반응형

- Paper: https://offline-rl-neurips.github.io/2021/pdf/40.pdf
- 코드 및 데이터셋: https://github.com/Louiealbp/TDT
0. Abstract
- 본 논문은 언어 입력을 사용하여 세부적인 문제를 효율적으로 학습하는 강화학습 에이전트에 대한 연구를 수행
- 이를 위해 멀티모달 벤치마크를 제안
- 텍스트 조건부 (Text-Conditioned) Frostbite → 에이전트가 Atari Frostbite 환경에서 텍스트 명령으로 정의된 문제를 달성해야 함
- 학습을 위해 5M 개의 텍스트로 라벨링 된 transition들을 제공
- 해당 벤치마크를 통해 Text Decision Transformer (TDT)를 평가
- 텍스트, 상태, 행동 토큰을 통해 직접적으로 동작하는 트랜스포머
- 베이스라인 구조에 비해 좋은 성능을 보임
- 이를 통해 사전학습의 효과를 평가 → 적은 데이터 세팅에서 비지도 사전학습이 개선된 결과를 보인다는 것을 확인
1. Introduction
- 기존의 강화학습 기법 → 보상 함수에 대한 정의 필요
- 본 논문에서는 언어를 이해하는 강화학습 에이전트의 학습을 목적으로 함 → 유연하고 해석 가능한 인터페이스 구현 및 인간과 상호작용 가능
- 해당 기법에 대한 연구를 위해 새로운 벤치마크와 데이터셋을 제안 → https://github.com/Louiealbp/TDT
- 텍스트 조건부 Frostbite → 에이전트가 Atari Frostbite 환경에서 언어 명령으로 정의된 문제를 달성
- 다양한 종류의 문제로 구성
- 쉬운 문제: “오른쪽에 있도록 노력해라”
- 어려운 문제: “네번째 빙원 (Ice Floe)에서 최대한 오랜 시간을 보내라”
- 본 논문은 친숙하고 잘 연구된 Atari Frostbite에서 자연어를 복잡한 목표와 행동에 결합하는 것을 목표로 함
- 이를 위해 텍스트-상태-행동 시퀀스에 대해 동작하는 트랜스포머를 소개 → Text Decision Transformer (TDT)
- Decision Transformer에 자연어 골을 조건부로 하는 세팅을 추가하여 보상 토큰을 텍스트 토큰으로 대체 (그림 1 참고)

