
- Paper: https://arxiv.org/pdf/2206.08332.pdf
- Blog: https://www.deepmind.com/blog/byol-explore-exploration-with-bootstrapped-prediction
0. Abstract
- BYOL-Explore 알고리즘 제안 → 시각적으로 복잡한 환경에서 curiosity-driven exploration을 위한 컨셉적으로 간단하면서도 일반적인 접근 방법
- 추가적인 objective 없이 latent space에서 하나의 예측 loss로 world representation, world dynamics, exploration policy를 모두 한꺼번에 학습
- BYOL-Explore의 효율성을 검증하는 환경 → DM-HARD-8
- 특징: partially-observable, continuous action, hard exploration, visually-rich 3D env.
- 해당 환경에서 순수하게 extrinsic 보상에 대한 augmenting과 BYOL-Explore의 intrinsic 보상만으로 대부분의 문제를 풀어냄
- 반면 기존의 기법들의 경우 사람의 데모 데이터가 있어야만 약간의 성능을 보였음
- Atari에서도 다른 에이전트들에 비해 훨씬 단순한 디자인을 사용했음에도 불구하고 가장 탐험이 어려운 10개의 환경에서 superhuman performance 달성
1. Introduction
- 탐험 (Exploration)은 강화학습에서 필수적인 요소, 특히 extrinsic 보상이 sparse하거나 도달하기 어려운 경우 더욱 탐험이 중요해짐
- 많은 환경에서 에이전트가 환경의 모든 것을 탐험하는 것은 실용적이지 못함 → 그렇다면 에이전트가 환경의 어떤 부분이 탐험하기에 흥미로운지 어떻게 결정할 수 있을까?
- 이를 위한 하나의 패러다임 → curiosity-driven exploration
- 이는 다음의 두가지로 구성
- world model → world에 대한 몇몇 정보들을 예측하도록 학습하는 모델
- intrinsic reward → world model의 예측과 실제 경험의 차이를 사용
- 강화학습 에이전트는 intrinsic 보상을 최적화하여 에이전트 스스로 world model이 부정확하거나 불완전하게 예측하는 상태로 유도하고 world model이 발전할 수 있는 새로운 경로를 생성
- 즉 world model의 특성은 exploration policy의 품질에 영향을 미침 → exploration policy를 통해 world model 스스로를 학습하기 위한 새로운 데이터를 수집
- 이에 따라 world model의 학습과 exploratory policy의 학습은 두개의 분리된 문제로 생각하지 않고 하나의 결합된 문제로 다루고 푸는 것이 중요
- 본 논문은 BYOL-Explore 기법을 제안
- Curiosity-driven 탐험 알고리즘 → 컨셉적으로 단순하고 일반적이면서도 좋은 성능을 보임
- 하나의 self-supervised prediction loss를 통해 world model의 representation과 curiosity-driven policy를 학습
- 본 논문의 기법은 Bootstrap Your Own Latent (BYOL) 기법을 기반으로 함
- latent-predictive self-supervised 기법으로 자기 스스로의 latent representation의 예전 copy를 예측하는 기법
