반응형

0. Abstract
- 사람과 협력하는 것은 사람의 개별적인 강점, 약점, 선호에 빠르게 적응할 수 있는 능력을 요구
- 불행하게도 Self-Play (SP)나 Population Play (PP)와 같은 대부분의 표준 멀티 에이전트 강화학습 기법들은 학습한 파트너에 대해 과적합 되기 때문에 사람에게 일반화하기 어려움
- 이에 대한 대안으로 사람의 데이터를 수집한 뒤 Behavioral Cloning을 통해 사람 모델을 학습하고 해당 모델을 통해 “human aware” 에이전트를 학습할 수 있음 → Behavioral Cloning Play (BCP)
- 이런 접근은 새로운 사람 공동 플레이어에 대한 일반화를 향상시키지만 번거로우면서도 많은 비용을 요구하는 많은 양의 사람 데이터 수집이 먼저 수행되어야 함
- 이에 따라 본 논문에서는 사람의 데이터 없이 사람과 잘 협업하는 에이전트를 학습할 수 있는 방법에 대해 소개
- 문제의 핵심은 다양한 학습 파트너의 세트를 생성하는 것!
- 본 논문에서는 놀라울만큼 단순한 접근이 매우 효율적이라는 것을 발견
- 본 논문에서 제안하는 기법인 Fictitious Co-Play (FCP)는 self-play 에이전트들의 집단과 학습 동안 취득한 그것들의 체크포인트들에 대해 가장 잘 반응하는 에이전트 파트너를 학습
- 본 논문의 실험은 최근 사람과의 협력을 위한 도전적인 문제로 제안되고 있는 환경에서 수행 → 두 플레이어가 협업하는 요리 시뮬레이터
- FCP 에이전트가 SP, PP, BCP에 비해 새로운 에이전트나 사람 파트너와 짝이 되어 문제를 풀 때 더 높은 점수를 기록하는 것을 확인
- 또한 사람들도 다른 베이스라인들보다 FCP 에이전트와 파트너가 되는 것에 강한 주관적 선호를 보임
1. Introduction

- 새로운 파트너와 협력하는 에이전트를 생성하는 것은 인공지능에서 오랫동안 도전적인 문제였음
- 많은 성공적인 기법들은 사람 모델을 사용했고 최근 많은 경쟁적인 도메인에서는 self-play를 통해 사람 데이터 없이도 모델 프리 강화학습을 통해 사람 수준에 도달하는 에이전트를 학습
- 여기서 질문! → 사람의 데이터를 사용하지 않은 모델 프리 강화학습 에이전트가 새로운 사람과 협력할 수 있을까?
- 모든 에이전트가 공통의 목표를 향해 작업하고 동일한 보상을 받은 공동 보상 게임 (common-payoff game)에서 이에 대한 답을 찾아볼 것
- Self-play (SP)
- 에이전트가 자신의 복제와 대결하며 게임을 반복적으로 플레이 → 새로운 플레이어에 대해 일반화된 에이전트를 만들 수 없음
- 에이전트가 자신들과만 협업하도록 학습되었으므로 다르게 행동하는 새로운 파트너에 대해 취약하거나 고집스럽게 협업하도록 학습될 수 있음
- Population Play (PP)
- 서로서로 상호작용하는 에이전트의 집합을 학습
- PP는 경쟁적인 팀게임에서 사람과 협업이 가능한 에이전트를 생성할 수 있지만 공동 보상 세팅에서는 새로운 사람에 대한 강인한 파트너를 만드는 것은 실패
- 본 논문의 접근은 강인한 에이전트 협력자를 만들기 위해서는 다양한 학습 파트너에게 노출시키는 것이 중요하다는 직관에서 시작!
