반응형

- Paper: https://arxiv.org/pdf/2305.13301.pdf
- 프로젝트 페이지: https://rl-diffusion.github.io/
0. Abstract
- Diffusion 모델은 log-likelihood objective로 근사되어 학습한 유연한 생성 모델
- 하지만 대부분의 diffusion 모델 사용시 likelihood가 고려되지 않고 인간이 인지하는 이미지의 품질이나 drug effectiveness (?) 같은 다운스트림 목표와 관련됨
- 본 논문은 강화학습을 통해 diffusion 모델을 직접적으로 최적화하는 방법에 대해 설명
- 노이즈 제거 과정을 다수의 단계에 대한 의사 결정 문제로 취급 → policy gradient 알고리즘을 사용할 수 있도록 함
- 본 논문에서 제안하는 기법 -> Denoising Diffusion Policy Optimization (DDPO)
- DDPO로 수행할 수 있는 태스크
- DDPO는 텍스트-to-이미지 diffusion 모델에 적용되어 프롬프트로 표현하기 어려운 이미지의 압축성 (compressibility), 미적인 (aesthetic) 품질 등의 목표에 적용될 수 있음
- 마지막으로 DDPO는 비전-언어 모델의 피드백을 통해 추가적인 데이터 수집이나 사람의 라벨링 없이 프롬프트와 이미지의 일치성을 향상시킬 수 있음
1. Introduction
- Diffusion 확률 모델 → 연속적인 도메인의 생성 모델링 기법으로 복잡하고 고차원의 분포를 나타내는데 유연성을 보임 → 이미지, 비디오 합성, 약이나 소재 디자인, 연속적인 제어 등에 적용
- Diffusion 모델의 핵심 아이디어 → 순차적인 노이즈 제거 과정을 적용하여 단순한 사전 분포를 반복적으로 타겟 분포로 변환
- 해당 과정은 maximum likelihood 예측 문제에서 영향을 받았지만 목적함수는 모델 log-likelihood에 대한 variational lower bound로 도출됨
- 그러나 대부분의 diffusion 모델의 경우 직접적으로 likelihood와 관련이 있지 않고 인간이 인지하는 이미지 품질이나 drug effectiveness 같은 downstream 목적함수와 관련됨
- 본 논문에서는 데이터 분포를 일치시키는 것이 아닌 위에서 설명한 목표를 직접적으로 만족하는 diffusion 모델 학습에 대한 고려
- Diffusion 모델에서 정확한 likelihood의 계산이 어려우므로 많은 기존의 강화학습 알고리즘을 적용하기 어려움
- 대신에 본 논문에서는 프레임 denoising 문제를 다수의 의사결정 과정으로 제안 → 전체 denoising 과정에 의해 유도된 근사된 likelihood 대한 각 denoising 과정에서 정확한 likelihood 사용
- Policy Gradient 알고리즘을 적용하여 diffusion 모델 최적화 → Denoising Diffusion Policy Optimization (DDPO)
- 본 논문의 알고리즘은 사전학습된 텍스트-to-이미지 diffusion 모델의 파인튜닝에 사용
- 이미지 압축, 미적인 품질 등의 문제에 적용
- 하지만 이런 문제를 풀기 위해서는 대부분 많은 양의 사람이 라벨링 한 보상이 필요