- Bootstrapping 기법은 이미 컴퓨터 비전, 그래프 representation 학습, 강화학습의 representation 학습 등에서 성공적으로 적용
- 그러나 기존 강화학습에서 사용한 bootstrapping 기법은 world-model의 representation learning에만 주로 집중
- 반면 BYOL-Explore는 한 단계 더 나아가서 변하기 쉬운 world model을 학습할 뿐 아니라 world model의 loss로 exploration을 수행하도록 학습할 수 있음
- 성능 검증
- BYOL-Explore는 DM-HARD-8 환경에서 학습
- 8개의 복잡한 1인칭 시점의 3D task, sparse reward 환경
- 해당 task들은 최종 목적지에 도달하기 위해서 효율적인 탐험을 요구하고 보상을 받기 위해서는 정확하게 단계를 완료해야하며 순차적으로 환경의 물리적인 요소들과 상호작용해야함 → 일반적인 랜덤 탐험 전략으로는 수행할 수 없음
- 논문 결과 영상 참고 → 링크
- 10개의 Atari 환경 중 탐험이 가장 어려운 환경들에서 성능 검증 수행
- 모든 도메인들에서 기존의 curiosity-driven 탐험 기법들을 뛰어넘는 성능을 보임
- Random Network Distillation (RND), Intrinsic Curiosity Module (ICM)
- DM-HARD-8에서 BYOL-Explore는 intrinsic reward로 augmented된 extrinsic reward만 사용하여 다수의 task에서 human-level 성능 달성
- Agent57이나 Go-Explore과 같은 타 알고리즘에 비해 단순한 디자인을 가짐에도 불구하고 Atari의 가장 어려운 10개의 탐험 환경에서 superhuman 성능 달성
- BYOL-Explore는 DM-HARD-8 환경에서 학습
- 특히 BYOL-Explore는 해당 성능을 단일 world model과 단일 policy network만으로 달성 → 두 요소는 모든 task에서 동시에 학습
2. Method
- 본 논문의 에이전트는 3가지 기법으로 구성됨
- Self-supervised latent-predictive world model → BYOL-Explore
- 일반적인 reward normalization과 prioritization
- 기존 RL 에이전트가 representation을 BYOL-Explore의 world 모델과 공유할 수 있음 (optionally)
2.1 Latent-Predictive World Model
- BYOL-Explore는 latent level에서 수행되는 multi-step predictive world model
- BYOL (Bootstrap Your Own Latent)이라는 self-supervised 학습 기법에서 영감을 받음
- BYOL과 유사하게 BYOL-Explore 모델은 Exponential Moving Average (EMA) target network에 의해 생성된 target을 사용하여 online network를 학습
- BYOL의 경우 동일한 관측에 다른 augmentation을 적용하여 target을 생성하지만 BYOL-Explore는 online network의 EMA에 의해 연산된 미래 관측들로 부터 target을 취득 (handcrafted augmentation 사용 X)
- BYOL 참고 블로그
- BYOL-Explore는 RNN을 사용하여 agent state를 만들어냄