- 놀라울만큼 단순한 전략을 통해 충분한 다양성을 효과적으로 생성
- 서로 다른 랜덤 시드로 초기화 된 인공신경망들로 구성된 N개의 self-play 에이전트들을 학습
- 학습동안 주기적으로 그들의 전략을 나타내는 특정 시간 시점에 체크포인트를 저장
- 그리고 완전히 학습된 에이전트들과 그것들의 과거 체크포인트들에 가장 잘 대응하는 에이전트 파트너를 학습
- 다른 체크포인트는 다양한 숙련도 시뮬레이션하고 다른 랜덤 시드는 서로 다른 방식으로 대칭(symmetries)을 깨는 것을 시뮬레이션
- 본 논문에서는 이런 에이전트 학습 과정을 Fictitious Co-Play (FCP)라고 부름
- 본 논문의 contribution은 다음과 같이 정리
- 사람과 zero-shot coordination 이 가능한 에이전트를 학습하는 FCP 제안
- FCP 에이전트가 SP, PP, BCP에 비해 zero-shot coordination에서 더 잘 일반화 되는 것을 보임
- 행동에 대한 분석과 참가자의 피드백을 통해 사람-에이전트간 상호작용에 대한 정밀한 연구방법을 제안
- FCP가 문제의 점수와 사람 파트너의 선호 측면 모두에서 SOTA 기법인 BCP의 성능을 능가하는 것을 보임
2. Methods
2.1. Fictitious Co-Play (FCP)

- 환경적인 변화 (i.e. domain randomization)이나 학습 파트너의 이질성과 같은 다양한 학습 조건이 에이전트를 더욱 강인하게 만들어줌
- 본 논문에서는 공동 보상 게임에서 사람에 대한 강인한 파트너 에이전트를 학습하는 것이 목표
- 새로운 파트너와 협업을 하기 위한 중요한 도전 과제
- 대칭 (symmetries)을 다루는 것이 중요함
- 예를 들어 두 에이전트 A, B가 서로 마주보고 있을 때 에이전트 A가 왼쪽으로, B가 오른쪽으로 가거나 그 반대로 행동할 수도 있음
- 두가지 모두 유효한 해결방법이지만 사람이 특별히 한쪽을 선호하는 경우 좋은 에이전트 파트너는 이런 규칙 사이에서 적응하며 전환할 수 있음
- 다양한 기술 레벨을 다루는 것이 중요함
- 좋은 에이전트 파트너는 굉장히 능력있는 파트너와 여전히 학습중인 파트너 모두를 잘 도울 수 있어야 함
- 대칭 (symmetries)을 다루는 것이 중요함
- FCP는 단순한 두 단계의 접근으로 에이전트를 학습하여 이 두가지 도전과제를 해결 (그림 2, 오른쪽 참고)
- 첫번째 단계
- self-play를 통해 N개의 파트너를 학습
- 이런 파트너들은 독립적으로 학습 → 대칭을 깨기 위한 임의의 규칙으로 도달할 수 있음 (원문: they can arrive at different arbitrary conventions for breaking symmetries)
- 이런 집합들이 다른 기술 레벨을 나타낼 수 있도록 학습 중에 각 self-play 파트너에 대해 다수의 체크포인트를 사용
- 최종 체크포인트는 완전히 학습된 “숙련된” 파트너를 나타냄