- 본 논문의 contribution
- 새로운 멀티모달 벤치마크인 텍스트-조건부 Frostbite를 제안 → 500개의 다른 문제에 대해 5M개의 라벨링 된 transition 데이터셋을 제공
- Text Decision Transformer 평가 → MLP 베이스라인을 뛰어넘는 성능을 달성 → 시퀀스 모델링 기반 접근의 우수성을 보임
- 언어와 경로에 대해 비지도 사전학습을 수행 → 경로 기반 사전학습이 적은 데이터 세팅에서 개선된 성능을 보임을 확인, 또한 scaling laws에 대한 실험을 수행하여 TDT가 더 많은 데이터가 있으면 복잡한 문제에서 성능이 향상됨을 확인
2. Preliminaries
2.1. Language-Conditioned Imitation Learning
- 언어 조건부 모방 학습 문제에서는 다음의 정보를 제공
- $(\mathcal{S}, \mathcal{A}, \mathcal{M}, \mathcal{P}, \mathcal{R})_i$ → 상태, 행동, 보상, 문제, 전환 역학 (transition dynamics), 보상 혹은 스코어 함수
- 경로 $\tau = (s_1, a_1, ..., s_t, a_t )$는 상태와 행동의 시퀀스로 전환 역학과 매 스텝 에이전트의 행동에 의해 생성
- 스코어 함수 $\mathcal{R}$는 경로 $\tau$와 텍스트 기반 문제 $m$을 통해 해당 경로가 해당 문제에 대해 성공한 정도를 출력
- 정책/모델 $\pi_{\theta}(a_t | s_{\leq t}, a_{\leq t},m)$은 스코어 함수를 최대화 하는 행동을 출력하도록 함 → $\mathbb{E}{a \sim \pi{\theta}}[R(\tau, m)]$
- 모델은 학습할 때 전문가의 경로-언어 데이터 쌍 $(\tau, m)$에 접근
2.2. Transformers
- 트랜스포머는 시퀀스 모델링 문제에 대해 가장 선두주자인 모델
- 순차적인 셀프-어텐션 모듈 사용
- 각 셀프 어텐션 모듈은 n개의 임베딩 시퀀스를 입력으로 하고 동일한 차원을 가지는 또 다른 n개의 임베딩들을 출력
- 셀프-어텐션 모듈의 연산 과정
- 현재의 임베딩 $x_i$와 $q_i$를 제공하는 쿼리 행렬 $Q$, 그리고 키 $k_i$를 제공하는 키 행렬 $K$ 사이의 내적을 수행
- 모델은 $j \in [1,n]$에 대해 키와 쿼리 사이의 내적을 수행하고 $n$ 로짓을 출력 → 소프트맥스를 적용하여 확률 분포로 변환
- 최종 결과는 value 벡터 $v_i$의 컨벡스 결합 → 확률분포에 따라 가중치를 지정
- $i$번째 요소에 대한 출력 $z_i$는 다음과 같이 연산 가능
2.3. Decision Transformer
- Decision Transformer (DT)를 기반으로 본 논문의 연구 수행 → GPT2 트랜스포머 구조 사용
- DT는 경로의 시퀀스를 autoregressive하게 모델링 → $(\hat{R}_1, s_1, a_1, ..., \hat{R}_t, s_t, a_t)$
- $\hat{R}_t$는 스텝 $t$부터 에피소드 끝까지의 반환값
- 연산의 효율성을 위해 DT는 오직 마지막 $K$ 시간 스텝만을 모델의 입력으로 사용 → 컨텍스트 사이즈
- 컨텍스트 사이즈가 1인 경우 = Markovian 정책
3. Environment and Dataset
- 본 논문의 첫번째 contribution은 텍스트-조건부 모방 모델의 성능을 평가하기 위한 환경을 제공하는 것
- Lake et al. [2017]이 제안한 “Frostbite Challenge”를 사용 → 저자는 Frostbite가 어려운 문제라고 주장 → 시간에 따라 전략이 확장되어야 하고 문제를 완수하기 위한 다양한 방법이 존재
- 해당 문제를 위한 데이터셋 구축을 위해 수동으로 몇 백개의 문제와 경로들을 수집
- 해당 문제들은 “움직이지 않기” 부터 “네번째 빙원에서 최대한 오래 머무르기”, “첫번째 목숨에서 게에게 죽기” 등이 있음
3.1. Environment Details
Evaluation via RAM state
- 해당 문제에서 첫번째 어려운 점은 결정론적인 (Deterministic) 평가 전략을 구축하는 것
- 이를 위해 에이전트의 평가는 게임의 RAM 상태를 평가하는 것으로 수행됨 → 레벨, 위치, 점수나 다른 에이전트의 값들을 계산하고 이를 원하는 결과와 비교
- 평가 루프는 경로가 실행된 뒤에 수행
- 본 논문에서는 상태 공간을 환경에서 상세 지표로 사용 → 해당 지표들은 (0,1) 범위로 정규화
- 예를 들어 “첫번째 빙원에서 최대한 많은 시간을 보내기” 문제의 경우 성공은 단순히 다음과 같이 계산 → (첫번째 빙원에 있는 시간 스텝의 수) / (시간 스텝의 수)
Performance measurement
- 모델의 성능은 모델을 몇몇의 다른 문제에서 생성된 경로에 경로들에 대한 평가로 측정됨
- 점수는 [0, 1]의 범위로 정규화 되고 성공 지표로 사용
- 만약 모델이 생성된 경로에서 1의 점수를 받으면 모델은 해당 문제를 성공한 것이고 0의 점수를 받으면 실패한 것
3.2. Dataset Details
Overview
- 데이터셋은 700개 이상의 라벨링 된 미션으로 구성됨 → 5M 타임스텝 데이터
- 각각은 현재의 문제, 현재의 상태, 취한 행동으로 구성됨
- Atari 환경은 18개의 이산적인 행동으로 구성되며 게임 프레임들은 흑백으로 변환되고 리사이징 됨
- 표 1에서 몇가지 예시 문제들을 살펴볼 수 있으며 더 많은 예시들은 부록 참고