- 이에 따라 본 논문에서는 Vision-Language model (VLM)의 피드백을 라벨로 사용 → RLAIF 파인튜닝과 유사한 기법을 사용
- 본 논문의 contribution
- DDPO의 개념적인 동기에 대해 설명
- VLM을 사용하여 text-to-image를 위한 다양한 보상함수를 제안하는 방법에 대해 설명
- Reward-weighted likelihood와 비교하여 DDPO의 효율성을 입증
- 파인튜닝 과정의 결과에 대한 일반화와 과잉 최적화 (overoptimization) 효과에 대해 연구
2. Preliminaries
2.1. Diffusion Models
- Conditional diffusion probabilistic models
- 순차적인 denoising의 결과로 컨텍스트 $c$를 조건으로 하는 데이터 $x_0$에 대한 분포를 나타냄
- Denoising 과정은 데이터에 노이즈를 반복적으로 추가하는 Markovian forward process $q(x_t | x_{t-1})$의 역방향으로 학습
- 이런 forward process의 역과정은 모든 $t \in \{0, 1, ..., T\}$에 대한 forward process의 posterior mean predictor $\mu_{\theta} (x_t, t, c)$를 다음과 같은 단순한 목적함수를 통해 학습하여 수행
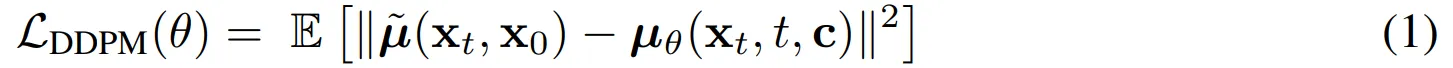
- $\tilde{\mu}$는 $x_0, x_t$의 가중화된 평균
- 해당 목적함수는 모델 log-likelihood에 대한 variational lower bound를 최대화하는 것으로 정의될 수 있음
- Diffusion 모델로부터의 샘플링
- $x_T \sim \mathcal{N}(0,I)$ 샘플링에서 시작하고 역과정 $p_{\theta}(x_{t-1}|x_t, c)$를 사용하여 경로 $\{x_T, x_{T-1}, ..., x_0\}$를 생성하며 샘플 $x_0$로 종료
- 가장 대중적인 역 과정은 predictor $\mu_{\theta}$ 뿐 아니라 샘플러의 선택에 의존 → 가장 대중적인 샘플러는 isotropic Gaussian reverse process (with a fixed timestep-dependent variance)

2.2. Markov Decision Processes and Reinforcement Learning
- Markov Decision Process (MDP)는 순차적인 결정 문제를 수식화 한 것
- $(\mathcal{S}, \mathcal{A}, \rho_0, P, R)$로 정의
- $\mathcal{S}$: 상태 공간, $\mathcal{A}$: 행동 공간, $\rho_0$: 초기 상태의 분포, $P$: transition kernel, $R$: 보상함수
- 각 시간 스텝 $t$마다 에이전트는 상태 $s_t \in \mathcal{S}$를 관측하고 행동 $a_t \in \mathcal{A}$를 취하며 보상 $R(s_t, a_t)$를 받고 새로운 상태 $s_{t+1} \sim P(\cdot|s_t, a_t)$로 이동, 에이전트는 정책 $\pi (a|s)$에 따라 행동
- $(\mathcal{S}, \mathcal{A}, \rho_0, P, R)$로 정의
- 에이전트가 MDP에 따라 행동하면 경로 (trajectory)를 생성 → 상태와 행동의 시퀀스 $\tau=(s_0, a_0, s_1, a_1, ..., s_T, a_T)$