- 이후에 설명할 내용
- 어떻게 online network가 future prediction을 만들어내는지
- 어떻게 예측에 대한 target이 target network를 통해 얻어지는지
- Online network 학습을 위한 loss
- 어떻게 world model에 대한 uncertainty를 계산하는지
(i) Future Predictions
- Online network는 인코더 fθ로 구성되어 있음
- 인코더 fθ: 관측 ot를 observation-representation fθ(ot)∈RN으로 변환 (N: embedding size)
- Observation-representation fθ(ot)와 이전의 행동 at−1을 close-loop RNN cell이라고 정의한 hcθ에 입력으로 대입
- 이는 history ht∈Ht의 representation bt∈RM을 계산 (M: size of history-representation)
- 여기까지의 수식 → bt=hcθ(bt−1,at−1,fθ(ot))
- History representation bt는 open-loop RNN cell hoθ를 초기화하는데 사용
- Open-loop representation의 출력: (bt,k∈RM)k=1K−1, bt,k=hoθ(bt,k−1,at+k−1)
- bt,0=bt 이고 K는 open-loop horizon
- Open-loop RNN cell의 역할은 오직 미래의 행동만을 관측하여 미래의 history-representation을 도출하는 것
- 최종적으로 open-loop representation bt,k는 predictor gθ의 입력으로 사용되어 open-loop prediction gθ(bt,k)∈RN을 출력
(ii) Targets and Target Network
- Target network는 observation encoder fϕ로 파라미터는 online network의 파라미터 θ의 EMA
- targets fϕ(ot+k)∈RN을 출력하여 online network를 학습하는데 사용
- 각 업데이트마다 target network의 가중치는 EMA update를 통해 업데이트됨
- ϕ←αϕ+(1−α)θ , α: target network EMA 파라미터
(iii) Online Network Loss Function
- RL 에이전트가 경로의 batch ((ojt,ajt)t=0T−1)j=0B−1를 수집한다고 가정
- T∈N: 경로의 길이, B∈N: batch size
- Loss LBYOL−Explore(θ)는 시간 t+k에 open-loop future predictions gθ(bjt,k)와 이에 대한 타겟 fϕ(ojt+k) 사이의 평균 cosine distance를 최소화하도록 정의
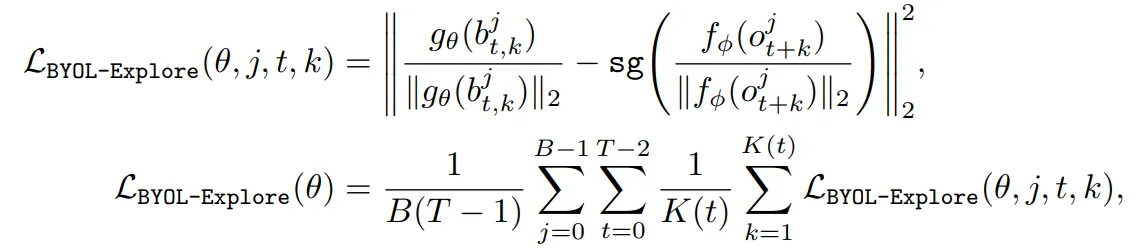
- K(t)=min는 valid open-loop horizon, sg는 stop gradient operator
(iv) World Model Uncertainties
- Transition (o_t^j, a_t^j, o_{t+1}^j)에 대한 uncertainty는 해당 prediction loss의 합
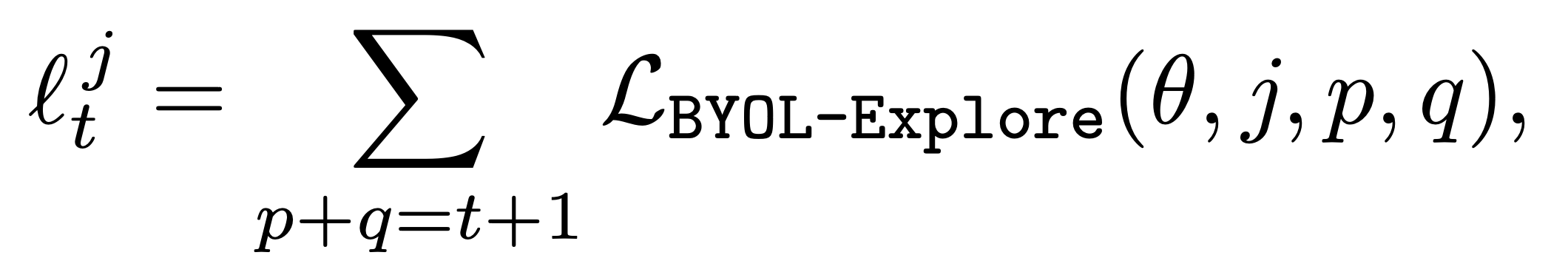
- 0 \leq p \leq T-2, 1 \leq q \leq K이고 0 \leq t \leq T-2
- “과거의 부분적인 history를 기반으로 얼마나 관측을 예측하기 어려운가”를 기반으로 intrinsic reward를 받음
