반응형

0. Abstract
- 강화학습은 장기적인 (long-horizon) 문제나 목표가 희소한 (sparse) 환경에서는 수동으로 보상 설정을 하는 것의 어려움 때문에 학습이 잘 안됨
- 기존 기법들은 이를 해결하기 위해 내적 보상 (intrinsic reward)을 사용하지만 큰 상태와 행동 공간을 가지는 장기적인 의사 결정 문제에서는 의미있게 가이드하지 못함 → 목적성 있는 탐험을 수행하지 못함
- 본 논문에서는 멀티모달 모델 기반 강화학습을 제안 → Dreaming with Large Language Models (DLLM)
- 언어 모델로부터 제안된 힌트 하위 목표를 모델 롤아웃 (rollouts)에 통합하여 목표를 달성하고 어려운 문제를 해결할 수 있도록 도움을 제공
- 모델 롤아웃 동안 언어 모델이 제시한 힌트와 일치하는 샘플에 높은 내적 보상 제공 → DLLM은 에이전트가 더욱 의미있고 효율적인 탐험을 하도록 함
- 실험 수행 → 어렵고, 희소한 보상 환경에서 실험 수행 (HomeGrid, Crafter, Minecraft)
- 각 환경에 대해 27.7%, 21.1%, 9.9% 성능 향상
1. Introduction
- 강화학습은 에이전트가 원하는 행동을 수행하도록 하는 보상을 받을 때 효과적
- 하지만 적절한 보상 함수에 대한 수동 설정은 특히 복잡한 환경에서 큰 어려움을 발생시킴
- 장기간의, 희소한 보상 환경을 푸는 것을 강화학습이 오랫동안 목표로 한 것
- 기존의 강화학습 기법들은 위의 문제들을 해결하기 위해 새로움 (novelty), 놀라움 (surprise), 불확실성, 예측 에러와 같은 추가적인 목표에 대한 내적 보상을 사용
- 기존 내적 보상 기반 기법의 단점 → 에이전트의 목표에 대해 정말 가치있는 요소가 있는 환경에서는 이외의 추가적인 탐색은 무의미할 수 있음
- 최근 이를 해결하기 위해 LLM을 사용 → 언어 모델의 사전지식을 활용하여 의미있는 상태를 탐색
- 모델-프리적인 특성 때문에 언어 기반의 힌트와 환경의 동적 관계 사이의 근본적 관계를 알 수 없음 → 샘플 효율성을 향상시키기 위한 플래닝 기법이나 합성 데이터 생성을 활용하지 못함
- 이 문제의 해결을 위해 사람이 장기적인 문제를 효율적으로 푸는 방법에 영감을 받음
- 문제를 여러개의 하위 목표로 나누고 해당 목표들을 순차적으로 달성하기 위한 효과적인 경로를 계획함
- 이런 목표들은 종종 특정 행동이나 환경의 역학적인 요소와 관계가 있으며 정확한 자연어로 표현할 수 있음
- 예시: 마인크래프트 플레이어는 자연스럽게 “철 얻기”라는 행동과 이를 위한 사전 행동인 “철광석 찾기”와 “철광석 부수기”를 연결할 수 있음
- 멀티모달 모델 기반의 강화학습 기법 → LLM으로 부터 받은 언어 힌트 (i.e. 골)를 롤 아웃에 통합하여 어렵고 희소한 보상 문제에서 목표를 발견하고 달성하도록 함