Collection
- 수백개의 문제들과 경로들은 직접 손으로 수집됨
- 경로들은 Atari-Gym의 유저 인터페이스를 사용하며 Frostbite를 키보드로 플레이하여 생성
- 모든 문제의 시작에서 사용자들은 그들이 수행하려고 하는 문제에 대한 프롬프트를 입력하고 상태, 행동, 문제를 기록 및 저장
Task categorizations
- 평가를 수행할 때 문제들은 문제 수행을 위한 제어의 정도에 따라 구분됨
- 쉬운 문제들: “움직이지 않기”, “첫번째 레벨에서 죽기”, “왼쪽에서 머무르기”와 같이 단순하고 개선된 시각적 인지나 에이전트의 제어를 요구하지 않음
- 중간 문제들: 조금 더 높은 단계의 인지가 필요하지만 어려운 문제만큼은 아님 → “최대한 1000점에 가까운 점수 얻기”, “레벨 2에 도달하기”, “두번째와 세번째 빙원 사이를 점프하기”와 같은 문제들로 구성
- 어려운 문제들: 개선된 제어를 요구 → “레벨 5에 도달하기”, “4번째 빙원에서 최대한 오랜 시간 보내기”와 같은 문제로 구성
- 위의 문제들은 RAM 점수 평가를 사용
4. Method
- 텍스트 조건부 Decision Transformer의 자세한 구조와 변형에 대해 살펴볼 것
- GPT-2 스타일의 causal transformer 사용 → 텍스트와 경로로 구성된 시퀀스를 모델링
4.1. Architecture
- Decision Transformer와 유사하게 본 논문의 기법은 토큰의 시퀀스를 경로로 모델링
- 모방 학습의 프레임워크에 이를 적용하며 return-to-go 토큰을 삭제하고 대신 텍스트 토큰을 사용
- 문제에 대한 단어들은 임베딩 테이블을 통해 인코딩 되었으며 상태와 행동은 각각 CNN과 MLP를 통해 인코딩 됨
- 모델에서 사용되는 일반적인 토큰의 시퀀스를 다음과 같음
- $\tau = (m_1, m_2, ..., m_n, s_1, a_1, s_2, a_2, ..., s_t, a_t)$
- 모델은 텍스트 토큰과 상태, 행동의 시퀀스로 프롬프팅 됨 → 입력들은 토큰과 되거나 모델을 통과시켜 사용
- 행동 $a_t$를 위한 행동 로짓은 상태 $s_t$로부터의 출력과 관련되어 있으며 causal transformer mask에 의해 $s_t$ 이전의 토큰들만 표시됨 (visible)
- 경로의 생성을 위해 예측된 행동 로짓을 샘플링하고 예측된 행동을 통해 환경의 스텝을 진행
- 경로의 마지막에 환경의 스코어 함수를 통해 성능을 평가 → 경로와 텍스트가 잘 align 되었는지 확인
- 또한 언어 입력에 대해 전처리 수행
- 소문자 변환, 문장 부호 삭제
- 단어들은 원핫 표현으로 변환되고 학습된 임베딩 테이블을 통해
- 알고리즘 1 참고

4.2. Training
- 일반적인 지도 학습 방식을 사용
- 문제와 경로의 쌍에 대한 랜덤 미니배치를 추출하고 이를 오프라인 데이터셋으로 샘플링
- 모델은 시퀀스에 대해 순방향 연산 (forward pass)을 수행하고 다음 행동에 대한 분포의 로짓을 출력
- 예측과 실제 행동 사이의 cross entropy를 최적화
- 수도코드는 알고리즘 1을 참고
4.3. Unsupervised Pretraining
- 비지도 사전학습을 수행하고 이에 대한 효과를 섹션 5.2 - 5.4에서 살펴볼 것
- 라벨링 되지 않은 경로 (텍스트 쌍을 사용하지 않음)를 데이터셋으로 부터 추출하여 학습
- 모델은 입력 상태와 행동만을 사용하고 지도 학습 과정과 동일한 방식을 사용
- 사전학습은 모든 문제에 대해 텍스트 정보만 제거한 상태에서 데이터를 추출 → 이후 모델은 특정 문제에 대해 파인튜닝 되고 평가됨 → 사전학습에 의한 표현 (representation) 학습의 효율성을 검증
5. Empirical Evaluations
5.1. Does the transformer architecture model the joint sequences well?
- 먼저 완전히 지도학습 세팅으로 학습한 Transformer 구조에 대한 평가 수행 → 그림 3 참고

