2.5. Implementation Details

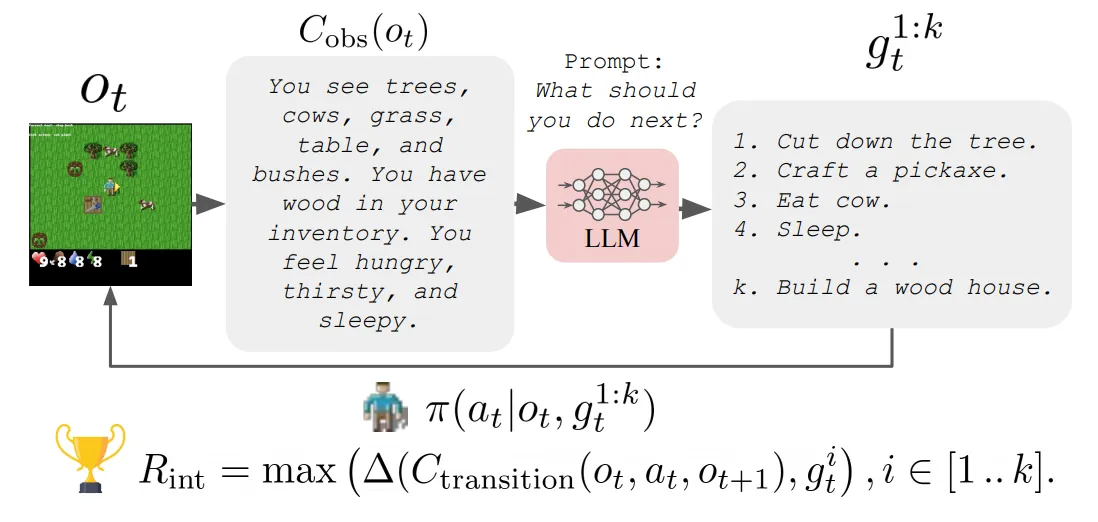
- ELLM 알고리즘의 전체적인 알고리즘은 알고리즘 1에 정리되어 있으며 파이프라인에 대해서는 그림 1을 참고
- 새로움에 대한 편향을 부여하기 위해 에이전트가 동일한 에피소드에서 이미 달성한 내용은 언어모델의 제안에서 제거
- 이는 에이전트가 동일한 목표를 반복적으로 탐험하는 것을 방지 (부록 L을 참고하면 해당 기법이 필수적이라는 것을 보임)
- 에이전트 학습에 있어 두가지 형태를 고려
- 목표 조건부 설정
- 에이전트에게 제안된 목표의 리스트의 문장 임베딩이 주어짐 → $\pi(a|o, E(g^{1:k}))$
- 목표 없는 설정
- 에이전트가 제안된 목표에 접근하지 않음 → $\pi(a|o)$
- 두 경우 모두 $\mathcal{R}_{int}$는 동일하게 사용
- 목표 조건부 설정
- 목표 조건부 에이전트는 여러움과 이점을 동시에 가짐
- 에이전트가 목표의 차이에 대한 의미를 학습하고 이를 보상과 연결시키는데 시간이 걸림
- 언어를 기반으로 한 목표를 조건부로 하는 정책은 단순히 탐험 보상만으로 학습된 에이전트에 비해 세부적인 문제에 대해 더욱 적용하기 좋음
- 본 논문에서는 정책의 입력으로 두 종류를 고려
- 부분적으로 관측 가능한 (partially observable) 픽셀 관측만 사용
- 상태 캡션에 대한 임베딩 $E(C_{obs}(o))$와 결합된 픽셀 관측 사용
- 2가 더욱 좋은 결과를 보이므로 본 논문의 모든 실험은 2를 기반으로 진행
- 모든 실험에 대해서는 DQN 알고리즘을 학습하여 사용 → 부록 H에 자세한 구현 내용 포함
- 캡션 함수로 사용될 수 있는 기존의 요소들
- 실제 시뮬레이터의 상태
- 캡션 모델
- 행동 인지 모델
- 멀티모달 비전-언어 모델
3. Experiments

- 본 논문의 실험은 다음의 가설들을 테스트하기 위해 수행
- (H1) 프롬프팅 된 사전학습 LLM들은 2.2에서 정의한 세가지 특성 (diversity, common sense, context sensitivity)를 만족하면서도 설득력있고 유용한 탐험 목표를 생성
- (H2) 해당 탐험 목표들에 대해 ELLM 에이전트를 학습하는 것은 LLM이 적용되지 않은 기법에 비해 세부적인 문제들에 대해 개선된 성능을 보임
- 본 논문에서는 ELLM을 두개의 복잡한 환경에서 평가 (그림 3 참고)
- Crafter: 장기적인 생존 전략을 수립하기 위한 탐험이 요구됨
- Housekeep: 가정 내 물건의 정리에 대한 상식을 요구하는 로봇 환경