Intuition on why BYOL-Explore learns a meaningful representation
- BYOL의 핵심과 유사한 intuition을 가짐
- 학습 초기
- Target network는 랜덤하게 초기화 되고 BYOL-Explore의 online network와 closed-loop RNN은 미래의 random feature를 예측하도록 학습
- 이는 online observation representation이 미래를 예측하기 위해 유용한 정보들을 capture할 수 있도록 유도
- 이후 이 정보들은 EMA의 느린 복사 매커니즘에 의해 target observation encoder network로 distilled
- 이 feature들은 online network의 타겟이 되고 이들을 예측하는 것이 online representation의 품질을 향상시킴
2.2 Reward Normalization and Prioritization Scheme
Reward Normalization
- 본 논문에서는 world model uncertainties l_t^j를 intrinsic reward로 사용
- 학습 동안 uncertainty의 non-stationary에 대응하기 위해 RND에서 사용한 것과 동일한 reward normalization을 사용
- EMA 추정을 통해 얻은 raw rewards ((l_t^j){t=0}^{T-2}){j=0}^{B-1}을 이것의 표준편차 \sigma_r로 나눠주는 방식으로 normalization 수행 → l_t^j / \sigma_r
Reward Prioritization
- 보상을 normalization 하는 것에 추가적으로 optional 하게 높은 uncertainties를 가지는 보상들만을 최적화하고 낮은 uncertainties의 보상들은 무시할 수 있음
- Intrinsic reward → 처음에는 모델이 부정확하므로 환경의 일부에만 집중하지만 시간이 지나면 익숙한 reward는 자연스럽게 무효화되고 높은 uncertainty에 집중하여 최적화를 수행하게 됨
- 이 매커니즘은 에이전트가 모든 uncertainties의 source를 한번에 최적화 하는 것이 아니라 높은 uncertainties의 source들만 최적화하는 것을 가능하게 함
- 정의 → \mu_{l/\sigma_r}: 연속적인 normalized rewards의 batch ((l_t^j / \sigma_r){t=0}^{T-2}){j=0}^{B-1}에 대한 adjusted EMA mean
- \mu_{l/\sigma_r}를 높은 uncertainty reward와 낮은 uncertainty reward를 나누는 clipping threshold로 사용
- Intrinsic reward의 역할을 수행하는 clipped and normalized reward
- r_{i,t}^j=\max(l_t^j / \sigma_r - \mu_{l/\sigma_r},0)
- 높은 uncertainty를 가지는 reward만 intrinsic reward로 사용
2.3 Generic RL Algorithm and Representation Sharing
- BYOL-Explore는 policy의 학습을 위한 어떤 RL algorithm과도 결합되어 사용할 수 있음
