반응형

- 논문 링크: https://arxiv.org/pdf/2403.14599.pdf
- 프로젝트 페이지 링크: https://snap-research.github.io/MyVLM/
0. Abstract
- 최근의 대형 비전-언어 모델 (Vision Language Models, VLM)은 시각적인 컨텐츠에 대한 이해와 텍스트 묘사에 대한 생성에 좋은 성능을 보였지만 사용자별 컨셉 (user-specific concept)에 대한 이해의 성능은 부족
- 본 논문은 VLM의 개인화에 대한 연구! → 사용자가 제공하는 컨셉 (인물, 사물 등…)에 대해 학습하고 추론하는 것이 가능
- 예를 들어 해당 모델은 이미지 안에서 사용자를 인지하고 사용자의 행동에 대해 커뮤니케이션 할 수 있으며 사용자의 개인적인 경험과 관계에 대해 고려하는 것이 가능함
- 다양한 사용자별 컨셉에 VLM이 대응하도록 하기 위해 외부의 컨셉 헤드 (external concept head)를 통해 VLM을 강화
- VLM이 이미지 내에서 특정 타겟 컨셉의 존재를 인지할 수 있도록 함
- 컨셉이 인식되면 VLM의 중간 특징 공간 (intermediate feature space)에서 새로운 컨셉 임베딩을 학습
- 해당 임베딩은 언어 모델이 자연스럽게 타겟 컨셉을 응답에 반영하도록 언어 모델을 가이드
- 해당 기법을 BLIP-2와 LLaVA에 적용 → 개인화된 이미지 캡셔닝이나 개인화된 시각적 질의 응답 가능
1. Introduction
- 비전을 LLM에 통합한 비전-언어 모델 (VLMs)은 모델이 시각적인 컨텐츠를 “보고” 추론하는 것이 가능하도록 함
- 현재의 VLM은 일반적인 지식은 가지고 있지만 개인적인 사용자에 대한 개인화된 이해 능력은 부족한 상황
- 예를 들어 VLM이 이미지에서 “개”는 인지하지만 이 개가 “사용자의 개”인지는 이해하지 못함
- 이는 흥미로운 질문을 불러일으킴 → 모델이 특정한 사용자에 대해 사용자별 컨셉 (사용자와 관계된 물체나 인물)을 이해하고 적용하는 능력을 갖출 수 있을까??
- 즉, “나”에 대한 질문을 할 수 있을까? → “내가 무엇을 입고 있습니까?”, “이미지에서 내가 무엇을 하고 있습니까?”
- 이렇게 모델을 개인화하여 더 의미 있는 상호 작용을 제공하고 개인의 경험과 관계를 더 잘 반영할 수 있음
- 기존 모델을 사용할 때 개인화 컨셉 적용을 위한 도전 과제
- 특정 사용자에 대해 파인튜닝을 수행하는 것은 계산적으로 비용이 크며 Catastrophic forgetting 문제를 유발할 수 있음
- 또한 사전 학습된 VLM에 의해 추출된 시각적 특징이 유사한 물체들을 효율적으로 구분하기에 충분하지 못할 수 있음
- 이런 도전과제들을 해결하기 위해 본 논문에서는 장면 내에서 사용자별 컨셉을 식별하도록 학습한 외부 헤드 (external head)를 통해 VLM을 강화
- 이 헤드들을 통해 특정 학습가능한 벡터들을 시각적 인코더의 출력에 더해줌
- 해당 학습가능 벡터들은 언어 모델이 생성하는 응답을 가이드하여 문맥적으로 정확하고 입력 이미지와 aligned된 개인적인 단어를 매칭시킴
- 해당 컨셉 벡터를 학습하기 위해 해당 컨셉을 묘사하는 소량의 이미지 (3-5장)를 사용 → 각 이미지에 대응되는 개인적인 단어들이 포함된 캡션을 함께 사용
- 그리고 컨셉 임베딩을 최적화하여 학습 데이터의 이미지가 주어졌을 때 비전 인코더의 출력에 컨셉 임베딩을 추가하면 VLM이 해당 개인화된 타겟 캡션을 생성하도록 학습
- 본 논문의 개인화 기법인 “MyVLM”은 사전학습된 VLM의 기존 가중치에 대한 변경 없이, 모델의 일반적인 능력을 유지하면서 사용자에 대해 개인화하는 것이 가능함
- 본 논문에서는 MyVLM을 BLIP-2와 LLaVA에 적용하여 이미지 캡셔닝과 시각적인 질의응답 문제에 대한 성능을 검증 → 그림 1 참고