- 환경의 차이
- 시점 (3인칭 vs 1인칭)
- 행동 공간 (크고 고차원 vs 저차원)
- 각 환경에서 ELLM은 기존의 IM-RL 기법들, 실제 보상을 기반으로한 oracle, ELLM의 ablation과 성능 비교 → 표 1 참고

3.1. Crafter
Environment Description
- ELLM을 Crafter 환경에서 테스트 → 마인크래프트와 유사한 2D 버전의 환경
- 부분적으로 관측 가능한 월드가 점진적으로 생성되며 수집과 물건들을 제작해야함
- 환경의 학습을 위해 기존 환경을 두가지 방법으로 변경
- Crafter의 기존 행동 공간은 많은 수의 도메인 지식을 요구함
- 에이전트에 기반하여 하나의 ‘do’ 행동이 다른 방식으로 해석되도록 설정되어있음
- 실제 환경에서 저차원 행동이 다르게 적용되도록 함 (좀비 앞에서는 ‘공격’, 식물 앞에서는 ‘먹기’)
- 본 논문에서는 이를 제거하고 더 구체적으로 동사와 명사의 조합으로 구성 → 유용함을 보장할 수 없음 (e.g. 먹다 + 좀비)
- 이는 Crafter가 다양한 관계없으며 상식적이지 않은 넓은 범위의 시도를 하도록 함
- 이를 통해 언어 모델이 목표 공간을 좁혀나가며 그럴듯한 목표를 찾을 수 있는 기회를 제공
- 자세한 내용은 부록 C 참고
- 에이전트에 기반하여 하나의 ‘do’ 행동이 다른 방식으로 해석되도록 설정되어있음
- RL이 모든 조건에 대해 더 쉽게 학습하도록 하기 위해 적에 대한 에이전트 데미지를 증가시키고 테이블을 조립하는데 요구되는 나무의 양을 감소시킴 → 2개에서 1개로
- Crafter의 기존 행동 공간은 많은 수의 도메인 지식을 요구함
- 위 환경 변화들에 대한 결과의 대한 비교는 부록의 그림 10 참고

- Codex를 LLM으로 사용하여 ELLM에 대해 개방형 제안을 생성
- 직접적으로 LLM으로부터 생성된 텍스트를 보상을 위한 제안된 목표의 세트로 설정
- 각 쿼리 프롬프트는 다음으로 구성되어 있음
- 에이전트가 사용할 수 있는 가능한 동사의 리스트 (모든 가능한 명사의 리스트는 아님)
- 에이전트의 현재 상태에 대한 모사
- 질문: 무엇을 할 것인가? (원문: What do you do?)
Goals suggested by the LLM
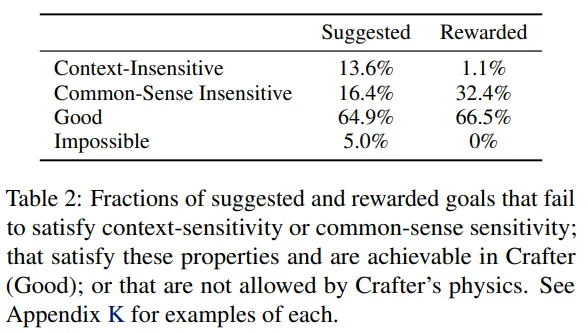
- H1에 응답하기 위해 표 2에서 LLM에 의해 제안된 목표들에 대해 살펴봄 → 목표들은 diverse, context-sensitive, common-sensical 할까?