- 그림 1에서 묘사된 것 처럼 DLLM의 월드 모델은 시각적 입력과 전이 (transition)에 대한 자연어의 문장 임베딩을 처리하여 이 둘을 예측하도록 학습본 논문에서는 Dreaming with Large Language Model (DLLM)을 제안

- 그리고 목표에 충분히 가깝게 예측된 임베딩에 대해 보상 제공
-
- DLLM은 동일한 문제에 대해서도 프롬프트에 따라 에이전트의 행동에 영향을 미칠 수 있고 이에 따라 다양한 에이전트의 행동을 유도할 수 있음
- 예시: 마인크래프트에서 에이전트가 철을 얻을 필요가 있을 때 바로 철 광석을 부수도록 유도할 수도 있고 더 나은 정책을 탐험하도록 할수도 있고 두 전략을 섞을 수도 있음
- DLLM은 동일한 문제에 대해서도 프롬프트에 따라 에이전트의 행동에 영향을 미칠 수 있고 이에 따라 다양한 에이전트의 행동을 유도할 수 있음
- 본 논문에서는 DLLM을 희소 보상 환경에서 검증 → HomeGrid, Crafter, Minecraft
- DLLM은 대부분의 최신 문제-중심 (task oriented) 기법과 탐험 중심 (exploration-oriented) 환경에서 좋은 성능을 보임
- 탐험에 있어 강인한 성능을 보였으며 굉장히 복잡한 시나리오에서 에이전트 학습을 수행
- HomeGrid, Crafter, Minecraft 각 환경에서 27.7%, 21.1%, 9.9%의 성능 향상을 보임
- 베이스라인 알고리즘: Dynalang, Achevement Distillation, Dreamer V3
- 또한 더욱 강력한 언어 모델을 사용하고 에이전트에 더 이해되는 언어 정보를 제공하면 더 좋은 성능을 보이는 것을 확인
- 본 논문의 contribution
- DLLM이라는 멀티모달 모델기반 강화학습 방식을 제안 → 인간의 자연어를 사용하여 환경의 역학 (Dynamics)을 설명하고, LLM의 힌트를 모델 롤아웃에 통합하여 에이전트의 탐색 및 목표 달성 능력 향상
- LLM에서 추출한 목표를 기반으로, 정책 학습을 가이드하기 위해 내적 보상을 자동으로 생성하는 메커니즘을 도입하여 의미 있는 내적 보상을 생성
- 다양한 환경에서 DLLM이 최근 공개된 강력한 베이스라인을 능가함을 입증하는 실험 결과 확인 → 에이전트의 탐색과 훈련을 효과적으로 가이드할 수 있음을 보임
2. Preliminaries
- POMDP (Partially Observable Markov Decision Process)를 고려 → $(S, A, O, \Omega, P, \gamma, R)$
- $s \in S$: 환경의 상태
- $a \in A$: 행동
- $o \in \Omega$는 $O(o|s,a)$로부터 얻어짐
- $P(s'|s,a)$는 환경의 역학을 나타냄
- $R, \gamma$는 각각 보상함수와 감가율을 나타냄
- 학습 동안 에이전트는 감가된 누적 보상을 최대화하기 위한 정책 $\pi$를 학습하는 것을 목표로 함