- 본 논문에서는 MyVLM이 몇장의 이미지만 사용하여 특정 사물과 개인을 포함한 개인화된 컨셉을 효과적으로 통합하고 컨텍스트화 할 수 있음을 보임
- 타 베이스라인들과의 평가를 통해 이전에 학습한 컨셉에 대한 새로운 사례에 대해서도 일반화를 잘 하는 것을 보임
- 이렇게 새로운 문제에 대한 평가를 위하여 본 논문에서는 다양한 컨텍스트에서 다수의 물체와 개인을 묘사하는 새로운 데이터셋을 제공
- 본 논문에서 제안하는 개인화된 VLM의 목표
- 다양하게 변하는 컨셉의 새로운 이미지에 잘 적응해야 함 (특정 개인을 다양한 상황에서 알아봐야함)
- 컨셉을 주변 배경과 분리할 수 있어야함 → 특정 개인을 입고있는 옷과 분리
- 컨셉을 인식만 하는 것이 아니라 생성된 응답에 컨텍스트화 할 수 있어야함 → 단순히 컨셉을 “S*”로 출력하는 것이 아니라 “S*이 벤치에 않아서 와인을 마신다”와 같이 더욱 묘사적인 응답을 해야함
2. Method
2.1. Preliminaries
BLIP-2
- BLIP-2 모델은 3가지 주요 요소로 구성된 VLM 모델
- 사전학습된 ViT-L/14 비전 인코더
- 사전학습된 언어 모델
- 학습 가능한 Querying Transformer (Q-Former) 모델 (비전-언어 모달리티 간 격차를 해소)
- Q-Former는 각각 d=768의 차원을 가지는 32개의 학습 가능한 쿼리 토큰을 입력으로 받으며 3가지 종류의 레이어로 구성되어 있음 → self-attention, cross-attention, feed-forward layers
- 본 논문과 가장 연관된 것은 cross-attention 레이어
- 해당 블록은 추출된 이미지의 특징과 학습 가능한 쿼리 토큰 사이의 상호작용을 포착하도록 설계됨
- 특히 각 cross-attention 레이어에서 이미지 특징들은 먼저 학습된 선형 projection을 통해 Key (K)와 Value (V)로 투영됨 (projected)
- 32개의 학습된 쿼리 토큰들의 중간 표현 (intermediate representations)은 유사하게 어텐션 쿼리들 $q_i$의 세트로 투영됨
- 각 쿼리 $q_i$의 표현들에 대해 가중 평균 연산을 수행
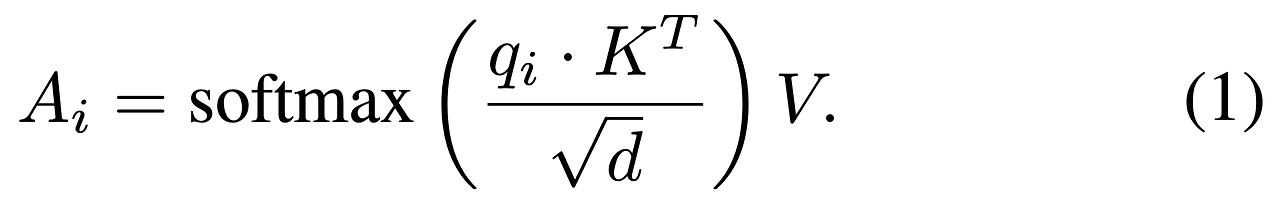
- 직관적으로 softmax에 의해 정의된 확률이 의미하는 것은 각 이미지 특징에서 각 쿼리 토큰으로 전달되는 정보의 양을 나타냄
LLaVA
- BLIP과 유사하게 LLaVA는 고정된 비전 인코더 (CLIP Vit-L/14)와 고정된 언어 모델 (Vicuna)을 연결하는 방법을 탐색
- LLaVA는 단일 선형 레이어의 단순한 구조를 사용하여 이미지 특징을 언어 모델의 토큰 임베딩 공간으로 맵핑
2.2. MyVLM
- 본 논문의 기법은 사용자별 컨셉으로 비전 언어 모델을 개인화하는 것
- 먼저 MyVLM을 BLIP-2 모델에 적용한 방법에 대해 설명하고 LLaVA에 적용한 방법을 설명
- 특정 컨셉에 대한 적은 수의 이미지 (3-5장)와 해당 이미지들의 컨셉 식별자인 S*을 포함하는 캡션만 필요함
- 본 논문의 목표는 VLM을 강화하여 컨셉을 묘사하는 새로운 이미지에 대한 특정 쿼리에 응답하는 능력을 부여하는 것
- 본 논문의 기법은 2가지 단계로 구성
- 첫번째는 “인지 (Recognizing)”로 주어진 장면에서 컨셉을 인지하는 것
- 두번째는 “소통 (Communicating)”으로 컨셉에 대한 정보를 언어 모델과 소통하는 것
- 이를 위해 이미지 내에서 개인화된 컨셉의 존재를 식별하기 위해 설계된 컨셉 헤드 (concept head)를 사용
- 그리고 사물이나 개인을 나타내는 학습된 컨셉 임베딩 (concept embedding)을 통해 LLM이 컨셉의 정보를 포함하는 개인화된 텍스트 응답을 할 수 있도록 가이드
- MyVLM의 전체 과정을 나타낸 것이 그림 2와 같음