- 강화학습은 에이전트가 목적함수 $\mathcal{J}_{RL}(\pi)$를 최대화하는 것을 목표로 함 → 정책으로부터 샘플링 된 경로의 기대 누적 보상
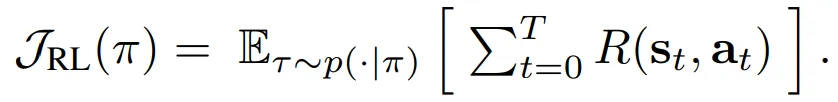
3. Reinforcement Learning Training of Diffusion Models
- 어떻게 강화학습 알고리즘을 diffusion 모델 학습에 사용했는지 알아볼 것
3.1. Problem Statement
- 사전 학습되었거나 랜덤하게 초기화 된 기존의 diffusion 모델 사용을 가정
- 만약 고정된 샘플러를 선택하는 경우 diffusion 모델은 샘플 분포 $p$를 유도
- Denoising diffusion RL의 목적함수는 샘플과 컨텍스트로 정의된 보상 $r$을 최대화하는 것

3.2. Reward-Weighted Regression
- 일반적인 diffusion 모델 학습에 대해 최소한의 변경만을 통해 $\mathcal{J}{DDRL}$을 최적화하기 위해 denoising objective $\mathcal{L}{DDPM}$ (식 1)을 사용
- Lee et al. 은 diffusion 모델을 위한 이 과정을 단일 단계 버전으로 설명했지만 일반적으로 이 과정은 여러 단계의 샘플링과 학습에 대해 수행될 수 있으며 이는 단순한 RL 기법과 연결될 수 있음 → 이 기법은 Reward-Weighted Regression (RWR)이라고 명명
- 일반적인 가중 기법은 nonnegativity를 보장하기 위해 exponentiated 보상을 사용

- $\beta$는 inverse temperature이며 $Z$는 normalization 상수
- 본 논문에서는 binary weight를 사용한 더 단순화된 기법 적용

- $C$는 보상의 threshold로 어떤 샘플을 학습에 사용할지 결정
- Sparse weights의 장점 → 모델의 모든 샘플을 유지할 필요가 없음
- 강화학습의 측면에서 생각했을 때 RWR 과정은 다음과 같은 단일 스텝 MDP와 대응됨

- 즉, $\mathcal{J}{DDRL}(\theta)$를 최적화하는 것은 MDP에서 $\mathcal{J}{RL}(\pi)$를 최대화하는 것과 동일
- $w_{RWR}$로 maximum likelihood 목적함수를 weighting하는 것은 정책에 대한 KL divergence constraint에 따라 $\mathcal{J}_{RL}(\pi)$를 근사적으로 최적화
- 그러나 $\mathcal{L}_{DDPM}$은 정확한 maximum likelihood 목적함수가 아니고 reweighted variational bound로부터 얻어짐
- 그러므로 RWR 알고리즘은 $\mathcal{L}{DDPM}$에 적용되어 $\mathcal{J}{DDRL}$을 최적화 → 두 단계의 근사
- 이에 따라 해당 기법은 우리에게 시작점을 제공하지만 복잡한 목표에 대해서는 성능이 저하될 수 있음
3.3. Denoising Diffusion Policy Optimization
- RWR은 denoising 과정의 순차적인 특성을 무시하기 때문에 maximum likelihood 목적함수를 근사 → 오직 최종 샘플 $x_0$만 사용