- $\max \mathbb{E}[\sum_{t=0}^\infty \gamma^t R(s_t, a_t )]$
- 두 세트의 자언어 문장 임베딩 정의
- 전이에 대한 문장 임베딩 세트 → $U$, 목표에 대한 문장 임베딩 세트 → $G$
- 각 $u \in U$는 이전 스텝과 현재 스텝에서 환경의 변화를 묘사하는 문장 임베딩
- 각 $g\in G$는 에이전트의 달성을 의도하는 목표의 문장 임베딩
- 목표 조건부 내적 보상 함수 $R_{int}(u|g)$ 정의
- DLLM 에이전트는 환경의 보상 $R$과 일치하는 방향으로 내적 보상 $R_{int}$를 최적화해야함
- 자연어로 제공되는 목표가 다양하며, 상식적이고, 문맥에 잘 맞을 때 $R_{int}$와 $R$을 함께 최대화하면 에이전트가 지역 최적점에 빠지지 않고 보상함수 $R$을 최대화 할 것으로 기대
3. Dreaming with LLMs
- 이번 섹션에서 살펴볼 것
- LLM으로 부터 가이드 정보 (목표)를 취득하는 방법
- 가이드 정보를 사용하여 장기 의사 결정을 다루기 위해 에이전트에게 보상을 제공하는 방법
3.1. Goal Generation by Prompting LLMs
- 목표에 대한 자연어 표현과 그것들의 벡터 임베딩을 생성하기 위해 SentenceBert와 GPT 모델 사용
- GPT의 경우 GPT-3.5-turbo-0315, GPT-4-32k-0315 모델 사용
- 먼저 현재 관측에 해당하는 정보를 자연어로 표현한 $o_l$을 취득
- $o_l$은 에이전트의 위치, 인벤토리 정보, 체력, 시야 등에 대한 정보를 포함할 수 있음
- 관측 캡셔너 (Observation Captioner)를 사용하여 $o_l$을 취득하며 ELLM 방법을 따름 (부록 C 참고)
- 그리고 다음의 정보들을 LLM에 제공하여 자연어 형태로 고정된 수의 목표 $g_{1:K}^l$를 받음
- $o_l$, 환경으로부터 받을 수 있는 자연어 출력 (e.g. HomeGrid의 문제 설명), 환경의 메커니즘에 대한 묘사,
- $K$는 하이퍼파라미터로 LLM에서 반환받을 목표의 수를 결정
- 목표 취득을 위해 2가지 접근방식 사용
- LLM이 임의 유형 (arbitrary type)의 목표 K개에 대한 응답을 생성하는 방식
- LLM이 특정 유형 (specified type)의 목표 K개에 대한 응답을 제공 (e.g. 어떤 방으로 들어가야 할지와 이를 위한 구체적 행동 결정)
- 두번째 접근의 경우 LLM의 응답을 표준화하고 LLM이 출력하는 목표가 복잡한 시나리오에서 문제 해결에 필요한 모든 측면을 포괄하는 것을 보장하기 위해 설계
3.2. Incorporating Decreased Intrinsic Rewards into Dreaming Process
- 전이 캡셔너는 관측과 다음 관측 사이의 역학의 언어적 설명 $u_l$을 제공 → 그리고 $u_l$은 벡터 임베딩 $u$로 임베딩 됨