Recognizing
- 사전학습 된 VLM이 개인적인 컨셉에 대한 추론이 가능하도록 하기 위해서는 먼저 주어진 장면 내에 해당 컨셉의 존재가 있는지에 대한 식별을 할 수 있어야 함
- 이를 위한 직접적인 방법은 VLM 비전 인코더의 특징 공간 (Feature space)을 고려하는 것
- 그러나 고정된 (Frozen) 비전 인코더의 특징 공간을 관측하는 것은 유사한 컨셉과 타겟 컨셉을 시각적으로 식별하기에 충분한 정보를 가지지 않음 (부록 C.3 참고)
- 비전 인코더 자체를 파인튜닝 하면 관심있는 물체를 더 잘 식별할 수 있지만 이는 정확한 응답 생성에 필수적인 일반적인 지식에 대한 성능과 전체 이미지의 정보를 추출하는 능력을 저하시킬 수 있음
- 대신 본 논문에서는 외부 컨셉 헤드를 사용하여 VLM을 강화
- 각 헤드는 단일 개인화 컨셉을 인지하는 목적으로 사용됨
- 헤드는 VLM 모델과 독립적으로 작동하며 사용자에 대한 물체의 식별을 위해 사전학습된 CLIP 모델로부터 추출된 임베딩으로 학습된 단순한 선형 분류기를 사용
- 특정 개인에 대한 개인화 출력을 얻기 위해 사전학습 된 얼굴 인지 네트워크를 추가적인 컨셉 헤드로 사용
- 또한 각 컨셉에 대해 분리된 헤드를 정의하여 추가적인 유연성을 제공 → 시간에 따라 추가적인 컨셉으로 자연스럽게 확장될 수 있도록 함
- 컨셉 헤드의 설계에 대해서는 부록 B.2 내용 참고
Communicating
- 관심있는 컨셉에 대한 인지 능력이 주어졌으면 VLM이 타겟 컨셉에 대한 응답에 대해 소통할 수 있도록 가르쳐야함
- 이를 위해 VLM의 중간 특징 공간에서 컨셉을 나타내는 단일 컨셉 임베딩 벡터를 학습 → 해당 임베딩은 언어 모델이 정확하고 제공된 이미지와 명령을 잘 일치시키는 컨셉 식별자가 포함된 텍스트 응답을 생성하도록 언어 모델을 가이드
- 임베딩의 학습 과정
- 먼저 다양한 컨텍스트에서 컨셉을 묘사하는 작은 세트의 이미지를 사용 → 각 이미지는 컨셉 식별자를 포함하는 타겟 캡션이 필요함
- 식별자에 대해서는 DreamBooth의 방식을 따르고 물체에 대한 개인화 출력은 기존에 존재하지만 흔하지 않은 단어를 사용하며 사람에 대한 개인화 출력은 짧은 이름을 사용
- 직접적인 최적화를 통해 컨셉 임베딩 e* 취득 → e*은 고정된 비전 인코더로부터 추출된 이미지 특징에 추가되고 Cross-Attention 레이어를 통해 Q-Former 네트워크에 입력됨
- Q-Former의 출력은 예측된 이미지 캡션을 생성하는 고정된 언어 모델로 입력됨
- 최적화 과정은 생성된 캡션과 제공된 타겟 캡션 사이의 Cross-entropy를 최소화하는 표준 형태
- 최적화 수식
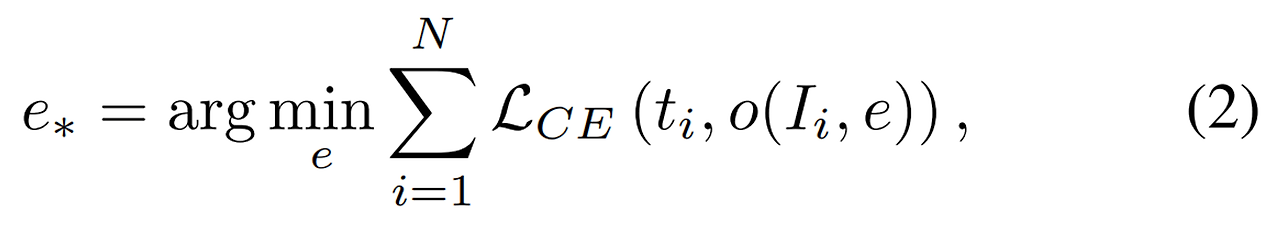
- $N$은 학습 샘플의 수
- $t_i$는 i번째 샘플의 타겟 캡션을 표현
- $o(I_i, e)$는 컨셉 임베딩 e가 제공되었을 때 i번째 이미지인 $I_i$를 통해 생성된 출력 캡션
- 추론 시 컨셉 헤드에 의해 인지된 컨셉의 임베딩은 비전 인코더의 출력에 유사하게 추가됨
Improving Generalization
- 직접적으로 컨셉 임베딩을 이미지 특징에 추가하는 것은 자연스럽지 못한 캡션을 생성하는 경우를 유발하기도 함 → 이는 다음과 같은 두가지 주요한 관측에 의해서 발생
- 먼저 Q-Former의 cross-attention에서 컨셉 임베딩에 대한 key (k*)와 value (v*)의 벡터 norm이 고정된 이미지 특징의 norm과 비교했을 때 훨씬 크다는 것을 확인
- 이에 따라 Q-Former 쿼리 토큰의 cross-attention 계산 전에 k과 v을 정규화하여 기존 key와 value의 평균 norm과 같도록 함 → 각각 $n_k, n_v$로 정의
- 임베딩의 key와 value에 대한 식
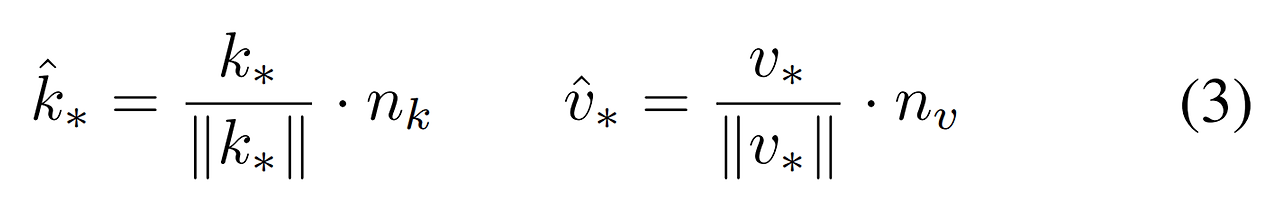
- 두번째로 Q-Former의 cross-attention 레이어에서 계산된 어텐션 가중치 (식 1)에서 컨셉 토큰이 어텐션의 분포에 비해 큰 영향력을 가짐
- 이에 따라 쿼리 토큰이 이미지 토큰에 의미적으로 영향을 미치지 못하게 됨
- 기존 이미지 토큰이 적절하게 적용되지 못하면서 관련된 시각적 정보다 언어 모델로 전달되지 못함 → 생성된 캡션과 이미지 사이에 불일치가 일어나게 될 수 있음
- 모든 토큰의 어텐션 분포가 더욱 균형을 잡을 수 있도록 모든 32개의 Q-Former 쿼리 토큰에 대한 컨셉 임베딩에 할당된 어텐션 확률에 대해 L2 정규화 사용
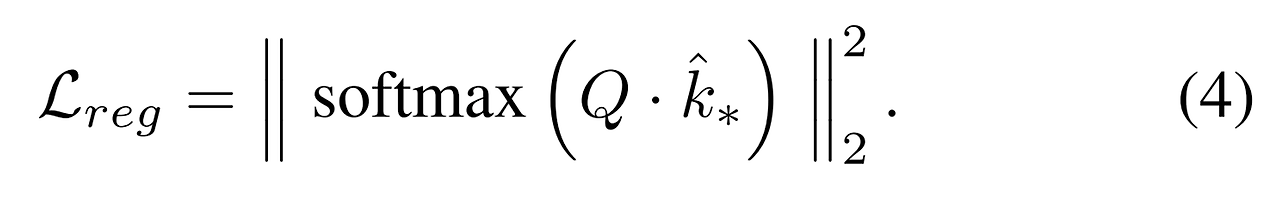
- 원본 이미지 특징에 적용되는 토큰을 더 촉진시켜서 출력이 더욱 이미지와 일치하는 결과를 얻을 수 있었음 → 부록 C.2 참고
- 먼저 Q-Former의 cross-attention에서 컨셉 임베딩에 대한 key (k*)와 value (v*)의 벡터 norm이 고정된 이미지 특징의 norm과 비교했을 때 훨씬 크다는 것을 확인
2.3. MyVLM over LLaVA
- MyVLM을 LLaVA에 적용하기 위해 다음의 조정들을 수행
- 컨셉 임베딩을 직접적으로 비전 인코더 뒤에 추가하는 것 대신 선형 투영 (Linear Projection)의 출력에 추가 → 더욱 빠르고 안정적인 수렴
- LLaVA가 cross-attention을 사용하지 않기 때문에 식 3의 key, value 정규화는 생략 → 대신 컨셉 임베딩의 벡터 norm이 비전 인코더에 의해 출력된 [CLS] 토큰과 같게 rescale
- 식 4의 어텐션 기반 정규화를 변경 → 다른 입력 토큰으로부터 컨셉 임베딩으로 할당되는 낮은 어텐션들을 증가시키도록 L2 정규화를 적용 → 언어 토큰과 다른 투영된 입력 토큰 포함
- 흥미롭게도 컨셉 임베딩이 투영된 이미지 특징과 함께 언어 모델의 입력으로 사용되므로 학습된 컨셉 임베딩이 입력 이미지 내에서 의미 있는 영역에 해당하는지 자연스럽게 살펴볼 수 있음
- LLaVA의 언어 모델의 셀프 어텐션 레이어를 조사하고 각 이미지 패치에 할당된 컨셉 임베딩의 어텐션 가중치를 시각화 → 그림 3 참고