- 만약 샘플러가 고정되면 denoising 과정은 multi-step MDP로 재구성 될 수 있음 → 직접적으로 policy gradient estimator를 사용하여 $\mathcal{J}_{DDRL}$을 최적화 할 수 있음
- 이를 이용해 Denoising Diffusion Policy Optimization (DDPO)의 두가지 변형 버전을 제안
Denoising as a multi-step MDP
- 반복적인 denoising 과정을 다음과 같은 MDP로 맵핑
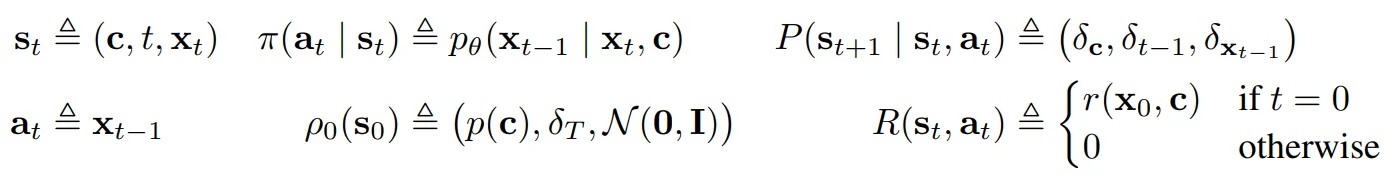
- $\delta_y$는 y에서만 0이 아닌 밀도를 가지는 Dirac delta 분포
- 경로는 T 시간 스텝으로 구성되어있으며 P는 종료 상태로 유도
- 각 경로의 누적 보상은 $r(x_0, c)$와 동일하므로 $\mathcal{J}{DDRL}(\theta)$를 최대화하는 것은 MDP에서 $\mathcal{J}{RL}(\pi)$를 최대화하는 것과 동일
- 해당 수식의 이점
- 식 2와 같이 파라미터화된 일반적인 샘플러를 사용하면 전체 denoising 과정에 의해 유도된 복잡한 분포와 반대로 정책 $\pi$가 isotropic Gaussian이 됨
- 이런 단순화는 diffusion 모델 파라미터에 대해 action likelihood와 이런 likelihood들의 기울기에 대한 정확한 평가를 가능하게 함
Policy gradient estimation
- Likelihood와 likelihood의 기울기에 접근할 수 있게 되면서 policy gradient $\nabla_{\theta}\mathcal{J}_{DDRL}$의 Monte Carlo 추정이 가능해짐
- DDPO는 샘플링을 통해 경로 $\{x_T, x_{T-1}, ..., x_0\}$에 대한 수집을 하고 $\mathcal{J}_{DDRL}$에 대한 gradient ascent로 파라미터를 업데이트
- DDPO에는 다음과 같은 2가지 변형이 있음
- $DDPO_{SF}$
- score function policy gradient estimator 사용 → likelihood ratio 기법 혹은 REINFORCE로 알려진 기법

- 기대값은 현재 정책 $p_{\theta}$에 의해 생성된 denoising 경로에 의해 도출
- score function policy gradient estimator 사용 → likelihood ratio 기법 혹은 REINFORCE로 알려진 기법
- $DDPO_{IS}$
- 위의 estimator는 unbiased 되어있지만 현재 정책으로부터 얻은 데이터만 사용하여 기울기를 추정해야하므로 데이터 수집 과정 당 오직 한스텝의 최적화만 가능함
- 다수의 스텝에 대한 최적화를 수행하기 위해서 본 논문에서는 importance sampling estimator 사용

- $\theta_{old}$는 데이터 수집에 사용한 파라미터이고 기대값은 해당 정책 $p_{\theta_{old}}$에 의해 생성된 경로에 의해 도출
- 이 estimator는 만약 $p_{\theta}$가 $p_{\theta_{old}}$와 너무 멀어지면 부정확해질 수 있음 → 이에 따라 trust region을 사용하여 업데이트 사이즈를 제한