- 추가적으로 intrinsic reward의 제공을 위한 BYOL-Explore는 RL 에이전트에 의해 학습된 representation을 shape하는데 사용될 수 있음 → BYOL-Explore의 world model의 몇몇 요소들을 직접적으로 RL model과 공유
- 예를 들어 encoder f_{\psi}, RNN cell h_{\psi}^c, policy head \pi_{\psi}, value head v_{\psi}로 구성된 recurrent agent를 고려
- Encoder와 RNN cell 레벨에서BYOL-Explore world model의 가중치 \theta를 RL model의 가중치 \psi와 공유 → f_{\psi}=f_{\theta}, h_{\theta}^c=h_{\psi}^c
- RL과 BYOL-Explore의 loss를 사용하여 joint representation을 학습할 수 있음
3. Experiments
- Hard exploration을 포함하는 benchmark task-suite에서 알고리즘 성능 검증
- 해당 benchmark들은 관측의 복잡도, partial observability, procedure generation 등에서 다른 특성을 가짐
- 본 논문의 에이전트를 JAX로 구현
Atari Learning Environment
- 50개의 Atari 게임들로 구성된, 널리 사용되는 RL 벤치마크
- 특성: 2D, fully observable, (fairly) deterministic 환경, 긴 optimization horizon (에피소드가 평균 10000 스텝 동안 지속), 복잡한 관측 (84x84의 grayscale 이미지)
- 10개의 가장 어려운 탐험 환경을 선택 → Alien, Freeway, Gravitar, Hero, Montezuma’s Revenge, Pitfall, Private Eye, Qbert, Solaris, Venture
Hard-Eight Suite
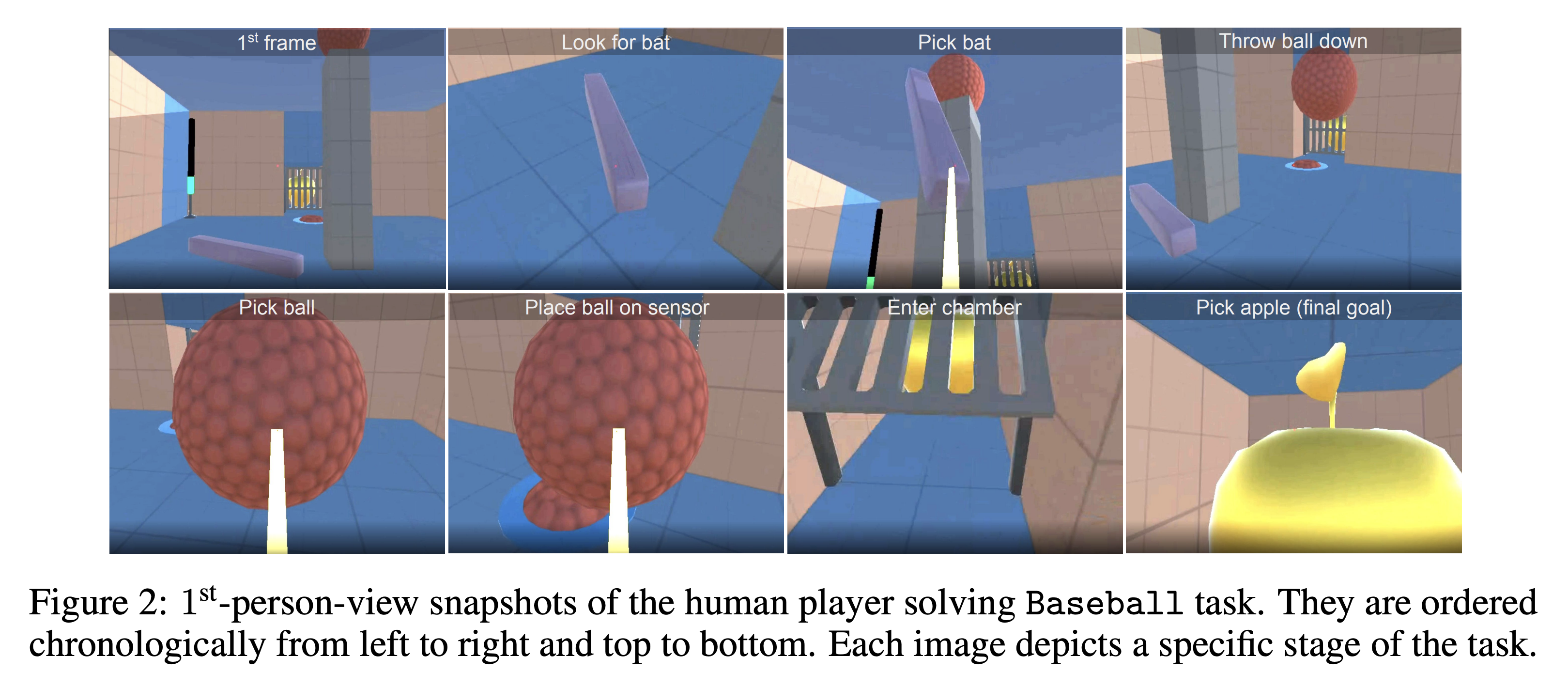
- 해당 벤치마크는 8개의 어려운 탐험 task로 구성
- 특성: sparse reward, procedurally generated 3D world, partial observability, continuous control, highly variable initial condition
- 각 task는 에이전트가 환경의 특정 물체와 상호작용 하는 것을 요구 → 해당 물체의 특성 (모양, 색, 위치)은 매 에피소드마다 바뀜
- 에이전트는 에이전트의 위치에서 오직 일인칭 시점으로만 관측을 하지만 더 명확하게 하기 위해서 본 논문의 결과 비디오에서는 top-down 시점과 삼인칭 시점을 제공
- 현재 가장 뛰어난 강화학습 에이전트는 이 문제들을 적은 양의 사람 데모 데이터를 사용하여 문제를 풀고 있음
- 이런 데모 데이터나 reward shaping 없이는 R2D2 같은 최신 심층강화학습 알고리즘조차도 어떤 task에서도 양의 보상을 얻지 못함
- 본 논문의 경우 단일 강화학습 에이전트와 단일 world model로 모든 8개의 task를 함께 학습 → multi-task setting
3.1. Experimental Setup
- BYOL-Explore는 4개의 주요한 hyperparameter로 구성
- 타겟 네트워크 EMA 파라미터 \alpha, open-loop horizon K, reward clip 여부, BYOL-Explore representation을 RL 네트워크와 공유할지 여부