- 파트너 당 다수의 체크포인트를 사용하여 추가적인 학습 비용 없이 기술 측면에서 추가적인 다양성을 만들어 낼 수 있음
- 두번째 단계
- FCP 에이전트가 첫번째 단계에서 만들어진 다양한 파트너의 집합들에 대해 가장 잘 반응하는 에이전트가 되도록 학습
- 파트너의 파라미터는 고정하여 파트너가 FCP에 적응하는 것이 아니라 FCP가 파트너에게 적응하며 학습하도록 하는 것이 중요
- 이 경우 FCP 에이전트는 사람 파트너의 리드를 따르도록 학습되고 다양한 범위의 전략과 기술에 대해 일반화 될 수 있음
- 첫번째 단계
2.2. Baselines and Ablations
- FCP를 다음과 같은 세가지 베이스라인 학습 기법들과 비교 → 각각은 학습 파트너의 세트만 다르고 강화학습 알고리즘이나 구조는 모든 에이전트가 동일함
- Self-play (SP): 에이전트가 자신들과의 상호작용만을 통해 학습
- Population-play (PP): 에이전트의 집합이 랜덤한 쌍으로 상호 학습
- Behavioral Cloning play (BCP): 사람의 BC 모델을 사용하여 에이전트 학습
- 또한 FCP의 세가지 변형에 대해서 검증을 수행
- $FCP_{-T}$: 학습 중 과거 체크포인트들을 포함하는 것의 중요성 테스트 → 수렴된 체크포인트들만 사용하여 에이전트 학습
- $FCP_{+A}$: 다양한 파트너 집합을 통한 다양성의 이점을 테스트 → SP 파트너들을 랜덤 시드로만 다양화하는 것이 아니라 구조까지 다양화
- $FCP_{-T, +A}$: 위의 두 변형을 합친 것
2.3. Environment
- 사람-에이전트 상호작용에서 zero-shot coordination을 수행하는 이전 연구들처럼 본 논문은 Overcooked 환경을 사용 (그림 3 참고)
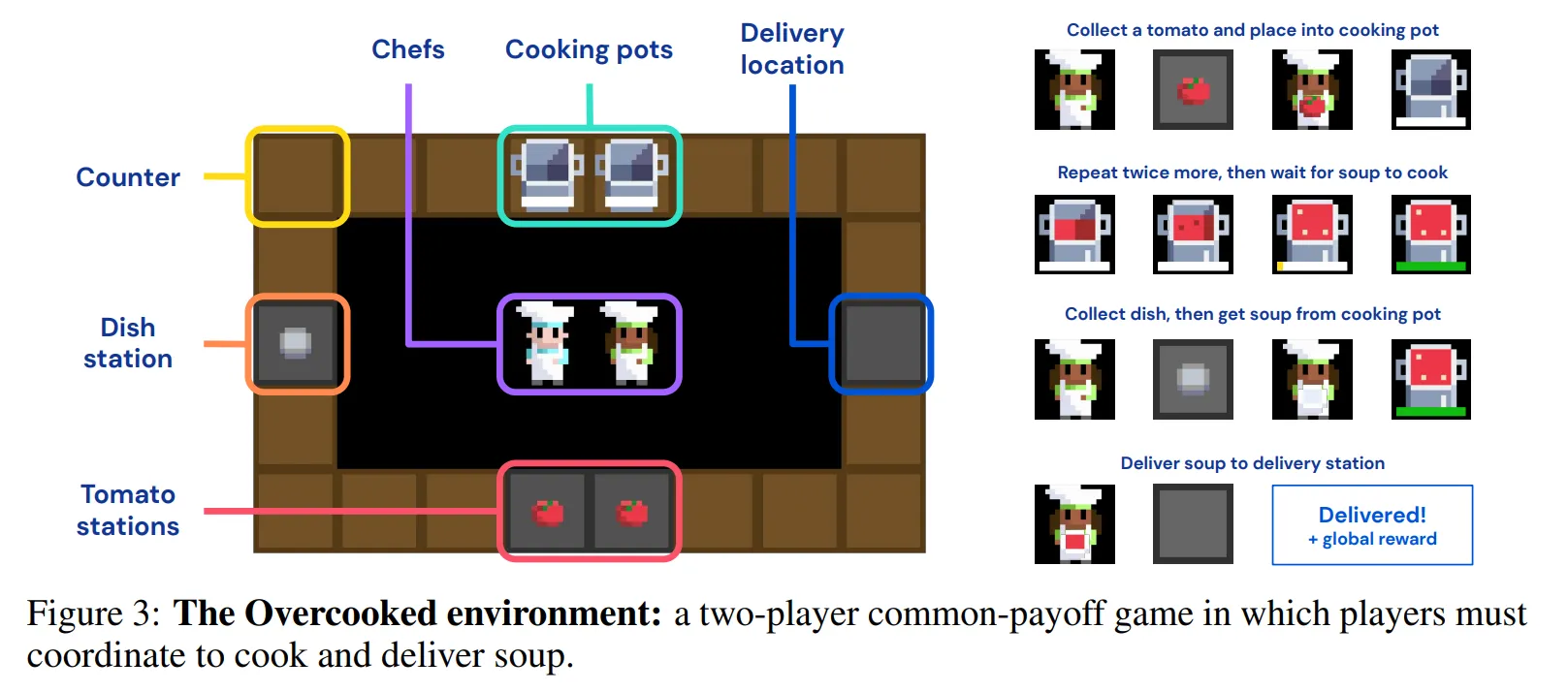
- Overcooked 환경 설명
- 플레이어들은 그리드월드 주방의 요리사
- 에피소드 동안 최대한 많은 조리된 토마토 스프 접시를 배달하는 문제를 풀어야 함
- 두 플레이어는 모두 순차적인 행동들을 수행해야함: 토마토 수집, 조리 냄비에 토마토 넣기, 토마토가 스프가 되도록 조리, 접시 수집, 스프 담기, 최종 배달
- 성공적으로 토마토 스프를 배달하는 경우 두 플레이어는 동일한 보상을 받음
- 효율적으로 문제를 풀기 위해 요구되는 사항
- 플레이어들이 주방을 효율적으로 돌아다니면서 정확한 순서에 맞게 객체들과 상호작용 해야함
- 파트너의 행동을 인지하고 파트너와 협력해야함
- 이에 따라 본 환경은 이동과 전략적 협동 측면에서 도전적인 부분이 있음
- 각 플레이어는 월드에 대한 본인 중심의 RGB 시점을 관측하며 6개의 행동을 취할 수 있음: 정지, {위, 아래, 왼쪽, 오른쪽} 이동, 상호작용 → 상호작용은 에이전트가 마주한 칸에 기반하여 다양한 상호작용 수행 (e.g. 카운터에 토마토 올려놓기)
2.4. Implementation Details
- 강화학습 에이전트로는 V-MPO 알고리즘에 ResNet + LSTM 구조 사용