- 어텐션 레이어의 컨셉 임베딩이 MyVLM의 능력을 확장하는데 충분한 인사이트를 제공할 수 있음을 보임
- LLaVA의 언어 모델의 셀프 어텐션 레이어를 조사하고 각 이미지 패치에 할당된 컨셉 임베딩의 어텐션 가중치를 시각화 → 그림 3 참고
2.4. MyVLM for Additional Applications
Personalized Vision Question-Answering
- MyVLM을 개인화된 시각적 질의응답에 적용하기 위해서 위에서 설명한 것과 유사한 접근을 사용하지만 목적 함수를 정의하기 위해 사용되는 타겟 출력과 언어 명령을 변경
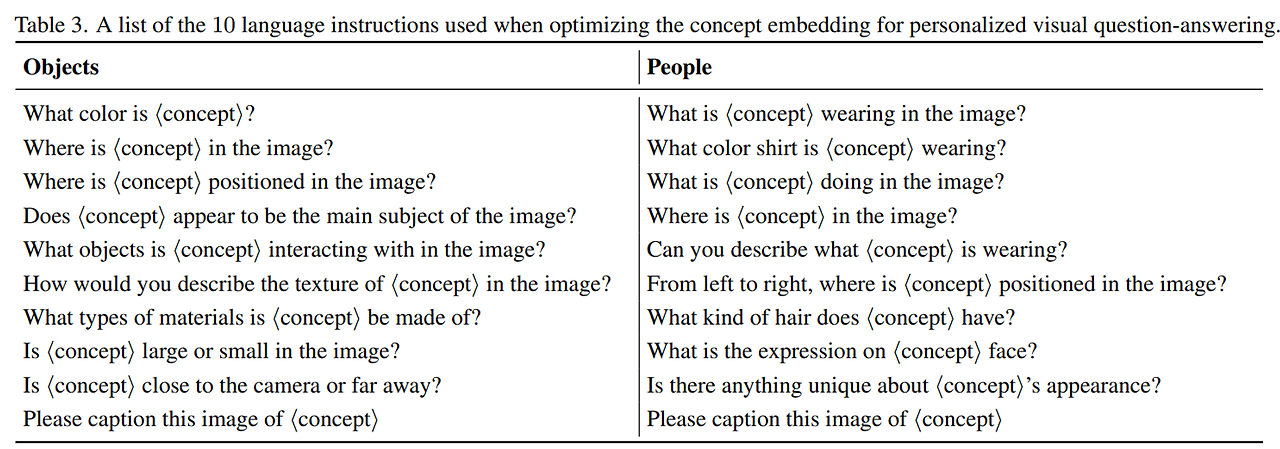
- 또한 시각적인 질의 응답에서 주어진 이미지에 대한 어떤 질문에도 대답할 수 있도록 일반화해야함 → 타겟 컨셉과 관련된 10쌍의 질문과 응답 쌍을 정의
- 예시: “S의 색은?”, “S이 이미지의 어디에 위치해있는가?”, “S*이 무엇을 입고있는가?”
- 각 최적화 스텝에서 랜덤하게 하나의 질문-응답 쌍을 샘플링하여 사용
Personalized Referring Expression Comprehension
- MyVLM을 추가적인 개인화 문제에 적용 → Referring Expression Comprehension (REC)
- 주어진 이미지에서 타겟 대상의 위치를 찾는 문제
- 이를 위해 MiniGPT-v2 사용 → 최신 VLM으로 다른 문제 식별기를 통해 다양한 비전-언어 문제를 다룰 수 있음
- MiniGPT-v2는 LLaVA와 동일한 구조를 가지며 본 논문의 컨셉 임베딩을 위한 학습 과정을 사용
- 컨셉 임베딩의 최적화를 위해 기존과 동일한 개인화 캡션과 명령을 사용:
- “[caption] Please caption this image of S*”
- 추론 동안에는 언어 모델의 명령을 다음과 같이 변경하여 REC를 해결
- “[refer] S* in the image”
- 이를 통해 제공된 이미지에서 타겟 물체에 대한 바운딩박스 좌표를 반환
3. Experiments
Dataset
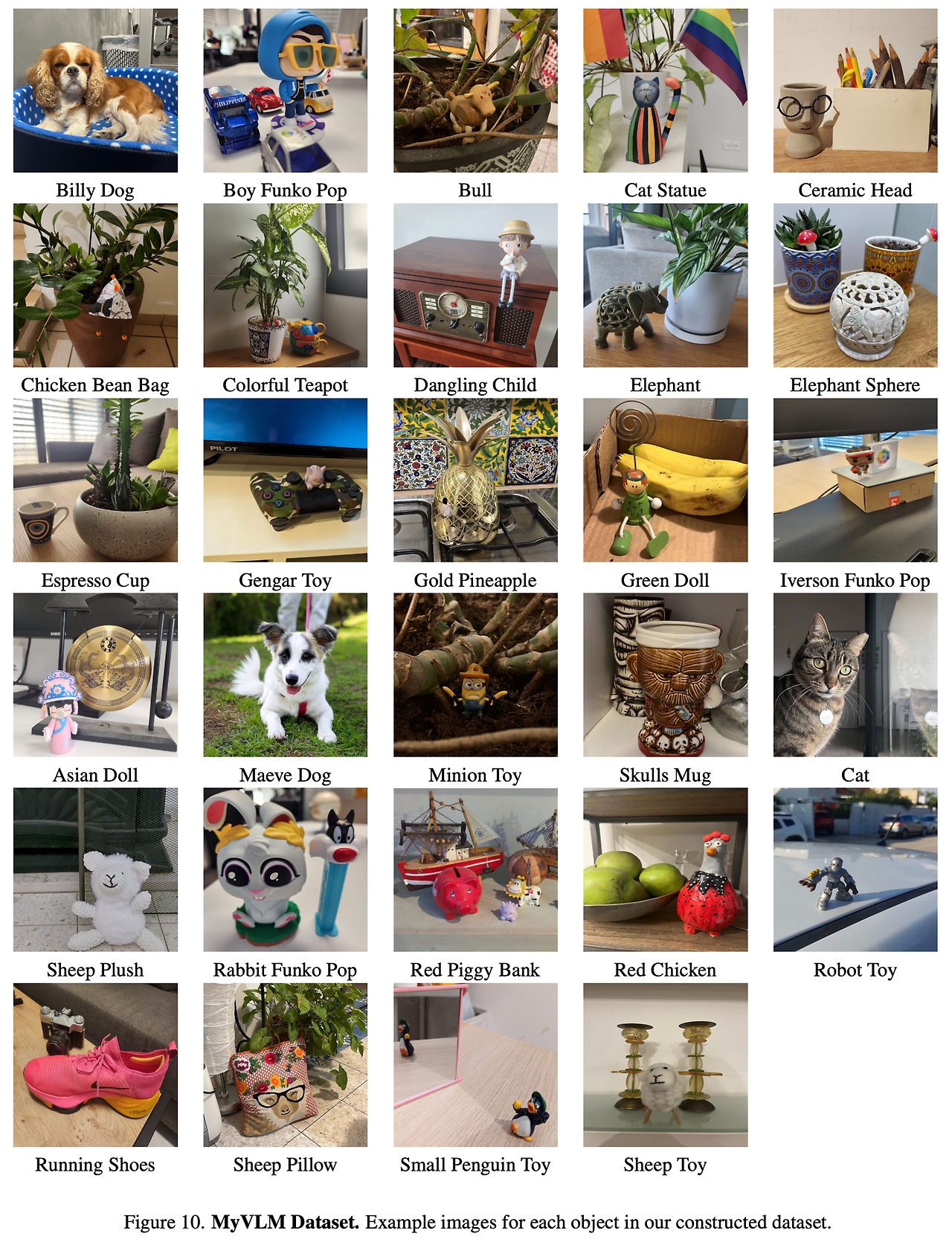
- VLM의 개인화를 위한 기존 데이터셋이 없으므로 본 논문에서 평가를 위한 새로운 데이터셋을 구축
- 두가지 카테고리로 데이터 분리 → 물건과 사람