- 주어진 sensory 표현 $x_0$, 전이의 언어 설명 임베딩 $u_0$, 목표들의 임베딩 $g_{1:K}$, 각 목표의 내적 보상 $i_{1:k}$에 대해 월드 모델과 액터는 상상된 잠재 상태 (latent states) $\hat{s}{1:T}$, 행동 $\hat{a}{1:T}$, 보상 $\hat{r}{1:T}$, 전이 $\hat{u}{1:T}$, 지속플래그 (continuation flags) $\hat{c}_{1:T}$의 시퀀스를 생성
- $T$는 모델 롤아웃의 전체 길이
- 전이들과 목표들 사이에 대한 코사인 유사도를 통해 매칭 스코어 $w$를 계산

- $M$은 유사도 임계값을 나타내는 하이퍼파라미터
- 이 과정에서 낮은 코사인 유사도는 무시하여 잘못된 가이드를 방지
- 또한 단일 롤아웃 과정 동안 동일한 목표에 대해 여러번 내적 보상이 할당되는 것을 피함 → 이는 에이전트가 단순한 행동을 반복하도록 할 수 있으며 복잡한 행동에 대한 탐험을 감소시킬 수 있음
- 이에 따라 특정 목표의 매칭 점수가 시퀀스 내에서 처음 임계값을 초과할 때 내적 보상을 할당
- 한 모델 롤아웃에서 $t$ 단계의 내적 보상을 다음과 같이 계산
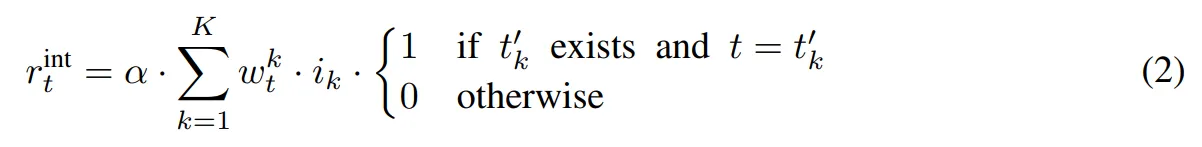
- $\alpha$는 내적 보상의 스케일을 조절하기 위한 하이퍼파라미터
- $t_k'$는 $w_t^k$가 1-T 범위 내에서 처음으로 $M$을 넘을때의 시간 스텝 $t$
- 한 모델 롤아웃에서 $t$ 단계의 내적 보상을 다음과 같이 계산
- 만약 목표의 보상이 상수이면 에이전트는 새로운 탐험을 하기보다 학습된 스킬을 반복하려고 함
- 이에 따라 RND를 사용하여 LLM으로 부터 내적보상을 생성 및 감소시킴 → 단순 작업을 반복하는 문제를 효과적으로 피할 수 있음
- 리플레이 버퍼에서 배치를 샘플링 한 이후 목표들의 문장 임베딩을 추출 → $g_{1:B, 1:L, 1:K}$
- $B$=배치사이즈, $L$=배치 길이
- 타겟 네트워크 $f: G \rightarrow \mathbb{R}$이 주어지고 예측 뉴럴 네트워크 $\hat{f}_{\theta}: G \rightarrow \mathbb{R}$이 예측 에러 계산
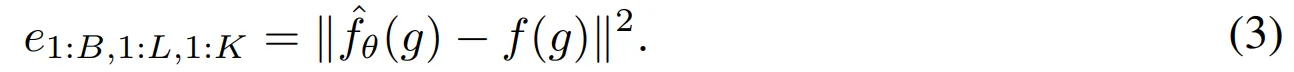
- 이후 예측 뉴럴 네트워크를 업데이트하고 보상의 표준편차의 실행 추정치 (running estimate)를 계산 후 내적 보상을 표준화
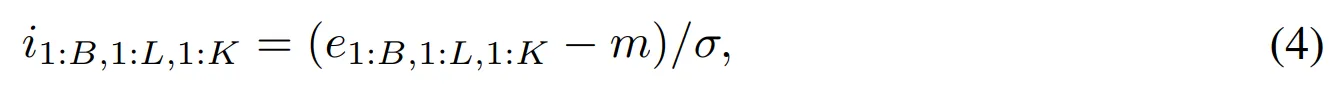
- $m, \sigma$는 내적 반환값의 평균과 표준편차에 대한 실행 추정치
3.3. World Model and Actor Critic Learning
- RSSM (Recurrent State-Space Model)을 이용하여 월드 모델을 구현