- BYOL-Explore에서 어떤 부분이 성능에 주요한 영향을 미치는지 더 잘 이해하기 위해서 4개의 ablation 수행, 각 ablation에서 BYOL-Explore는 하나의 hyper-parameter만을 변경
- Fixed-targets: target network EMA 파라미터를 \alpha=1로 세팅
- Horizon=1: horizon을 K=1로 세팅
- No clipping: intrinsic 보상의 clipping을 사용하지 않음
- No sharing: RL network와 BYOL-Explore의 world model을 분리하여 학습
- 추가적으로 오직 extrinsic reward만을 사용하여 RND, ICM과 같은 baseline과 순수한 강화학습 알고리즘에 대한 학습 수행
- 또한 2개의 다른 평가 방식을 사용
- mixed reward function r_t=r_{e,t} + \lambda r_{i,t}
- Normalized extrinsic reward r_{e,t}와 에이전트에 의해 계산된 intrinsic reward r_{i,t}의 linear combination with mixing parameter \lambda
- fully self-supervised
- 오직 intrinsic reward r_{i,t}만 최적화됨
- mixed reward function r_t=r_{e,t} + \lambda r_{i,t}
Choose of RL algorithm
- 본 논문은 VMPO 알고리즘을 강화학습 알고리즘으로 사용
- VMPO는 효율적인 on-policy 최적화 기법으로 discrete와 continuous 행동 환경에서 모두 사용가능하므로 본 논문에서 고려하는 모든 도메인에 적용 가능
Performance Metrics
- 본 논문은 성능의 평가를 위해 Human Normalized Score (HNS) 사용 (학습 스텝 t에 대해)
- HNS(t) = \frac{Agent_{score}(t)-Random_{score}}{Human_{score}-Random_{score}}
- HNS가 1보다 높은 경우 → super human performance
- 본 논문은 HNS를 0-1으로 클립한 CHNS를 정의함
3.2. Atari Results
- 학습 관련 설정
- target EMA rate \alpha=0.99, open-loop horizon K=8, \lambda=0.1 (intrinsic과 extrinsic reward의 결합 비율)
- 30 random no-ops, 평균 10 에피소드의 평균 성능 (3 seeds)
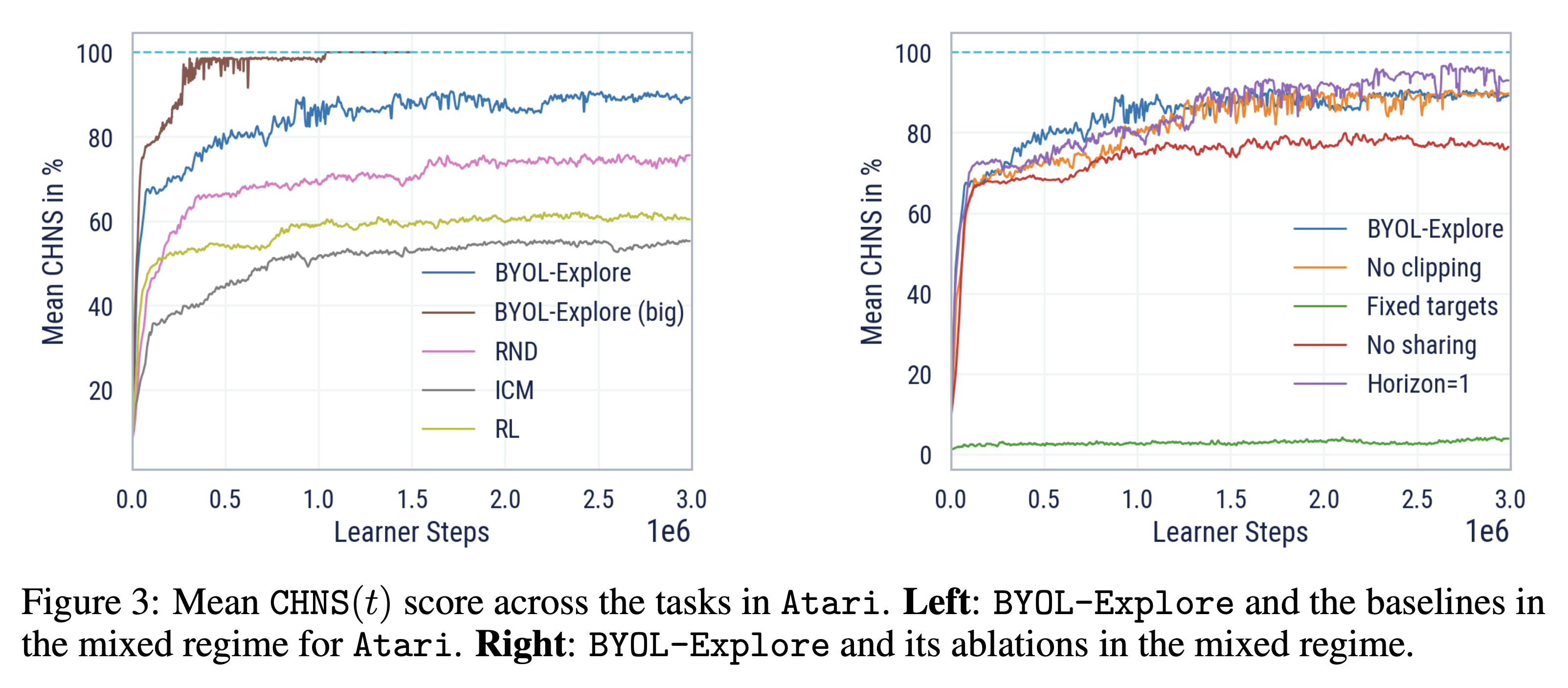
- Fig. 3의 왼쪽 그래프
- BYOL-Explore가 10개의 가장 어려운 탐험 환경에서 거의 superhuman 성능을 달성
- 다른 baseline인 RND, ICM, pure RL에 비해 좋은 성능을 보이는 것을 확인
- Fig. 3의 오른쪽 그래프
- BYOL-Explore의 ablation study를 진행한 것을 확인
- No clipping: intrinsic reward의 prioritization이 Atari 문제에서는 필요하지 않으므로 유사한 성능을 보임
- Horizon=1: 오히려 조금 더 좋은 성능을 보임 → Fully observable한 Atari 문제에서는 단순히 한 스텝만의 latent를 예측해도 충분히 효율적으로 탐험할 수 있음을 보여줌
- Fixed targets: 훨씬 나쁜 성능을 보임 → 학습된 타겟을 예측하는 본 논문의 접근이 좋은 성능에 필수적임을 보여줌