- 모달리티 간의 어텐션을 제거한 MLP baseline과 성능 비교 → 텍스트 토큰은 사전학습 된 BERT 모델에 의해 처리되고 상태와 행동 토큰에 결합됨 (concatenated) → TDT의 인코더도 동일한 처리 수행
- 1의 컨텍스트 (K)를 가지는 MLP는 TDT와 동일한 수의 파라미터를 가지지만 컨텍스트 1의 MLP는 한 경우 빼고 모든 TDT 보다 성능이 좋지 않음
- 20의 컨텍스트를 가지는 MLP도 10의 컨텍스트 사이즈를 가지는 TDT 구조보다 좋지 못한 성능을 보임
- 1의 컨텍스트를 가지는 TDT는 MLP 베이스라인과 거의 유사한 구조를 가지지만 핵심적인 차이가 있음 → TDT 모델은 자체적인 텍스트 임베딩을 학습하고 다른 모달리티 간의 어텐션을 사용
- 그림 3을 통해 해당 실험의 결과를 2가지로 정리할 수 있음
- 단일 stream으로 텍스트와 상태 토큰을 평가하는 causal Transformer 구조는 사전에 인코딩 된 텍스트 토큰을 사용하는 결합 기반 (concatenation-based) 기법보다 더 좋은 성능을 보임
- Causal transformer에서 컨텍스트를 증가시키는 것이 더 강력한 성능을 이끌어냄 → 더 긴 시퀀스 모델이 더 강력한 모델
5.2. How effective is unsupervised pretraining for learning representations?
- TDT의 가장 매력적인 부분은 대규모의 라벨링 되지 않은 데이터로 사전 학습이 가능하고 이를 통해 언어를 기반으로 few-shot 행동이 가능하다는 점
- 비지도 사전학습 실험에서 모델은 라벨링 되지 않은 고정된 수의 문제들에 의해 behavior cloning을 통해 초기에 사전학습 됨
- 학습 과정 → 라벨링 된 문제와 동일한 corpus로부터 샘플링을 수행하지만 텍스트를 포함하지 않음
- 추론 과정 → 라벨링 된 데이터의 작은 데이터를 샘플링하고 평가 수행
- Zeroshot 학습의 예시
- “두번째와 세번째 빙원 사이를 앞뒤로 뛰어라”와 같은 문제를 풀 수 있으면 “첫번째와 두번째 빙원”, “첫번째와 세번째 빙원” 등에서 모두 적용 가능
- 모든 모델의 파라미터에 대해 파인튜닝 수행
- 먼저 비전 인코더의 transferring을 평가
- 더 나은 이미지 표현을 생성 → 비지도 탐험 이후 강화학습 정책을 파인튜닝 하기 위한 가장 공통적인 기법
- 결과는 그림 4 참고

- 전체 모델을 라벨링 되지 않은 transition 데이터로 사전학습 → 시각적 인코더에서 (텍스트 라벨이 없어도) 중요한 특징들 (features)을 학습할 수 있음
- 이런 시각적 인코더를 사용하는 경우 특정 문제에 대해 파인튜닝 했을 때 더 나은 성능을 보임 → 해당 개선은 사전학습 데이터가 많을수록 더 향상됨
5.3. Does sequential context improve pretraining performance?
- Transformer가 순차적 특성을 가지므로 컨텍스트의 길이가 어떻게 사전 학습에 영향을 미치는지 알 필요가 있음
- 이에 대한 평가를 위해 그림 4에서 살펴본 결과에 ****컨텍스트의 크기를 20 대신 1로 설정하여 TDT에 대한 ablation 수행
- 비전 인코더에 대한 transfer만 수행
- 결과 = 표 2와 그림 5에서 살펴볼 수 있음 → 큰 컨텍스트가 사전학습에서 큰 성능 향상을 이끔