- 인코더는 sensory 입력 $x_t$ (e.g. 이미지나 언어)와 $u_t$를 맵핑하여 확률적 표현 $z_t$를 도출
- 그리고 $z_t$는 과거의 행동 $a_t$와 회귀 상태 $h_t$와 결합 된 후 “seq”로 표시하는 순차적 모델에 입력하고 $\hat{z}_{t+1}$를 예측
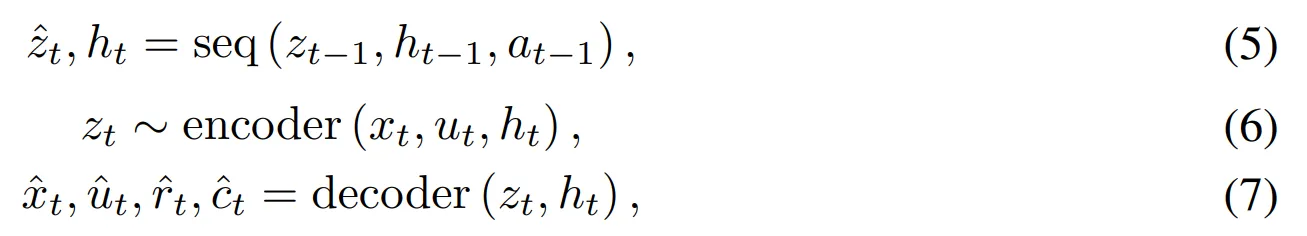
- $\hat{z}_t, \hat{x}_t, \hat{u}_t, \hat{r}_t, \hat{c}_t$는 확률적 표현, sensory 표현, 전이, 보상, 에피소드 지속 플래그에 대한 월드모델의 예측
- 인코더와 디코더는 이미지 입력에 대해서는 CNN (Convolutional Neural Network), 다른 저차원 입력에 대해서는 MLP (Multi Layer Perceptron)를 사용
- 이제 디코더와 시퀀스 모델로부터 멀티모달 표현을 얻은 후에는 다음과 같이 전체 월드 모델을 엔드-투-엔드 방식으로 학습

- $\beta_1 = 0.5, \beta_2 = 0.1$이며 모든 하위 손실함수들은 다음과 같음
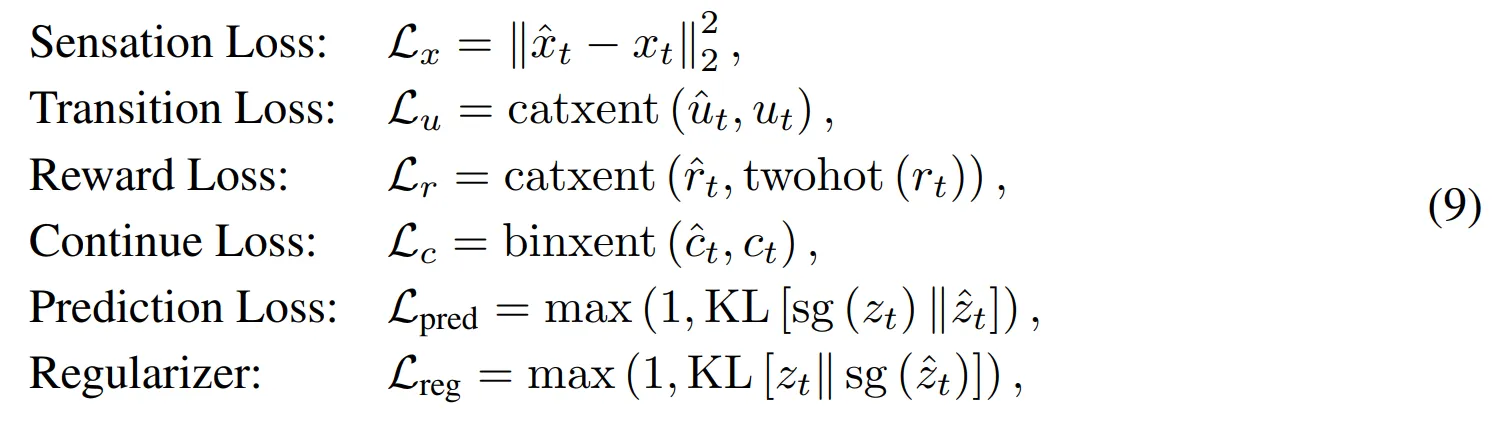
- $catxent$는 Categorical Cross Entropy 손실함수
- $binxent$는 Binary Cross Entropy 손실함수
- $sg$는 Stop gradient 연산
- $KL$은 Kulback-Leibler (KL) divergence
- $\beta_1 = 0.5, \beta_2 = 0.1$이며 모든 하위 손실함수들은 다음과 같음
- 정책 학습을 위해서는 액터-크리틱 구조를 사용
- 액터는 행동을 수행하고 환경에서 샘플을 수집
- 크리틱은 수행된 행동이 좋은지를 평가
- 모델의 상태 $s_t=concat(z_t, h_t)$
- 액터와 크리틱의 연산

- 액터와 크리틱의 네트워크는 단순한 MLP
- 액터는 내적 보상을 포함한 누적 반환값을 최대화하는 것을 목표로 함

- 예측의 범위 $T$를 벗어나는 내적 보상은 접근 불가 → 0으로 설정
- Bootstrapped $\lambda$-returns는 다음과 같이 작성할 수 있음
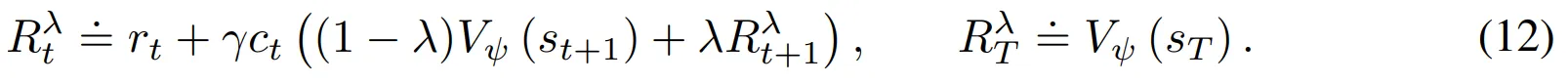
- 액터와 크리틱은 다음과 같은 손실함수들로 학습
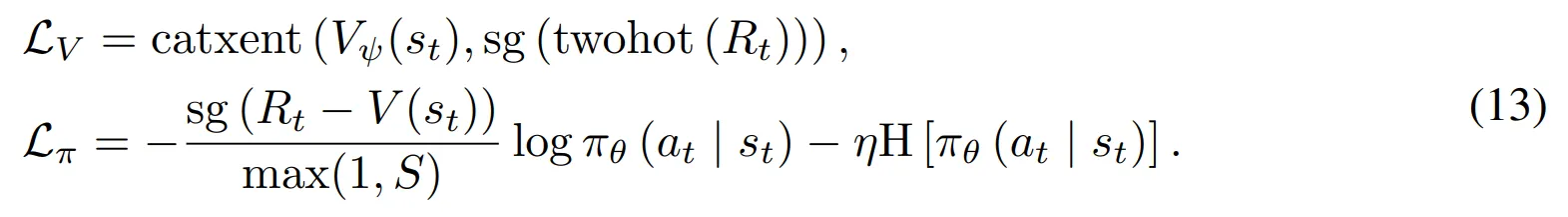
- S는 $R_t$의 5th 와 95th percentile 사이의 지수 이동 평균
- DLLM의 수도 코드는 부록 B.2에서 살펴볼 수 있음

4. Experiments
- 목표는 다음의 주장을 확증하는 것! → DLLM이 플래닝 과정 동안 LLM으로부터의 가이드를 통해 성능 개선 달성
- 이에 따라 실험들을 통해 다음의 가설들을 실행
- (H1) 적절한 프롬프팅을 통해 DLLM은 복잡한 환경을 이해하고 다중 문제 환경에서 에이전트를 돕기 뒤한 정확한 지시 생성