- 본 논문에서는 importance weights를 clipping하는 trust region을 구현 = Proximal Polity Optimization (PPO)
- $DDPO_{SF}$
4. Reward Functions for Text-to-Image Diffusion
- text-to-image diffusion에서 본 기법에 대한 평가 수행
- 보상함수의 선택은 실제적인 RL의 적용을 위해 가장 중요한 결정 요소 중 하나 → 이번 섹션에서는 이 텍스트-to-이미지 diffusion 모델을 위한 보상함수의 선택에 대해 설명
4.1. Compressibility and Incompressibility
- 이미지의 경우 파일 사이즈로 라벨링이 되어있는 경우는 거의 없으므로 프롬프트를 통해서 원하는 파일 사이즈를 구체화하는 것이 불가능
- 이에 따라 파일사이즈를 기반으로 하는 보상함수로 실험 진행 → 파일 사이즈의 경우 계산이 쉬우면서도 기존의 likelihood maximization과 프롬프트 엔지니어링으로 제어할 수 없는 요소
- Diffusion 모델의 이미지 해상도는 512x512로 고정
- 파일 사이즈에 대해 2가지 실험 수행
- 압축성 (Compressibility): JPEG 압축 이후에 이미지 파일 사이즈 최소화
- 비압축성 (Incompressibility): 파일 사이즈 최대화
4.2. Aesthetic Quality
- 미적인 품질을 기반으로 하는 문제 정의 → LAION aesthetics predictor을 사용 (176,000개의 사람이 평가한 점수 사용)
- 예측기는 CLIP embedding을 기반으로 선형 모델로 구현되었으며 1-10 점으로 평가 (높은 점수 = 높은 예술성)
- 예측기는 사람의 판단을 기반으로 학습했으므로 Reinforcement Learning from Human Feedback (RLHF)로 간주될 수 있음
4.3. Automated Prompt-Alignment with Vision-Language Model
- 학습을 위한 보상 함수의 일반적인 목적은 프롬프트-이미지에 대한 일치도
- 그러나 프롬프트에 대한 일치도를 보상으로 구체화하는 것은 어려움! → 기존에는 이를 위해 대규모의 사람 라벨링이 필요했음
- 본 논문에서는 RLAIF의 접근에서 영감을 받아 VLM이 사람의 라벨링을 대체하도록 함
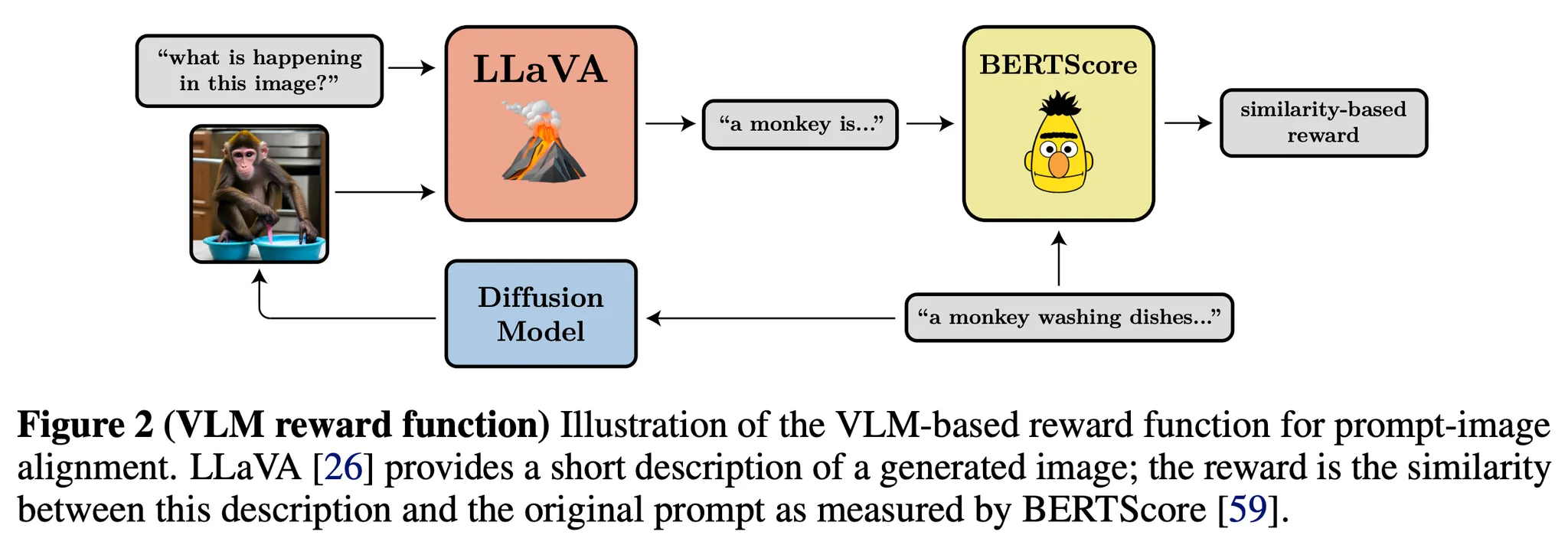
- LLaVA 모델을 사용 → SOTA VLM이며 이미지에 대해 설명을 수행하는 모델
- 파인튜닝 보상은 BERTScore recall 지표를 사용 → 의미적 유사도 (semantic similarity) 사용
- 그림 2를 보면 단순한 하나의 질문을 제공 “what is happening in this image?”
- 이는 일반적인 프롬프트-이미지 일치도를 위해 사용하지만, 특정한 문제에서 더 복잡하거나 정의하기 어려운 보상함수를 구체화해야하는 경우 다른 질문을 사용할수도 있음
5. Experimental Evaluation
- 실험의 목적: 사용자가 정의한 목표를 잘 수행하도록 diffusion 모델을 파인튜닝하는 RL 알고리즘의 효율성을 검증하는 것
- 이에 따라 다음의 질문들을 검증하는 것에 집중
- DDPO의 변형들과 RWR의 비교
- VLM이 수동으로 명시하기 어려운 보상을 잘 최적화할 수 있는가?