- Fixed target을 제외한 모든 ablation들이 baseline의 성능을 뛰어넘음 → 본 논문에서 제안하는 기법의 robustness를 보여줌
Purely Intrinsic Exploration
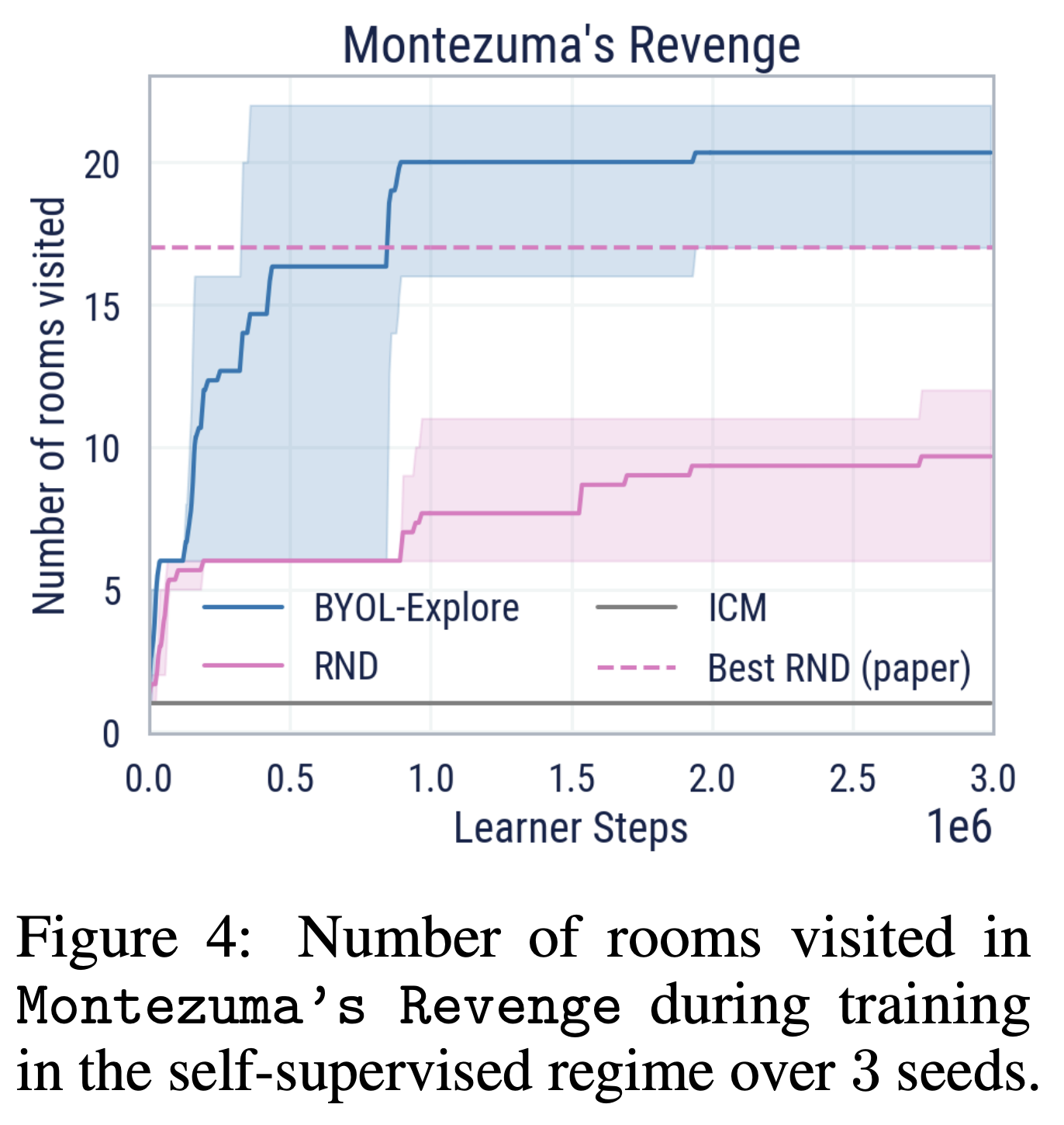
- Extrinsic signal 없이 오직 intrinsic reward만 주어졌을 때 어떻게 BYOL-Explore가 행동하는지 테스트
- Montezuma’s revenge 게임에서 \lambda=0으로 세팅 → 에이전트가 플레이 하는 동안 몇개의 다른 방을 방문하는지를 통해 탐험의 성능을 평가
- Fig. 4는 학습동안 extrinsic reward 없이 얼마나 많은 방을 방문했는지 보여줌
- RND에서 최고 성능 17개에 비해 본 논문의 에이전트는 20개가 넘는 방을 탐험
- 또한 RND는 intrinsic reward를 위해서 non-episodic 세팅을 사용하지만 본 논문에서는 episodic setting을 사용 → 에이전트의 탐험이 덜 risk-averse함
3.3. DM-HARD-8 Results
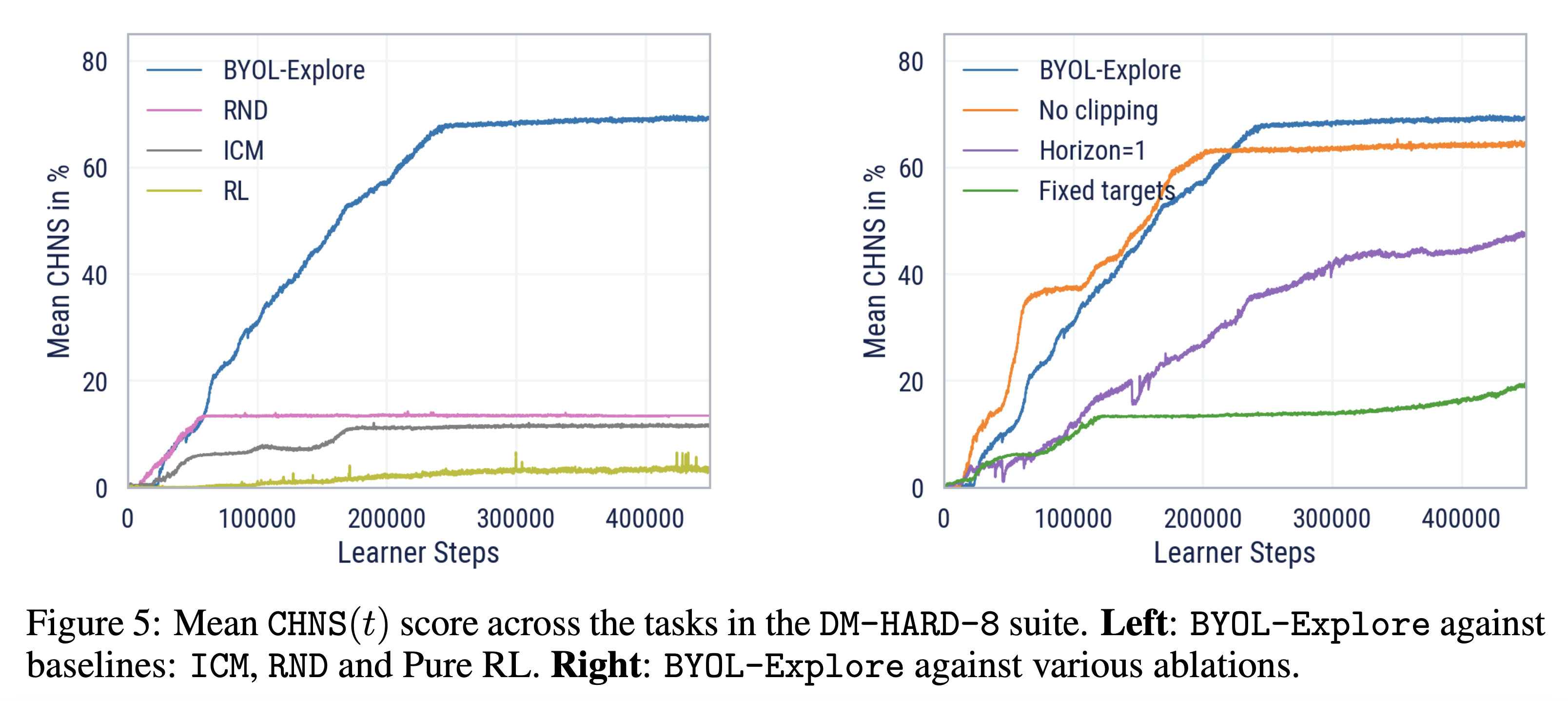
- 학습 관련 설정
- Target EMA rate \alpha=0.99, open-loop horizon K=10, \lambda=0.01
- 굉장히 도전적으로 multi-task 방식으로 학습 수행 → 하나의 에이전트가 8개의 모든 task를 풀도록 학습 → 매 에피소드의 시작마다 task가 랜덤하게 선택됨
- Fig.5의 왼쪽 그래프
- BYOL-Explore가 baseline들 (RND, ICM, pure RL)의 성능을 큰 차이로 뛰어넘는 것을 확인
- Fig. 5의 오른쪽 그래프
- 다양한 ablation에 대한 BYOL-Explore의 성능 비교
- No clipping: CHNS로 비교했을 때 BYOL-Explore와 비슷한 성능
- Horizon=1: fully observable한 Atari와는 다르게 해당 ablation에서는 학습 속도도 느리고 최종 성능도 더 낮음
- Fixed Target: 굉장히 나쁜 성능을 보이는 ablation
- 계산의 한계 때문에 No sharing ablation은 실행 X → 분리된 네트워크가 요구되므로 메모리가 2배로 들어감
- 다양한 ablation에 대한 BYOL-Explore의 성능 비교
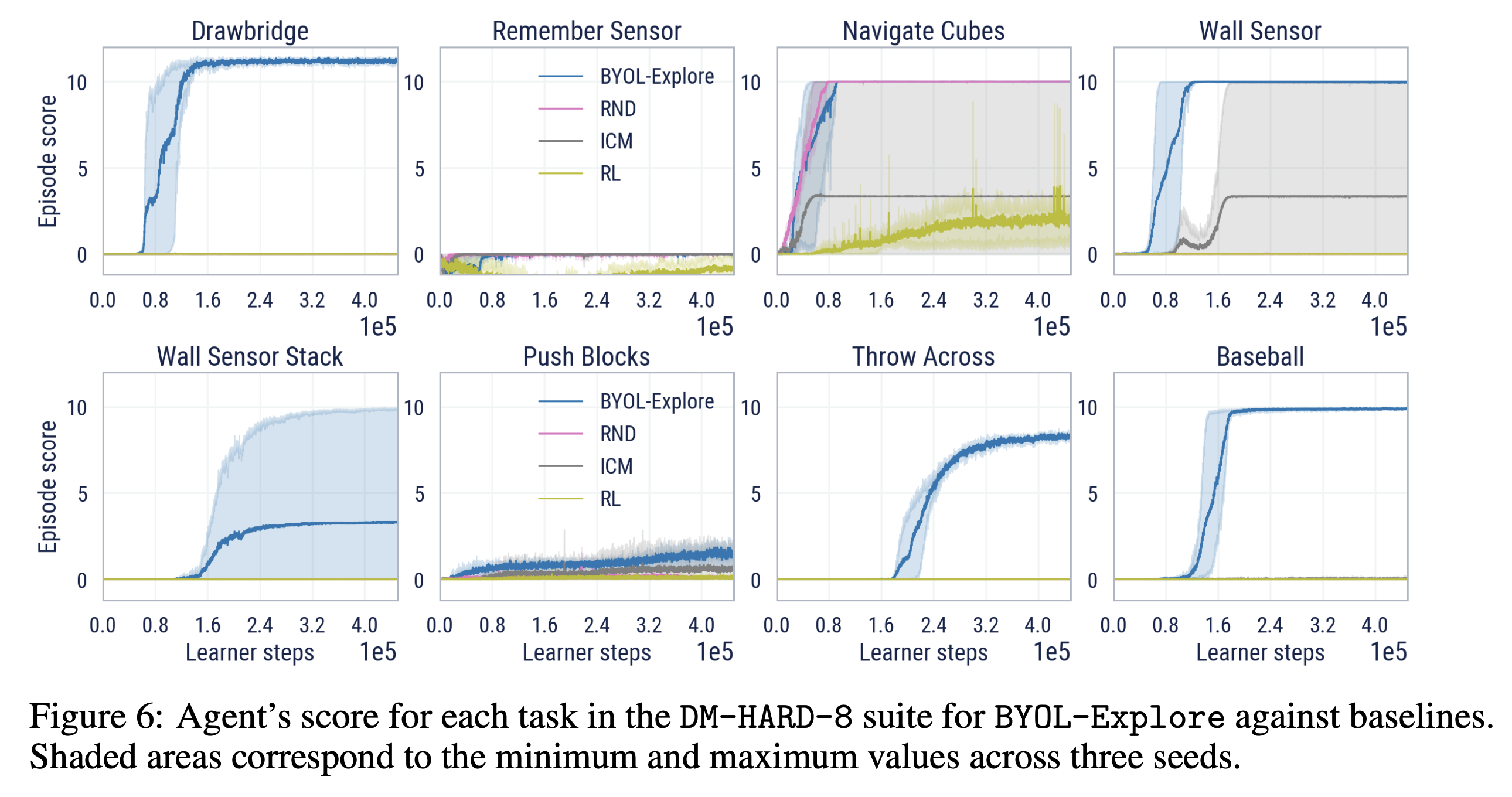
- Per-task 성능 분석 → 전체 학습 그래프: Fig. 6
- 먼저 다른 curiosity-driven 알고리즘 (ICM, RND)는 대부분의 DM-HARD-8 문제들에서 거의 양의 점수를 받지 못함
- 이와 대조적으로 BYOL-Explore는 8개 중 5개의 환경에서 강력한 성능을 보임
- 더 중요한 것은 BYOL-Explore는 사람의 데모 데이터를 사용하지 않고도 이 성능을 달성 (이전의 연구들에서는 없었던 케이스)
- BYOL-Explore는 4개의 문제에서는 사람의 성능까지도 뛰어넘음 (Navigate cubes, Throw-across, Baseball, Wall Sensors)
- 더 중요하게는 BYOL-Explore가 가장 어려운 문제인 Throw-across도 풀어냈다는 점 → 굉장히 어려운 문제여서 숙련된 사람 플레이어도 풀기 어려운 문제
- 흥미롭게도 Navigate Cubes 문제에서는 RND나 Fixed-targets ablation도 BYOL-Explore와 함께 최대 성능을 달성