- (H2) DLLM은 적절하고 새로운 힌트를 생성하는 LLM의 생성 능력을 강화하여 어려운 환경에서 에이전트의 탐험을 도움
- (H3) DLLM은 높은 차원의 플래닝을 요구하는 매우 복잡하고 큰 규모의, 실제와 가까운 환경에서 에이전트의 탐험과 학습을 가속화
- (H4) DLLM은 강력한 LLM과 결합하거나 추가적인 언어 정보를 받을 때 더욱 강력해질 수 있음
- 베이스라인
- 실험에서 자연어 정보를 포함하므로 ELLM과 Dynalang을 베이스라인으로 사용
- 환경
- HomeGrid, Crafter, MineRL을 기반으로 하는 MineCraft 환경 사용
- 1인칭에서 3인칭, 2D에서 3D, 다양한 문제의 종류와 단계를 다룸
- 캡셔너와 언어 인코딩
- 관측 캡셔너와 전이 캡셔너를 사용
- 전이 캡션은 에이전트의 예측 학습을 위해 리플레이 버퍼에 저장됨
- 관측 캡션은 LLM을 위해 적절한 정보를 제공
- 언어 인코딩을 위해서 SentenceBert all-MiniLM-L6-v2 사용 → 모든 자연어 입력을 임베딩으로 변환
- 생성된 목표의 품질
- 환경에서 실시간 상호작용하는 동안 LLM이 생성한 목표의 품질을 평가 → 새로움 (novelty), 정확성 (correctness), 컨텍스트 민감성 (context sensitivity), 상식 민감성 (common-sense sensitivity)으로 평가
- 캐싱 (cache)
- 각 실험을 캐싱하여 쿼리를 효율적으로 재사용하도록 함 → 시간과 비용 감소
4.1. HomeGrid
Environment Description
- HomeGrid는 그리드월드로 구성된 다중 문제 강화학습 환경
- 에이전트는 부분적인 관측과 언어 힌트 (문제에 대한 설명)를 얻음
- 맵의 크기는 10x10
- 각 스텝마다 캡셔너는 관측과 전이에 대한 캡셔닝 수행
- 환경이 제공하는 언어 힌트에 대해 다양한 수준의 정보를 제공 (표1 참고) → 가설 H4를 증명

Query prompts, LLM choices, and Goals Generated
- 각 쿼리 프롬프트는 에이전트의 현재 관측에 대한 캡션과 두가지 종류의 목표를 LLM에게 생성하라고 요청
- 2 종류의 목표: “어디로 갈지”, “무엇을 할지”
- HomeGrid에 대해서는 GPT-4를 기반 LLM으로 사용
Performance
- 전반적인 결과는 그림 2에서 묘사됨
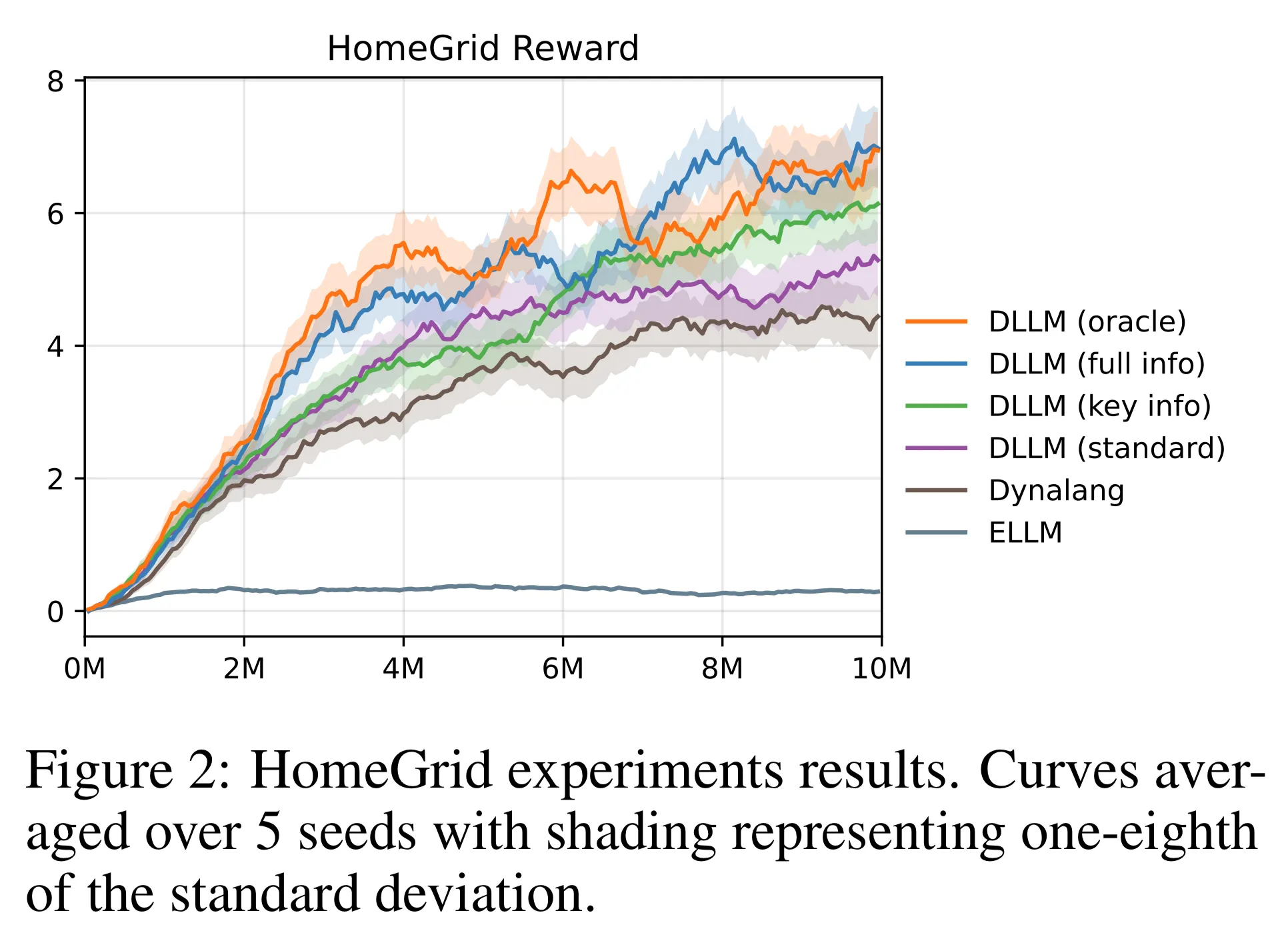
- ELLM은 HomeGrid에서 실패
- 본 논문의 기법은 표준 세팅에서 동일한 정보를 사용한 베이스라인 알고리즘들의 성능을 뛰어 넘음 → H1, H3을 검증하는 증거
- 또한 Key info, Full info, Oracle 세팅에 대해 정보가 많아질수록 성능 향상을 확인할 수 있음 → 가설 H4을 입증
4.2. Crafter