- RL 파인튜닝이 파인튜닝 동안 본적 없는 프롬프트에 대해서도 잘 일반화 될 수 있는가?
- RL 파인튜닝이 보상의 과잉 최적화를 유발하는가?
5.1. Algorithm Comparison


- 모든 기법에 대해 압축성, 비압축성, 미적 품질 문제를 평가
- Stable Diffusion v1.4를 기반 모델로 사용
- 압축성과 비압축성 프롬프트의 경우 ImageNet-1000의 모든 398 종류의 동물에 대해 균일하게 샘플링
- 미적 품질 프롬프트의 경우 더 작은 45 종의 동물에 대해 균일하게 샘플링
- 정성적으로는 그림 3에서 볼 수 있듯이 DDPO가 보상함수에 대한 정의만 주고 추가적인 데이터 수정 없이 효과적으로 사전학습 모델에 적용된 것을 확인할 수 있음
- 각 보상을 최적화하기 위해 취한 전략
- LAION을 통해 예측된 미적 품질을 최대화하기 위해 DDPO는 자연스러운 이미지를 생성하는 모델을 예술적인 선화를 생성하는 모델로 변경
- 압축성을 최대화하기 위해서 DDPO는 배경을 제거하고 Gaussian blur를 적용
- 비압축성을 최대화하기 위해서 DDPO는 JPEG 압축 알고리즘이 인코딩하기 어려운 요소들을 추가 (ex. 높은 주기의 노이즈, sharp edge, 특정 요소를 수 반복)
- 그림 4에서는 정량적인 평가를 수행
- 취득한 보상에 대한 그래프
- DDPO가 확실히 RWR에 비해 모든 문제에서 좋은 성능을 보임
- 노이즈 제거 과정을 MDP로 수식화하고 직접적으로 policy gradient를 추정하는 것이 likelihood에 대한 reward-weighted lower bound를 최적화하는 것 보다 효율적이라는 것을 보임
- DDPO 중에서는 중요도 샘플링 예측기 (Importance sampling estimator)가 점수 함수 예측기 (score function estimator)보다 조금 더 좋은 성능을 보임 → 최적화 스텝의 수가 늘어났기 때문!
- RWR 기법들은 성능이 유사함, 이에 따라 sparse weighting scheme이 단순함과 요구되는 자원이 적으므로 선호됨
5.2. Automated Prompt Alignment

- DDPO에 VLM를 결합한 평가 방법에 대한 검증 → 추가적인 사람의 라벨 없이 사전 학습 모델에 대해 자동적으로 이미지-프롬프트 일치도를 향상시킬 수 있음
- $DDPO_{IS}$를 통해 실험 수행
- 프롬프트는 다음과 같은 형식으로 설정 → “a(n) [animal] [activity]” (예시: an ant playing chess)
- 동물은 45 종류의 동물 중 하나를 선택했고 활동은 “riding a bike”, “playing chess”, “washing dishes” 중 하나 선택
- 그림 5 (왼쪽)를 보면 파인튜닝의 과정을 정성적으로 살펴볼 수 있음
- 학습이 진행되는 동안 샘플이 프롬프트를 더욱 신뢰도 있게 묘사
- 또한 오른쪽 그래프를 통해 정량적인 평가 결과도 살펴볼 수 있음
- 평균 BERTScore를 통해 보았을 때 학습을 통해 품질의 차이가 발생하는 것을 확인할 수 있음
- 특히 특정 프롬프트 (ex. a dolphin riding a bike)의 경우는 기본 모델에서는 성공률이 0이었지만 보상 신호가 없음에도 성능에 큰 향상이 있었음
- 거의 모든 샘플이 파인튜닝 동안에 만화 같아지거나 예술적인 형태로 바뀌는 것을 확인할 수 있고 이는 직접적으로 최적화되지 않음
- 이에 대한 가정은 예를 들면 곰이 설거지를 하는 실제같은 이미지를 찾기는 매우 어렵고 이런 식의 이미지는 대부분 어린이 동화책 삽화 등으로 나오는 경우가 많으므로 프롬프트의 내용을 만족시키기 위해서 샘플의 스타일이 바뀌는 것으로 추정
5.3. Generalization