- 대부분의 제안된 목표들 (64.9%)은 context-sensitive하고 sensible하며 게임 안에서 달성 가능했음
- 최대 5% 정도만이 Crafter에서 물리적으로 불가능한 목표를 제안 (e.g. build a house)
- 마지막 1/3의 목표들은 context-sensitivity (13.6%)나 common-sense (16.4%)를 어기는 목표를 생성
Pretraining exploration performance
- 완벽한 탐험 기법은 가능한 달성 요소들에 대한 사전지식 없이 매 에피소드마다 Crafter의 달성 요소들을 모두 잠금 해제해야함
- 이에 따라 탐험의 품질은 사전학습 동안 에피소드마다 달성 요소들을 달성하는 평균 수로 평가 (그림 4 참고)
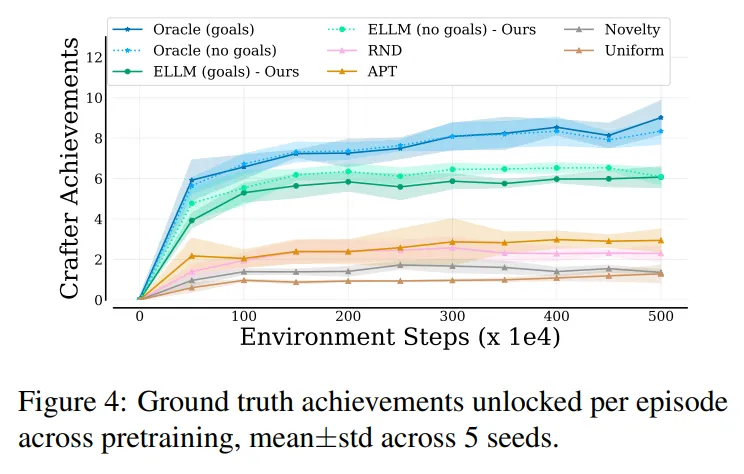
- ELLM의 경우 매 에피소드마다 6개 정도의 달성 요소를 잠금 해제 (실제 보상을 사용하는 Oracle은 평균 9개 달성)
- 이는 새로움만을 추구하는 다른 탐험 기법 (APT, RND, Novelty)들을 뛰어넘는 성능 → 대부분 평균적으로 3개 이하를 달성
- 표 2에서 살펴볼 수 있듯이 ELLM은 새로움만을 추구하는 것이 아니라 상식적인 목표를 생성
- 이는 Crafter에서의 탐험이 H1을 지원하는 것을 의미
- 또한 각 기법에 대해 다양한 변형을 수행하여 성능 비교
- 목표 조건 추가/제거, 텍스트 관측 추가/제거
- 사전 학습 동안 목표 조건을 추가하는 것이 눈에 띄는 이점을 가져온다는 사실은 발견하지 못함
- 시각적 + 텍스트 관측으로 학습하는 것이 시각적 관측만 사용한 것 보다 더 뛰어난 성능을 보이는 것이 모든 변형 테스트들에서 확인됨 (부록의 그림 8에서 불투명과 투명한 바 참고)

- 또한 단순히 사전학습 정책을 특정 문제에 대해 파인튜닝 하는 것은 모든 사전학습 알고리즘에 대해 나쁜 성능을 보임
- 이는 관련된 특징 (feature)과 Q 값이 사전학습과 파인튜닝 사이에 차이가 있기 때문으로 생각
- 사전 학습된 정책을 사용하는 것이 탐험을 지도하는데 더 효과적임을 보였음
- 부록 M 참고
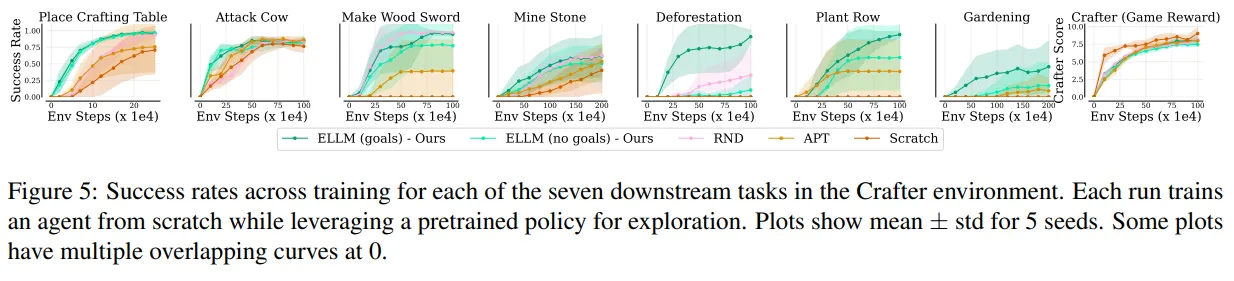
- 그림 5는 강력한 두 베이스라인 알고리즘 RND, APT와 ELLM의 성능을 비교
- ELLM의 골 조건부 버전에서는 에이전트에 문제를 달성하기 위해 필요한 중간 목표의 시퀀스 제공
- 사전 학습 동안 모든 중간 목표를 목표 조건부 사전 학습 에이전트가 목표 조건부가 아닌 에이전트에 비해 좋은 성능을 보임
ELLM with imperfect transition captioner
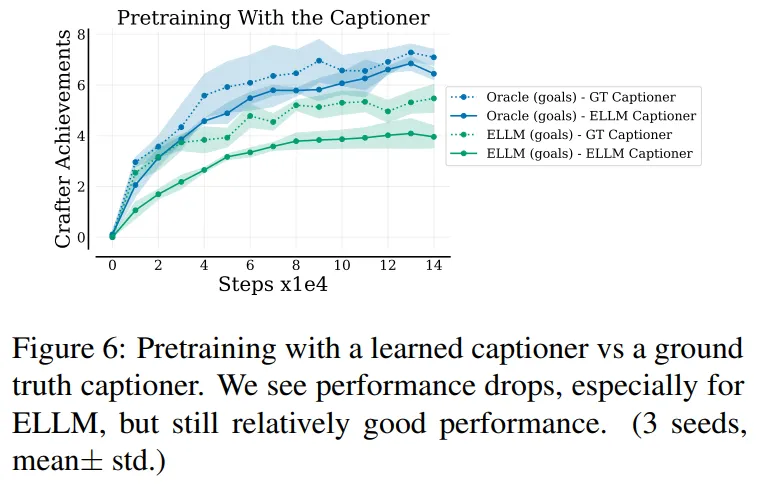
- 완벽한 captioner는 몇몇 환경에서는 취득이 어려움
- 학습된 captioner는 더욱 언어적인 다양성을 제공하고 실수를 하는 경우가 있음
- ELLM이 다양하면서도 완전하지 않은 캡션을 사용할 때에 대한 강인성을 테스트
- 완벽한 transition captioner $C_{transition}$을 사람과 합성 데이터 (847+900 라벨)로 학습한 captioner로 대체 (ClipCap 알고리즘 사용)
- 비록 false-negative 비율은 적었지만 (목표 달성을 잘 감지) false positive의 비율이 상대적으로 높음