5.4. Can we transfer the sequence model backbone?
- 이전 섹션에서는 사전 학습 단계에서 비전 인코더의 전이 (transferring)에 따른 성능을 살펴봄
- 이는 비지도 탐험 이후 강화학습 에이전트를 파인튜닝하는 표준 방법 → 탐험과 파인튜닝 사이에 정책과 가치에 대한 파라미터의 전이는 어려우므로
- 비지도 사전학습 단계의 과정을 반복하지만 학습된 행동과 입력의 순차적 통합 능력을 가진 Transformer의 백본에 대한 전이만을 수행
- 이에 대한 결과는 그림 6에서 살펴볼 수 있음
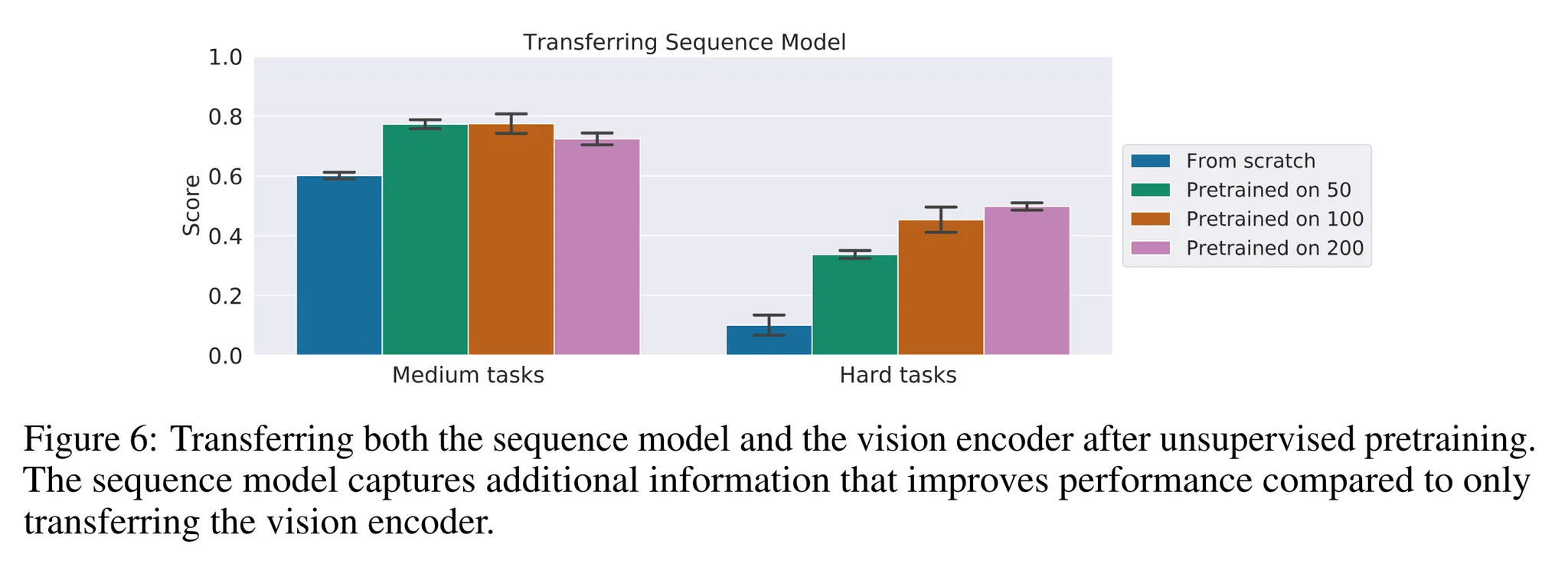
- 순차적 모델은 세부적인 문제에 적용할 수 있는 추가적인 정보를 통합할 수 있음
- 또한 시퀀스 모델을 전이하는 것은 비전 인코더만을 전이하는 것에 비해 거의 두배의 점수를 달성
- 학습된 순차적 모델을 전이하는 것은 강화학습 세팅에서 퓨샷 학습을 위한 강력한 기초를 제공
5.5. How does Text Decision Transformer scale with data?
- 이전 실험에서는 많은 양의 비지도 학습 데이터가 성능을 향상시키는 것을 확인
- 이번에는 10-700개의 라벨링 된 다량의 데이터로 모델을 학습
- 검증 손실함수는 그림 7에서 살펴볼 수 있음

- 낮은 검증 손실함수는 모델이 정확하게 행동을 예측했음을 의미 → 환경에서 더 높은 성공률을 달성
5.6. Qualitative examples
- 그림 8은 “두번째와 세번째 빙원 사이를 점프해라”라는 명령에 대한 그림들
- 실제 에이전트가 언급한 두개의 빙원 사이를 점프하는 것을 확인할 수 있음

6. Conclusion
- 새로운 벤치마크와 데이터셋 공개 → 텍스트 조건부 Frostbite
- Text Decision Transformer 제안 → 텍스트, 상태, 행동 토큰을 사용하여 동작하는 멀티모달 구조
- 비지도 사전학습을 통해 세부적인 문제에 대한 퓨샷 학습 성능 향상
- 코드와 데이터셋 공개
반응형