- 이는 random projections의 예측이 spatial, navigation 탐험을 수행할 수 있도록 policy를 학습하기 때문 → 이에 따라 Navigate Cubes 문제에서 탐험은 잘 수행
- 다른 문제들에서는 물체와 상호작용하거나 도구를 사용해야하는 행동을 요구 → RND, Fixed-targets ablation이 모두 학습 실패
- 마지막으로 Remember Sensor, Push Blocks 환경이 특히 어려워서 모든 기법들의 성능이 좋지 않은 것을 확인 → 이는 점진적으로 생성되는 문제들이 너무 다양하기 때문 → 환경에서 이전의 단서들을 기억할 필요가 있음 → hard credit assignment 문제
Purely Intrinsic Exploration
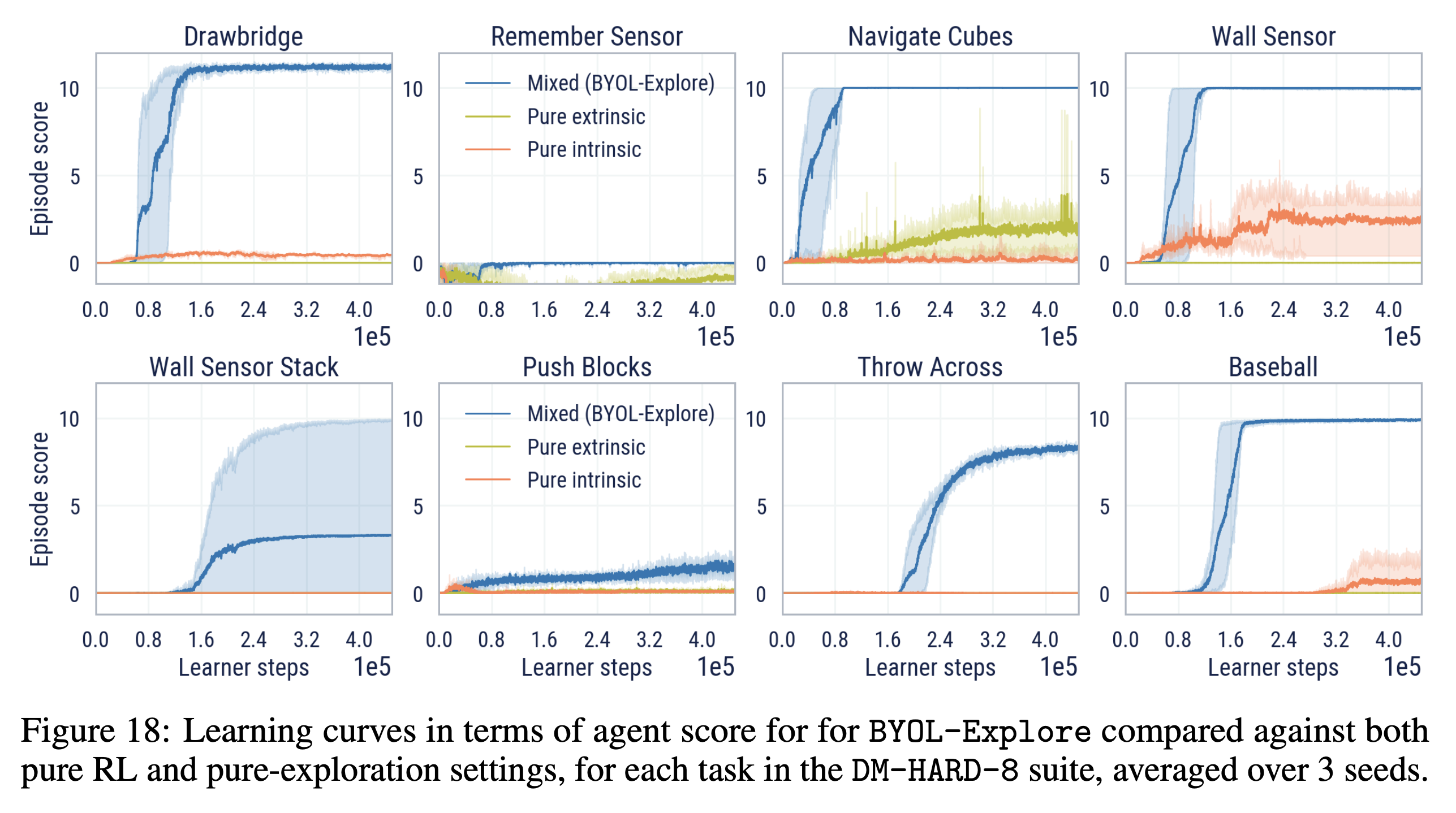
- DM-HARD-8 문제는 복잡한 dynamics, 물체와의 상호작용을 가지고 있으므로 순수하게 intrinsic하게 exploration을 하는 것은 매우 어려움
- Drawbridge나 Wall sensor 문제에서 약간의 양의 보상을 얻음
4. Conclusion
- BYOL-Explore → 단순한 curiosity-driven exploration 기법으로 hard exploration 환경에서 뛰어난 성능을 보임
- 추가적인 loss 없이 representation과 world model을 최근에 발전한 self-supervised learning 기법을 사용하여 latent 레벨에서 수행하는 multi-step prediction error를 통해 학습 수행
- Aiatri에서 10개의 가장 어려운 탐험 환경에서 superhuman 성능 달성
- 또한 DM-HARD-8 navigation and manipulation task에서도 기존의 exploration 기법들에 비해 뛰어난 성능을 보임 → 3D, Multi-task, Partially-observable and procedurally-generated 환경
- Future work
- World model을 scaling up하고 exploration 과 exploitation 간의 trade off에 대한 더 좋은 방법을 찾아서 성능을 향상 시킬 수 있을 것으로 생각
- DM-HARD-8을 넘어서 highly-stochastic하고 procedurally-generated 환경인 NetHack 같은 환경에 적용 예정
'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| Deep Reinforcement Learning from Human Preference (3) | 2024.11.10 |
|---|---|
| CLUTR: Curriculum Learning via Unsupervised Task Representation Learning (0) | 2024.11.09 |
| Planning with Diffusion for Flexible Behavior Synthesis (0) | 2024.11.03 |
| Estimating Risk and Uncertainty in Deep Reinforcement Learning (0) | 2024.11.03 |
| [Sampled MuZero] Learning and Planning in Complex Action Spaces (0) | 2024.10.15 |