- 이는 생성된 캡션과 LLM에 의해 생성된 목표에 대한 설명이 유사해서 잠금 해제되지 않은 달성 요소에 대해 보상을 생성한 것
- 그림 6이 불완전한 captioner를 사용했을 때에도 전체적으로 ELLM의 성능이 강인함을 보임
3.2. Housekeep
Environment description
- Housekeep은 에이전트가 잘못 놓인 물건들을 정리하면서 집을 청소하도록 로봇을 제어하는 환경
- 잘못 놓인 물건을 제대로 정리하기 위해서는 상식 능력을 요구함
- 본 논문에서는 Housekeep의 단순화 된 부분에 집중 → 각 방에 4개의 다른 장면으로 구성, 5개의 잘못 놓인 물건들이 있음
- 정리 성공률을 탐험의 품질 평가에 사용 → 상식적인 탐험을 하는 경우 더 좋은 성능
- 100% 성공률은 에이전트가 5개의 잘못 놓인 물건들을 올바른 위치에 집어서 놓는 것을 의미
- Crafter의 조합 가능하며 고차원적인 행동 공간과는 다르게 Housekeep은 저차원 행동으로 동작 → 전방 이동, 회전, 위아래 보기, 물건 집기, 물건 놓기
- 이는 ELLM이 고차원의 탐험이 가능하도록 함
- LLM으로 text-davinci-002 InstructGPT 모델을 사용
- 눈에 보이는 물건들에 대한 설명, 현재 물건들을 배치할만한 위치 (receptacle), 이전에 눈에 보인 저장 공간을 제공하고 모든 가능한 물건-저장소 맵핑의 리스트를 생성
- ELLM의 폐쇄형 버전을 사용 → LLM에게 각 물건이 각 배치할만한 위치에 배치되었는지 예/아니오 질문으로 질의
- 에이전트는 두 종류의 목표를 제공받음
- 제안된 배치할만한 위치에 있지 않은 물건을 집음
- 잡은 물건을 제안된 위치에 배치
Goals suggested by LLM
- Housekeep에서는 LLM 목표를 정리에 대한 일치/불일치의 분류 정확도로 평가 (표 3)

- LLM 불일치 인식에 대한 정확도 (e.g. 주방 싱크대에 꽃병)는 87% 이상
- 일치에 대한 인식이 물건과 배치할 위치에 따라 크게 달라짐 (50-90%)
Pretraining and downstream performance
- H1을 조사하기 위해 ELLM을 다른 강력한 베이스라인 (RND, APT, Novelty)와 비교

- 사전학습과 파인튜닝 모두에 대해서 실제 정리 성공률과 비교한 샘플 효율성 그래프를 그림 7 (a)에서 살펴볼 수 있음
- 4개의 문제 중 3개에서 ELLM이 더 높은 성공률을 보이는 것을 알 수 있음, 특히 첫 2개의 문제에서는 훨씬 높은 성공률을 보임
- 표 3에서도 해당 2개의 문제에 대해 더 높은 LLM 정확도를 보이는 것을 확인할 수 있음
- H2를 위해서 사전 학습 모델을 사용하여 세부 정리 문제를 2가지 다른 방식으로 테스트
- 직접 사전 학습 모델을 정리에 대한 정답을 기반으로 사전 학습
- 그림 7a의 세로 점선 이후를 살펴보면 됨 → 베이스라인과 유사하거나 이를 뛰어넘는 성능을 보임
- 흥미로운 것은 파인튜닝이 시작했을 때 갑자기 성능이 떨어지는 모습을 보임 → 원인은 골 임베딩 변화에 따라 재학습을 해야하기 때문으로 추정