Environment Description
- 그리드월드, top-down뷰, 이산행동 환경
- 2D 마인크래프트와 유사함 → 환경이 점진적으로 생성되며 부분적으로 관측 가능한 환경, 플레이어는 다양한 물건을 수집하거나 제작
- 플레이어의 목표는 모든 업적 트리를 (achievement tree)를 해제하는 것 → 22개의 업적으로 구성
- 맵에는 플레이어를 해칠 수 있는 요소들이 존재 (e.g. 좀비, 해골, …)
- 사용자는 무기를 만들거나 장애물을 구축해서 살아남아야함
Extra baselines
- 3개의 추가적인 베이스라인 종류 사용
- LLM 기반 기법: SPRING, Reflexion, ReAct, GPT-4
- 모델 기반 RL 기법: Dreamer V3
- 모델 프리 기법: Achievement Distillation, PPO, Rainbow
- 인간 전문가와 랜덤 정책도 참고용으로 사용
Query prompts, LLM choices, and Goals Generated
- 각 쿼리 프롬프트는 에이전트의 현재 관측을 설명하는 캡션을 포함
- LLM에 5개의 목표 생성을 요청
- 평가는 2개의 유명한 LLM을 사용 → GPT-3.5, GPT-4
- 해당 평가를 통해 더 강인한 LLM이 에이전트의 성능 향상에 기여함을 확인 → 가설 H4 검증
- 생성된 목표의 품질은 부록 D.2에서 확인 가능
Performance


- DLLM은 1M과 5M 스텝에서 모든 베이스라인 알고리즘의 성능을 능가
- 그림 3(a)와 표 2 참고
- 그림 3(b)는 LLM이 중간이나 높은 난이도의 문제를 잘 푸는 것을 보임 → 예시: 나무 곡괭이/칼을 만들기, 철 모으기
- 덜 어려운 문제에서도 안정적인 난이도를 보임
- 5M 스텝에서 DLLM의 성능은 언어 기반 알고리즘인 SPRING의 성능을 능가
- 위 결과들은 가설 H2, H3를 입증
- 또한 Crafter 환경의 모든 실험에서 DLLM (w/ GPT-4)가 DLLM (w/ GPT-3.5)보다 더욱 강인한 성능을 보임 → 강력한 LLM의 도움이 더 좋은 성능을 가져옴 (가설 H4 입증)
- 다양한 Ablation Study 수행
- 내적 보상의 스케일 조절 → 부록 E.2 참고
- 내적보상 감소시키지 않기 → 부록 E.3 참고
- 랜덤 골 사용 → 부록 E.4 참고
- 반복된 내적보상 허용 → 부록 E.5 참고
4.3. Minecraft
Environment description
- 몇몇의 강화학습 환경은 마인크래프트를 기반으로 구현 (e.g. MineRL)
- Minecraft Diamond는 MineRL 기반의 도전적인 환경 → 주요 목표는 다이아몬드를 얻는 것
- 이를 위해 플레이어는 새로운 아이템을 만들기 위한 자원을 수집하고 생존해야하며 기술적인 진행 요소들을 해제해야함
- 최종적으로는 36000 스텝 안에 다이아몬드를 얻는 것이 목표!