- 병렬적으로 환경을 실행하며 분산 학습 수행 → 각 환경은 집합으로부터 두 에이전트를 샘플링하여 매 에피소드마다 플레이
- PP와 FCP는 집합 사이즈 N=32로 학습 수행하며 균일하게 샘플링 수행
- FCP는 각 에이전트에 대해 3개의 체크포인트 사용
- 초기 (i.e. 낮은 숙련도를 가진 에이전트)
- 학습 종료 (i.e. 완전히 학습된 숙련된 에이전트)
- 학습 중간 → 최종 보상의 50% 정도를 달성한 에이전트 (i.e. 평균적인 숙련도를 가진 에이전트)
- $FCP_{+A}, FCP_{-T+A}$의 파트너 학습을 위해 구조를 다양화
- 메모리 → LSTM을 사용할지 말지
- 정책과 가치 네트워크의 너비 → i.e. 16 vs. 256
- 4 조합으로 8 에이전트를 학습 → 총 집합의 크기를 N=32
- Behavioral cloning 학습을 위해 오픈소스 Acme를 사용하여 사람의 플레이 데이터를 기반으로 정책 학습
- 1200 스텝 길이의 5개의 사람-사람 경로 수집 → 총 60k의 환경 스텝
- 해당 데이터를 두 BC 에이전트 학습을 위해 반으로 나눔
- BCP 에이전트의 파트너 학습을 위해 사용
- 에이전트-에이전트 평가를 위한 “human proxy” 파트너
3. Zero-shot Coordination with Agents
3.1. Evaluation Method: Collaborative Evaluation with Agent Partners

- 논 논문에서 주요하게 고려하는 요소 → 새로운 사람 파트너에 대해 일반화될 수 있는지
- Behavioral cloning을 위해 사람-사람 협업 데이터를 취득하는 것은 높은 비용을 요구하며 이는 검증에 대해서도 마찬가지
- 이에 따라 먼저 사람 대신 에이전트 파트너에 대해 일반화하는 것을 평가
- 아래와 같은 세 종류의 에이전트 사용
- 사람 데이터로 학습된 BC 모델 ($H_{proxy}$) ⇒ 사람의 대리자에 대한 일반화 의도
- 다양한 시드, 구조, 학습 시간을 가지는 self-play 에이전트 (N=32 파트너, $FCP_{+A}$ 에이전트로 학습) → 다양하고 숙련된 집단에 대한 일반화 의도
- 랜덤하게 초기화된 에이전트 → 숙련되지 않은 파트너에 대한 일반화 의도
- 그림 4의 다양한 환경 구조에서 검증 수행, 에이전트-파트너 쌍에 대해 10 에피소드 검증
3.2. Results
Finding 1: FCP significantly outperforms all baselines

- 위에서 언급한 세 에이전트들과 협업하는 상황에서 FCP 에이전트와 베이스라인들의 성능을 비교
- 그림 5에서 볼 수 있듯이 FCP가 모든 에이전트와의 협업에서 베이스라인들에 비해 좋은 성능을 보임
- 특히 $H_{proxy}$와의 협업에서 BCP는 이미 이런 모델과 학습을 했고 FCP는 그렇지 않음에도 불구하고 BCP보다 좋은 성능을 보임
- 미숙하게 행동하는 랜덤하게 초기화된 파트너와의 협업의 경우 FCP가 다른 베이스라인들에 비해 더욱 큰 차이를 보임 → 이를 통해 다른 학습 기법들이 숙련되지 않은 플레이어와 협업했을 때 잘 동작하지 못할 것이라고 예상할 수 있음