- 물건에 대해서는 장난감, 동상, 머그컵, 애완동물 등 29개의 물건 사용 → 각 컨셉에 대해서 다양한 장면에 대해 적어도 10장의 이미지를 추가
- 사람에 대해서는 다양한 나이대 (25-80살)의 16명의 사람의 이미지를 수집 → 각 사람에 대해 최소 15장의 이미지 사용
- 각 이미지에 대해서는 컨셉 식별자를 포함하여 대응하는 개인화된 캡션을 작성
- 각 물건의 예시는 부록 B.3 참고
Evaluation
- 개인화된 이미지 캡션에 대해 정량적인 평가 수행 → 2가지 요소에 대해서 평가
- 생성된 캡션에 컨셉 식별자가 적어도 한번 등장했는지 확인
- 이는 새로운 이미지에서 컨셉을 인지했는지에 대한 능력과 임베딩을 통해 출력에 컨셉을 통합하는 능력이 있는지를 확인할 수 있음
- 입력 이미지, 타겟 캡션과 생성된 캡션이 일치하는지 확인 → 두가지 평가 요소 사용
- 입력 이미지와 생성된 캡션 사이의 CLIPScore
- 캡션 문장의 유사도 측정 → 타겟 캡션과 생성된 캡션에 대한 문장 임베딩을 추출하고 이들 사이의 평균 코사인 유사도 계산
- 위의 두 경우 모두에 대해 컨셉 식별자를 컨셉의 카테고리로 변경 → 예시: <your-dog>은 “dog”으로, <your-toy>는 “toy”로 변경
- 생성된 캡션에 컨셉 식별자가 적어도 한번 등장했는지 확인
Baselines
- 개인화된 캡션을 생성하는 베이스라인들이 없으므로 기존 기법들에 몇가지 변경된 기법을 추가
- 방법 1
- 단순 변경 (Simple Replacement) 방식
- 먼저 고정된 VLM 모델을 사용하여 캡션을 생성
- 각 컨셉에 대해 GPT-4V를 통해 컨셉을 묘사하는 3가지 키워드를 정의
- 사람에 대해서는 컨셉 당 하나의 키워드 지정 (man or woman)
- VLM에 의해 생성된 키워드가 주어지면 캡션에서 키워드를 검색
- 키워드를 찾으면 컨셉 식별자를 해당 키워드로 대체
- 방법 2
- LLM 가이드 베이스라인 사용 → 고정된 VLM에 대해 캡션이 생성되면 해당 캡션을 언어 모델에 통과시키고 만약 키워드가 존재하면 이를 캡션의 언어 식별자와 통합하도록 질의
- 해당 접근은 더육 유연한 제한조건을 제공하여 언어 모델이 더욱 자유롭게 컨셉을 캡션에 통합하도록 함
3.1. Personalized Captioning
Qualitative Evaluation
- 그림 4를 보면 LLaVA를 통해 사용자가 제공한 다양한 컨셉에 대해 생성된 개인화 캡션 결과를 확인할 수 있음