- 캡셔너가 자연어 형태로 관측과 전이에 대한 설명을 제공
- 각 마일스톤이 달성될 때마다 a+1의 보상 제공 (환경 세팅은 Dreamer V3의 것을 그대로 사용)
- 마일스톤 - 통나무, 판자, 막대기, 작업대, 나무 곡괭이, 자갈, 돌 곡괭이, 철 광석, 용광로, 철 주괴, 철 곡괭이, 다이아몬드 수집 또는 제작,
Extra baselines
- DLLM을 다른 유명한 모델기반, 모델 프리 알고리즘과 성능 비교
- DreamerV3, IMPALA, R2D2, Rainbow, PPO, ELLM, Dynalang
Query prompts, LLM choices, and Goals Generated
- GPT에 쿼리를 보낼 때 플레이어의 상태, 인벤토리, 장비 등을 포함하여 제공하고 GPT에게 5개의 골을 제공하도록 요청
- GPT-4를 DLLM 실험의 언어 모델로 사용 → 20 스텝마다 GPT에게 쿼리를 보냄
Performance
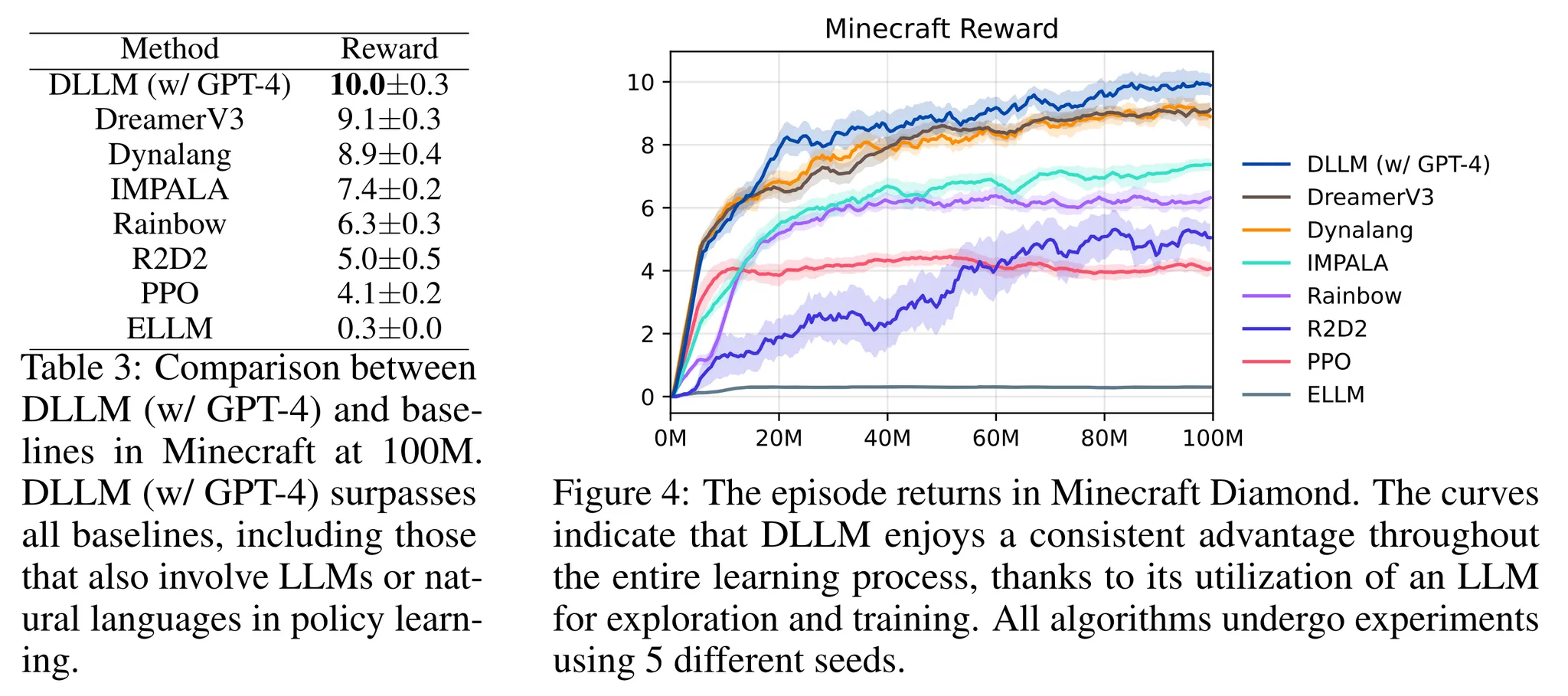
- 결과는 표3과 그림4 참고
- 학습 초반 → DLLM이 높은 데이터 효율성을 보임 → 기본 기술들을 빠르게 습득
- 이후 단계에서도 DLLM이 여전히 뛰어난 성능을 보임 → 탐험 이후의 학습 단계에서도 LLM의 가이드가 실용적이면서 합리적임을 알 수 있음
- DLLM이 탐험을 효율적으로 가이드하고 LLM의 도움으로 복잡한 환경에서 학습을 수행하는 것은 가설 H3를 입증하는 것!!
5. Conclusion and Discussion
- DLLM을 제안 → LLM이 제공하는 힌트 (목표)로부터 가이드를 제공받은 멀티모달 모델 기반 강화학습 기법 → 모델 롤아웃을 통해 내적 보상 생성
- DLLM은 희소 보상을 가지는 다수의 어려운 환경에서 최근 공개된 강력한 베이스라인들의 성능을 뛰어넘음
- DLLM은 환경의 언어 정보들을 효과적으로 사용하고 언어 모델의 품질 개선에 따라 성능이 향상됨을 보임
Limitations
- DLLM은 언어 모델이 제공하는 가이드에 의존 → LLM 출력의 내재적 불안정성에 영상을 받음
- 이는 DLLM 성능의 안정성에 위협이 될 수 있음
- 합리적이지 않은 목표로 에이전트를 유도하며 나쁜 시도를 하게 할 수 있음 → 이런 잘못 가이드된 행동을 수정하는 데에는 시간이 필요
반응형