Finding 2: Training with past checkpoints is the most beneficial variation for performance

- 표 1: 체크포인트 ($T$)와 구조 ($A$)를 변경하면서 그림 5와 동일한 파트너들을 사용하여 ablation 진행
- $FCP$와 $FCP_{-T}$ 열을 비교 → 과거 체크포인트들을 학습시 제외하는 경우 눈에 띄게 성능이 감소
- $FCP$와 $FCP_{+A}$ 열을 비교 → 구조적 변화를 학습 집단에 추가하는 것은 과거 체크포인트들을 사용하는 경우 성능 향상을 가져오지 않음
- 하지만 $FCP_{-T}$와 $FCP_{-T,+A}$ 열을 비교하는 경우 과거 체크포인트 없이 학습하면 구조적 변화가 성능 향상을 가져옴
4. Zero-shot Coordination with Humans
- 본 논문의 목표는 새로운 사람 파트너와 협업할 수 있는 에이전트의 개발 → 이제 사람 파트너와 협력적인 플레이를 하는 부분에서 FCP 에이전트와 다른 베이스라인의 성능 검증
4.1. Evaluation Method: Collaborative Evaluation with Human Participants

- 사람 파트너에 대해 FCP의 성능 일반화를 효율적으로 평가하기 위해 참가자 모집
- N=114, 37.7% 여성, 59.6% 남성, 1.8% nonbinary, 나이의 중앙값은 25-34살
- 사람과의 협업 평가 실험 과정
- 먼저 사람은 게임 설명을 읽고 짧은 튜토리얼 에피소드를 수행
- 사람은 랜덤한 순서의 에이전트 파트너와 kitchen 구조에서 20 에피소드 동안 게임을 수행하며 각 에피소드는 T=300 스텝 동안 지속
- 매 두번째 에피소드 이후 참가자들은 해당 에피소드들에서 파트너에 대한 선호를 평가
- 통계적 분석은 repeated-measures analysis of variance (ANOVA) 기법 사용
4.2. Results
Finding 1: FCP coordinates best with humans, achieving the highest score across maps

- 에이전트-에이전트 플레이에서 관측된 FCP의 강력한 성능이 사람-에이전트 협력으로 일반화 된 것을 확인할 수 있음: FCP-사람 팀이 다른 에이전트-사람 팀의 성능을 뛰어넘는 것을 확인할 수 있음 → 그림 7(a)
- 또한 그림 7(b)를 통해서 사람과 협업시에도 과거 체크포인트를 사용하여 학습한 에이전트를 사용하는 것이 좋다는 것을 알 수 있음
Finding 2: Participants prefer FCP over all baselines
- 참가자의 주관적인 파트너 선호에 있어서도 FCP의 강력한 협력 성능을 확인할 수 있음
- 참가자들은 BCP를 포함한 모든 다른 에이전트들에 비해 FCP 에이전트를 선호하는 것을 확인할 수 있음 → 그림 7(c)