- MyVLM에 의해 생성된 캡션들은 일반적인 VLM에 의해 생성된 일반적이고 추상적인 묘사에 비해 타겟 대상을 강조한 캡션을 생성
- MyVLM은 자연스럽게 컨셉 식별자를 생성된 출력에 통합하며 남은 설명들도 입력 이미지와 일치
- 또한 그림 4의 1, 3번 예시처럼 다수의 사람들이 있는 이미지에 대해서도 성공적으로 타겟을 식별하여 캡션을 생성
- 다수의 물건이 주변에 있을때도 사용자가 제공한 물건에 대해서 개인화 캡션을 생성하고 이에 대한 위치를 정확히 표현 → 그림 4의 가장 오른쪽 예시 참고
- 추가적인 결과는 부록 D 참고
Qualitative Comparison
- 그림 5를 살펴보면 LLM 가이드 베이스라인과의 결과를 비교할 수 있음

- 베이스라인 결과
- 베이스라인은 VLM에 의해 생성된 캡션에 크게 의존함
- 동일 이미지에 타겟 컨셉과 동일한 키워드를 가지는 다른 대상이 등장했을 때 문제가 발생
- MyVLM 결과
- 성공적으로 타겟 대상을 식별하고 주변의 컨셉들과 구분된 캡션을 생성
- 다수의 대상이 있으면서도 컨셉이 이미지의 작은 부분을 구성하는 경우에도 잘 응답을 수행
- 또한 그림 6에서 GPT-4의 결과와 비교

- GPT-4V 적용 방법 → 이미지에서 식별자에 대응하는 타겟 컨셉을 제공하고 컨셉을 포함하여 캡션을 생성하라고 요청
- GPT-4V의 경우 새로운 이미지에 대해서도 잘 일반화하지만 유사하게 텍스트로 묘사할 수 있는 적대적 예시가 이미지에 있을 때 이를 타겟 컨셉으로 잘못 식별하는 경우가 있음
- 가장 왼쪽의 예시를 보면 컨셉에 대해 “파란 눈이 있는 디자인의 컵”으로 잘못 연관짓는 것을 볼 수 있음
- MyVLM은 이런 어려운 적대적인 예시들이 있어도 타겟 컨셉을 잘 식별함
Quantitative Comparison
- MyVLM과 다른 베이스라인들의 성능 비교
- 각 컨셉에 대해서 랜덤하게 5개의 다른 학습 셋을 샘플링, 각 4개의 이미지 포함
- MyVLM을 각 학습셋에 대해 학습하고 모든 검증 이미지에 대해 캡션 생성
- 총 2,430개의 검증 이미지를 사용하며 1,265개의 이미지에 사용자별 물건을 포함하고 나머지 이미지들은 사람에 대해 묘사
- 먼저 각 베이스라인이 컨셉 식별자를 생성된 캡션에 포함하는지 평가 → 표 1 참고

- Recall 측면에 있어서 MyVLM과 타 기법 사이에 큰 성능 차이를 보임
- LLM 가이드 접근에서 MyVLM이 BLIP2보다는 44%, LLaVA 보다는 30% 더 향상된 성능을 보임
- 사람에 대해서는 BLIP에서 Simple Replacement 기법과 MyVLM이 유사한 성능을 보이지만 LLaVA에서는 MyVLM이 다른 기법들에 비해 월등히 좋은 실력을 보임
- 이는 LLaVA에 의해 생성되는 캡션은 추상적인 캡션들이 많은 반면 BLIP-2의 경우 더욱 단순한 캡션을 생성하기 때문으로 생각됨
- 위 결과를 통해 MyVLM이 타 기법에 비해서 더욱 강인한 결과를 보인다는 것을 확인
- Recall 측면에 있어서 MyVLM과 타 기법 사이에 큰 성능 차이를 보임
- 다음으로 4개, 2개, 1개의 이미지를 사용하여 컨셉 임베딩을 학습했을 때 성능을 확인 → 표 2 참고

- BLIP2와 LLaVA 모두 많은 학습 샘플을 사용할수록 성능 향상
- MyVLM은 여전히 모든 베이스라인들에 비해 크게 뛰어난 성능을 보임
- 추가적으로 개인화된 캡션과 (1) 입력 이미지, (2) 타겟 캡션 간의 유사도 계산
- 추가적인 이미지를 사용할수록 이미지와 텍스트 유사도가 높아지는 것을 확인할 수 있음 → 일반화 성능 향상
- 이는 MyVLM이 개인화 컨셉 생성에 있어 효율성을 보임을 확인할 수 있음
3.2. MyVLM for Additional Applications
Personalized Visual Question-Answering
- 우선 MyVLM이 개인화된 시각적 질의응답을 수행하는데 사용할 수 있는지 확인 → 그림 7 참고

- MyVLM을 몇몇 사용자별 컨셉에 적용 → 가수의 사람들이 있는 경우에도 타겟 컨셉과 관련된 질의응답을 정확하게 수행 (1, 2번 칼럼 결과)
- 타겟 컨셉이 이미지의 작은 부분에 위치해도 정확한 질의응답 수행 (3, 4번 칼럼 결과)
- 이를 통해 MyVLM이 타겟 컨셉과 관련된 특징을 신뢰도 있게 파악하고 새로운 장면에서 컨셉에 대해 정확하게 식별하고 위치를 파악하는 것을 알 수 있음
Personalized Referring Expression Comprehension
- 그림 8을 보면 Referring Expression Comprehension 문제에 개인화를 적용하여 MyVLM과 MiniGPT-v2를 통해 얻은 캡션 결과를 확인할 수 있음

- 결과에서 볼 수 있듯이 MyVLM은 개인화된 캡션을 제공할 뿐 아니라 직접적인 정보 없이도 이미지 내에서 컨셉의 위치를 도출하는 것을 확인할 수 있음
- 또한 MiniGPT-v2가 다수의 문제를 해결할 수 있는 능력이 있으므로 이를 MyVLM과 결합하여 적은 변경을 통해 개인화 기술을 다양한 문제에 사용할 수 있음
4. Limitations
- MyVLM은 기존의 VLM을 통해 사용자와 개인화된 상호작용이 가능한 능력이 있음
- 그러나 몇몇의 한계점들을 확인할 수 있음 → 그림 9 참고