- 그림 7b에서 새로운 에이전트를 세부적인 문제에 직접적으로 학습 → 동결한 (frozen) 사전학습 모델을 $\epsilon$-greedy 탐험을 적용한 탐험 액터로 사용 → 이 경우에도 ELLM이 다른 베이스라인들을 뛰어넘는 성능을 보임 (원문: we present results for directly training a new agent on the downstream task, using the frozen pretrained model as an exploratory actor during ε-greedy exploration.)
- 직접 사전 학습 모델을 정리에 대한 정답을 기반으로 사전 학습
4. Conclusion and Discussion
- 본 논문에서는 ELLM을 제공 → 내적 동기부여 탐험 기법으로 사전학습된 LLM을 적용하여 상식적이며 설득력있게 유용한 행동을 취하도록 탐험을 유도하는 것을 목표로 함
- ELLM은 새로운 것을 탐색하는 접근을 넘어 상식적인 목표를 위한 탐험에 집중하도록 함 → 이는 넓은 범위의 가능한 행동 중 아주 적은 수만 유용한 환경에서 도움이 됨
- 해당 기법이 도움이 되지 않는 환경
- 목표 기반 탐험을 위한 공간이 적음
- 목표가 사람의 상식과 관련이 없거나 언어로 표현할 수 없음
- 상태 정보를 자연어로 나타내는 것이 불가능
- LLM은 프롬프트에 민감하며 잘 선택된 프롬프트를 사용하더라도 LLM은 종종 에러를 발생시킴 (대부분 도메인 지식 부족 때문에 발생)
- False negative는 에이전트가 중요한 기술들을 학습하는 것을 영구적으로 방해할 수 있음
- Crafter 환경에서 LLM이 나무 곡괭이를 만들라고 제안하지 않음
- 이 한계를 해결하기 위한 몇가지 방법들이 있음
- ELLM을 RND와 같은 다른 KB-IM 보상과 결합
- 과거의 달성에 대한 설명을 LLM에 프롬프팅 → LLM이 달성 가능한 목표의 공간을 학습할 수 있음
- LLM 프롬프트를 기반으로 도메인 지식을 주입
- LLM을 해당 문제에 대한 데이터로 파인튜닝
- ELLM은 상태와 변화에 대한 캡션이 필요함
- 그러나 몇몇 환경에서 해당 captioner는 데모를 수집하는 것이나 직접 구성한 보상함수보다 못할 수 있음
- 하지만 본 논문의 저자들은 범용 캡션 모델의 발전에 따라 더 많은 문제에 captioner를 적용할 수 있을 것으로 생각
- 제안의 품질에 대한 개선이 모델의 크기와 매우 밀접한 연관이 있음
- 텍스트 외에 일반적 목적의 생성 모델이 적용될 수도 있음 → ELLM과 같은 접근이 설득력있는 시각적 목표를 제공하거나 다른 상태 표현을 통해 목표를 제공할 수도 있음
반응형
'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| Pretraining for Language-Conditioned Imitation with Transformers (3) | 2024.11.23 |
|---|---|
| Stop Regressing: Training Value Function via Classification for Scalable Deep RL (0) | 2024.11.22 |
| EUREKA: Human-level Reward Design via Coding Large Language Models (2) | 2024.11.20 |
| Training Diffusion Models with Reinforcement Learning (2) | 2024.11.16 |
| Collaborating with Humans without Human Data (8) | 2024.11.15 |