- 또한 사람-BCP와 사람-PP는 배달 완료 수에 대해서 차이가 없지만 사람은 PP보다 BCP와의 협업을 선호하는 것을 확인할 수 있음
4.3. Exploratory Behavioral Analysis

- 어떻게 사람-에이전트 점수와 선호가 발생하였는지 더 잘 이해하기 위한 분석 → 각 사람과 에이전트 플레이어의 행동 경로를 분석
Finding 1: FCP exhibits the best movement coordination with humans
- 우선 각 플레이어가 한 에피소드 동안 얼마나 움직이는지 확인 → 그림 8(a)
- 높은 비율로 이동하는 것이 더 적은 충돌, 파트너와 더 좋은 협업을 암시
- 위의 결과로 두가지를 확인할 수 있음
- 사람은 거의 움직이지 않음 → 이는 일반적인 훈련 방법(예: SP, PP)에 대한 분포를 벗어나지만 BCP 및 FCP에 대한 훈련 분포에서는 확인할 수 있음
- FCP는 Forced를 제외하고는 모든 구조에서 가장 많이 움직임 → 파트너와의 이동 전략에 대한 더 나은 협력을 암시
Finding 2: FCP’s preference over cooking pots align best with that of humans
- 그림 8(b)를 통해 두개의 요리 냄비 (cooking pot)가 있는 구조에서 특정 요리 냄비를 선호하는지 확인
- 이를 위해 각 사용자에 의해 각 냄비가 사용되는 횟수의 차이를 계산 → 높은 값은 하나의 냄비를 선호하는 것을 의미하고 낮은 값은 두개의 냄비를 더 비슷하게 선호하는 것을 의미
- FCP 열에서 본 논문의 에이전트가 거의 사람과 비슷한 선호도를 보이는 것을 확인 (FCP=0.11, 사람=0.15)
- 이는 본 논문의 에이전트가 하나의 냄비를 다른 냄비에 비해 55.5% 선호하는 것을 의미 (i.e. 0.11 point 차이)
- 이와 대조적으로 다른 에이전트들은 하나의 냄비를 선호 → 이는 좋지 못한 전략을 두개의 냄비를 사용하는 사람의 행동에 일반화하기 어렵고 결과적으로 나쁜 성능을 유발
반응형
'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| EUREKA: Human-level Reward Design via Coding Large Language Models (2) | 2024.11.20 |
|---|---|
| Training Diffusion Models with Reinforcement Learning (2) | 2024.11.16 |
| Deep Reinforcement Learning from Human Preference (3) | 2024.11.10 |
| CLUTR: Curriculum Learning via Unsupervised Task Representation Learning (0) | 2024.11.09 |
| BYOL-Explore: Exploration by Bootstrapped Prediction (4) | 2024.11.03 |