- 우선 VLM의 내재젹인 편향에 의존하는 경향이 있음
- 예를 들어 남자와 여자가 한 이미지 안에 있으면 커플이나 부부라고 해버림
- 이는 개인화된 캡션 생성에 있어 부적절한 가정일 수 있음
- 두번째로 MyVLM은 컨셉 헤드의 품질에 의존함
- 타겟 컨셉에 대한 인지를 실패하거나 관계없는 대상에 대해서 인지하는 경우 잘못된 응답을 수행
- 그러나 컨셉 헤드가 새로운 이미지에 잘 일반화되며 이후 오픈셋 인지에 대한 성능이 향상되면 강인성이 높아질 것으로 예상
- 세번째로 본 논문에서 다양한 일반화 향상 기법을 제안했지만 여전히 학습 중에 컨텍스트를 잘못 인지하는 경우가 있음
- 예를 들어 뉴욕에서 학습된 이미지 묘사가 있는 경우 MyVLM이 새로운 캡션에 대해서도 뉴욕이라는 단어를 추가할 수 있음
- VLM의 어텐션 과정에 대해 추가적인 regularization 기법을 추가하는 방식으로 해당 문제 완화가 가능할 것으로 생각
- 네번째는 많은 사람이 있을 때 타겟을 식별하는 것에 어려움이 있을 수 있음
- S*을 다른 여성으로 판단하고 응답
- 컨셉 임베딩에 대한 학습 데이터에 추가적인 증강 (Augmentation)을 적용하여 여러운 문제 성능을 향상시킬 수 있음
- 우선 VLM의 내재젹인 편향에 의존하는 경향이 있음
5. Conclusions
- 논 논문은 비전-언어 모델에 대한 개인화 아이디어를 소개 → VLM이 사용자별 컨셉을 이해하고 추론
- 개인화된 캡셔닝과 VQA를 수행하는 MyVLM 제안
- 컨셉에 대한 몇장의 이미지만 주어지면 고정된 VLM의 외부에 컨셉 헤드의 몇몇 세트만 추가하여 유저별 컨셉을 인지할 수 있음
- VLM의 중간 특징 공간 내에 임베딩 벡터를 학습 → 언어 모델이 생성된 응답에 자연스럽고 정확하게 컨셉에 대한 내용을 통합할 수 있도록 함
- 비전-언어 모델의 개인화는 사람과 컴퓨터 간의 상호작용에서 더욱 의미있는 새로운 기회를 제공할 것으로 생각됨!
Appendix
A. Societal Impact
- 비전-언어 모델을 개인화하는 것은 사람과 컴퓨터 간 상호작용에 많은 의미를 제공 → 더욱 개인적인 경험과 관계에 가깝게 함
- 이런 개인화된 모델들은 사용자를 더욱 잘 지도할수도 있고 특수한 필요를 제공할수도 있음
- 그러나 개인화는 사생활에 대한 문제 발생 가능 → 모델이 개인적인 데이터에 접근하도록 해야함
- 추가적으로 사용자의 개인적인 컨텐츠나 관계에 대해 부정적인 피드백을 제공할 수 있다는 위험이 있음
- 이에 따라 비전-언어 모델의 개인화에 대해서 사용자 데이터와 모델의 행동 모두에 대해 보호하는 것이 중요함
B. Additional Details
B.1. Vision-Language Models
VLM Architectures
- Transformers 라이브러리에서 제공하는 BLIP-2 구현체 사용 → BLIP-2에 FLAN-T5 XL 언어 모델 적용
- LLaVA에 대해서는 공식 구현체 사용 → LLaVA-1.6 (언어 모델: Vicuna-7B)
- 모든 모델은 메모리 감소를 위해 half-precision을 적용하여 실행
- BLIP-2와 LLaVA 모두 언어 모델의 응답에 대한 토큰은 최대 512개 사용
- LLaVA에 대해서는 temperature를 0.2로, top-p를 0.7로 설정
B.2. Training
Concept Head Training: People
- 이미지에서 유저별 인물을 인지하기 위해 사전학습된 얼굴 탐지 모델과 얼굴 인식 모델 사용
- 특정 인물에 대해 적은 수의 데이터셋이 주어졌을 때 (1-4장) 타겟 인물에 대한 얼굴의 임베딩을 추출 및 저장
- 만약 새로운 임베딩이 저장된 임베딩들과 비교했을 때 사전에 정의한 거리 (distance) 내에 들어오는 경우, 해당 인물이 이미지 내에 있다고 판단
- 경험적으로 거리에 대한 기준값은 0.675로 정의
- 각 인물에 대해 다른 컨셉 헤드를 적용
Concept Head Training: Objects
- 물건을 인지하기 위해 제로샷 분류와 검색 문제에 대한 SOTA 대형 비전 모델 모델 사용 → DFN5B CLIP-ViT H/14 모델
- 얼굴의 임베딩 공간과 다르게 해당 모델로 부터 직접적으로 도출된 이미지 특징을 사용하는 것은 여전히 유사한 물건과의 구분에 효율적이지 않음
- 이에 따라 고정된 비전 인코더에서 추출된 [CLS] 토큰에 대해 단일 선형 레이어 학습 → 타겟 컨셉을 포함한 4개의 이미지와 포함하지 않은 150개의 이미지 (유사 카테고리로 검색하여 사용)로 학습 수행
- ex. 특정 강아지의 사진 4장과 해당 강아지가 포함되지 않은 다른 강아지 사진 150장 사용
- 학습은 500 스텝 동안 수행 → Cross entropy 손실함수 사용, 배치 사이즈 = 16, AdamW optimizer, 학습률 = 0.001이며 Cosine annealing schedule을 사용하여 감소시킴
- 해당 단일 레이어 학습은 1분 안에 수렴
- 추론시에 새로운 이미지가 주어지면 먼저 고정된 비전 인코더에서 이미지 특징을 추출하고 모든 컨셉 분류기를 적용
- 모든 선형 분류기에 특징을 통과시키는 것이 특징을 추출하는 것 자체에 비해 훨씬 빠름
- 모든 분류기에 대해서 기준값은 0.5로 설정
Concept Embedding Optimization
- MyVLM을 BLIP에 적용할 때 물건의 학습에서는 75번의 최적화 스텝을 수행하고 사람의 학습에서는 100번의 최적화 스텝 수행
- LLaVA에서는 사람와 물건 모두 100번의 최적화 스텝 수행
- 최적화 관련 설정 → AdamW, 고정된 학습률=1.0, 안정적 수렴을 위해 clip grad를 max L2 norm 0.05로 적용
- Regularization 손실함수에 대해서는 가중치 요소를 BLIP에 대해서는 $\lambda=0.04$, LLaVA에 대해서는 $\lambda=0.25$로 설정
- 최적화 과정에서 추가적인 안정화를 위해 입력 이미지와 타겟 캡션에 대해 증강 (Augmentation)을 수행 → 언어적인 명령은 고정 (”Please caption this image of S*”)
- 이미지에 대해서 랜덤 horizontal flip, 랜덤 회전, 밝기 jittering 적용
- 타겟 캡션의 증강을 위해서는 LLM에 캡션에 대해 컨셉 식별자는 고정한 상태로 4 종류의 다른 버전을 생성해달라고 요청
- 각 최적화 스텝에서 5개의 증강된 캡션 중 하나를 랜덤하게 선택하여 정답 캡션으로 사용 → 현재 스텝에 대한 손실함수 계산
- 이는 특정 타겟 출력으로부터 컨셉을 분리하며 오버피팅 방지 및 일반화 성능을 개선
- 증강된 타겟 캡션을 생성하기 위해서 GPT-4를 사용했으며 다음과 같은 명령으로 캡션 생성을 요청