- 대형 언어 모델에 대한 RL 파인튜닝은 흥미로운 일반화 특성을 보임 → 예를 들면 거의 영어로만 파인튜닝을 한 경우에도 다른 언어에 대한 능력도 함께 향상됨
- 그림 6을 보면 diffusion 모델에서도 비슷한 일반화가 적용되는 것을 알 수 있음 → DDPO 파인튜닝 모델의 샘플이 파인튜닝 때 본적 없는 프롬프트에도 대응됨
- 학습 분포 바깥의 동물을 사용하거나 동물이 아닌 일상생활의 물체에 대해서도 적용 가능
5.4. Overoptimization

- 보상함수에 대한 파인튜닝은 보상 과잉 최적화나 exploitation을 유도하는 경우가 관측됨 → 모델이 높은 보상을 달성하도록 학습되다 보니 사전학습된 분포와 너무 멀어지도록 이동
- 본 논문의 세팅도 유사한 결과 발생 → 그림 7을 보면 보상 exploitation의 두가지 사례를 살펴볼 수 있음
- 비압축성에 대한 최적화의 경우 모델이 결과적으로 의미있는 내용의 결과물을 만드는 것을 멈추고 고주파의 노이즈를 만들어냄
- 이와 유사하게 VLM 보상 방식이 타이포그래피 공격에 취약하다는 것을 관측 → “n마리 동물”의 형태를 가지는 프롬프트에 대한 일치도를 최적화할 때 DDPO는 지정된 특정 숫자와 유사한 텍스트를 생성하는 대신 VLM의 결함을 악용 (원문: DDPO exploited deficiencies in the VLM by instead generating text loosely resembling the specified number)
- 아직은 이런 과잉 최적화를 막는 일반적인 목적의 기법이 없으므로 이는 중요한 future work
6. Discussion and Limitations
- 본 논문에서는 강화학습 기반의 프레임워크로 diffusion 모델의 노이즈를 제거하는 학습을 수행하여 직접적으로 다양한 보상 함수에 대해 최적화하는 기법을 제안
- 반복적인 노이즈 제거 과정을 멀티 스텝 의사 결정 문제로 치환하고 diffusion 모델의 학습에 매우 효과적인 policy gradient 알고리즘 설계
- DDPO는 프롬프트를 통해 구체화하기 어려운 문제에 대해 효율적인 최적화를 수행 (ex. 이미지 압축성)
- 자동적으로 보상을 제공하기 위해 생성된 이미지에 대한 VLM의 피드백을 사용하는 기법 제안
- 다수의 프롬프트를 사용한 평가를 고려했지만 본 실험에서 이미지의 전체 범위는 제한됨 (e.g. 동물이 특정 활동을 수행)
- 미래에는 VLM에 대한 질문이나 프롬프트 분포에 대한 다양화를 수행할 것
- RL 파인튜닝 diffusion 모델의 과잉 최적화에 대한 경험적인 증거를 제공하였지만 이에 대한 분석이나 이런 과잉 최적화를 해결할만한 기법에 대한 것은 future work로 남김
- 이런 강화학습을 통한 최적화를 기반으로 대형 생성 모델이 단순히 데이터의 분포만 일치시키는 것이 아니라 유저가 명시한 목표를 효과적으로 달성하는 것을 기대
반응형
'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| Guiding Pretraining in Reinforcement Learning with Large Language Models (1) | 2024.11.21 |
|---|---|
| EUREKA: Human-level Reward Design via Coding Large Language Models (2) | 2024.11.20 |
| Collaborating with Humans without Human Data (8) | 2024.11.15 |
| Deep Reinforcement Learning from Human Preference (3) | 2024.11.10 |
| CLUTR: Curriculum Learning via Unsupervised Task Representation Learning (0) | 2024.11.09 |