Choosing the Concept Identifier
- 컨셉에 대한 식별자는 MyVLM의 결과에 영향을 미칠 수 있음 → 예를 들어 너무 긴 단어처럼 모델이 생성하기 어려운 단어를 사용하는 경우 결과에 악영향을 줄 수 있음
- 물건에 대한 출력의 개인화를 위해서 text-to-image에서 사용하는 개인화 기법을 사용하며 컨셉 식별자를 “sks”로 사용 → Dreambooth에서 사용한 것과 동일
- 특정 인물에 대한 개인화 이미지에 대해서는 자연스럽고 짧은 이름을 컨셉 식별자로 사용 → 남자에 대해서는 “Bob”, 여자에 대해서는 “Anna”를 사용
- VQA에서는 모델이 컨셉의 이름에 의한 성별에 편향에 의존하지 않도록 물건과 인물 모두 “sks”를 컨셉 식별자로 사용
B.3. Dataset & Experiments
MyVLM Dataset
- 총 45개의 사용자별 컨셉 수집 → 29개의 물건, 16명의 인물
- 데이터셋은 350개의 물건 이미지와 330개의 인물 이미지 사용 → 각각은 컨셉 식별자를 포함하는 개인화 된 캡션을 포함
- 각 물건의 샘플 이미지 참고 → 그림 10
Personalized Captioning Baselines
- 베이스라인에 대해서 각 컨셉에 대해 GPT-4로 생성한 키워드를 사용
- GPT-4에 컨셉에 대해 잘린 이미지를 제공하고 다음의 프롬프트를 입력

- 단순 변경 (Simple Replacement) 기반 베이스라인
- BLIP-2나 LLaVA를 통해 생성된 원본 캡션들에 키워드가 하나라도 있는 경우 컨셉 식별자를 삽입
- LLM 기반 변경 베이스라인
- Mistral-7B-Instruct-v0.2를 사용하고 다음의 입력을 프롬프트로 사용

- Mistral의 출력을 LLM 가이드 베이스라인의 출력으로 반환
- Mistral-7B-Instruct-v0.2를 사용하고 다음의 입력을 프롬프트로 사용
Evaluation Protocol
- 컨셉 임베딩을 5가지 다른 시드로 학습하고 각각 4개의 다른 학습 샘플들을 샘플링하고 남은 이미지들을 통해 평가 수행
- 2,429개의 평가 이미지들을 사용 - 1,164개의 유저별 물건과 1,265개의 인물
- 인물의 학습셋에 대해서는 랜덤하게 4개의 이미지를 선택, 물건에 대해서는 컨셉 임베딩을 학습할 때 동일한 4개의 이미지 셋을 선형 분류기 학습에 사용
- 정량 지표 계산을 위해서는 다음의 모델들을 사용
- 텍스트-이미지 유사도 계산에는 OpenAI의 CLIP ViT L/14를 사용 → 336x336 해상도
- 문장 유사도 계산에는 BERT sentence transformer 사용
Personalized Visual Question-Answering
- 개인적인 시각적 질의응답에 대해서 개인화된 캡셔닝과 동일한 과정을 가지지만 컨셉 임베딩 최적화에 사용하는 언어적인 명령과 타겟을 변경
- 최적화에 사용하는 명령의 10가지 프롬프트 세트에 대해서는 표 3 참고
- 각 질문에 대한 타겟을 얻기 위해 이미지와 언어 명령을 기존 LLaVA 모델에 입력하고 타겟 응답을 취득
- 그리고 각 학습 스텝에서 10가지 프롬프트와 타겟들 중 하나를 랜덤하게 선택
- 이는 최적화 과정에서 원치않는 편향을 만들 수 있음 → LLaVA가 주어진 질문에 대해 언제나 정확하게 답변하지 않을 수 있음
- 더욱 나은 결과를 위해 명령과 타겟의 세트를 확장하는 방법이 있지만 이는 추후 연구에서 다룸
반응형
'논문 리뷰 > Multi-Modal' 카테고리의 다른 글
| Visual SKETCHPAD: Sketching as a Visual Chain of Thought for Multimodal Language Models (0) | 2025.01.21 |
|---|---|
| SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities (4) | 2024.09.01 |
| [LLaVA 1.5] Improved Baselines with Visual Instruction Tuning (7) | 2024.09.01 |
| [LLaVA] Visual Instruction Tuning (4) | 2024.08.31 |
| [SIGLIP] Sigmoid Loss for Language Image Pre-Training (1) | 2024.08.31 |



