
- Link: https://arxiv.org/pdf/2310.03744.pdf
- 프로젝트 링크: https://llava-vl.github.io/
- 깃허브: https://github.com/haotian-liu/LLaVA
0. Abstract
- 대형 멀티모달 모델 (LMM, Large Multimodal Models)는 최근 시각적인 instruction 튜닝에서 큰 발전을 보임
- 이런 측면에서 LLaVA의 완전 연결 비전-언어 크로스 모달 커넥터 (fully-connected vision-language cross modal connector)는 강력한 성능과 데이터 효율성을 보임
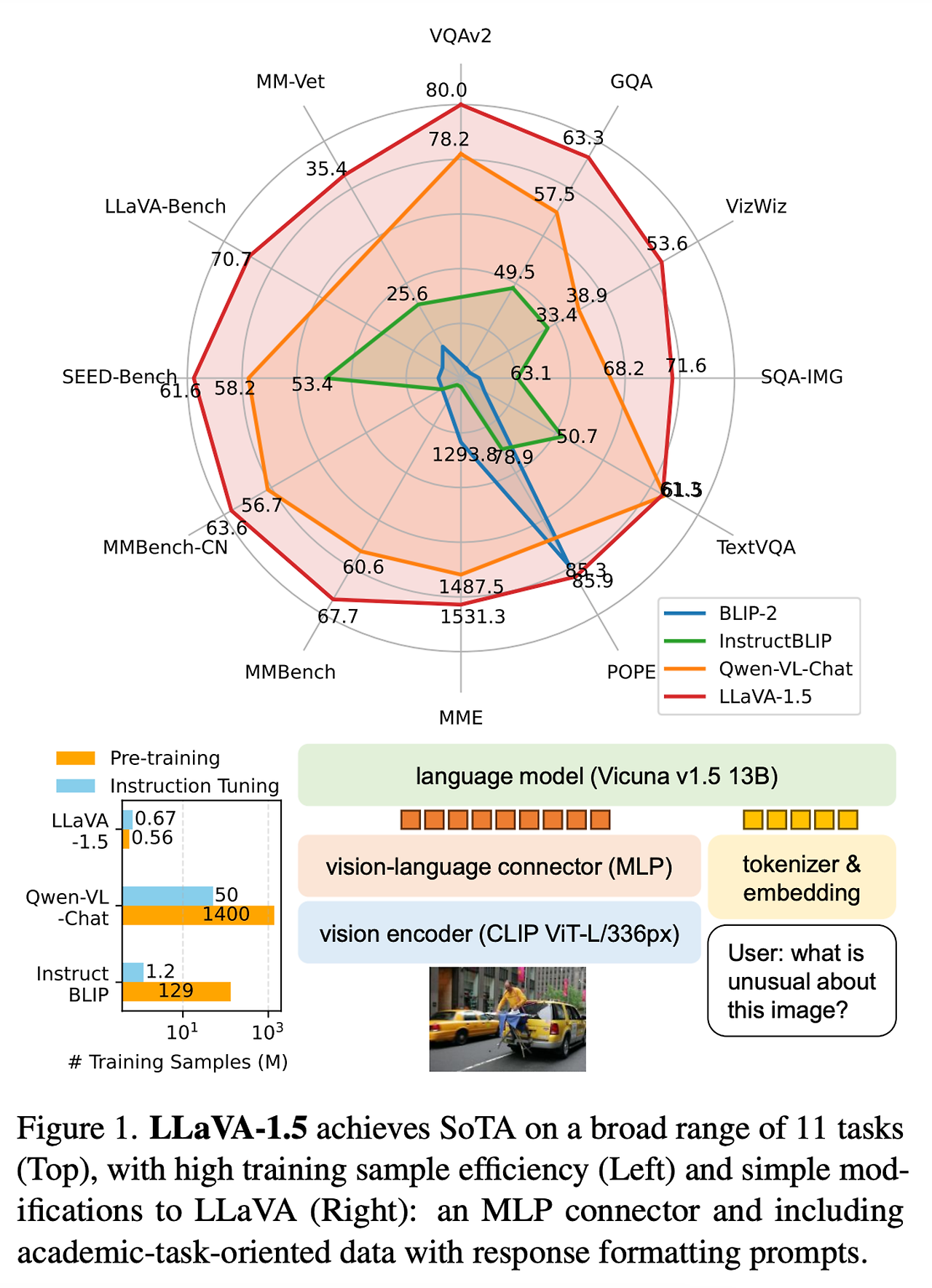
- LLaVA에 대해 간단한 변경만 수행하여 11개의 벤치마크에서 최신의 성능을 달성하는 베이스 라인 구축
- MLP projection과 CLIP-ViT-L-336px 사용
- 학술 문제 중심의 VQA 데이터셋을 단순한 응답 포맷 프롬프트와 함께 추가
- 13B 체크포인트는 1.2개의 공개된 데이터를 사용했으며 하나의 8-A100 노드를 사용하여 ~1일 정도 학습
1. Introduction
- 최근 LMM의 연구는 시각적인 instruction 튜닝에 중점적으로 수렴
- LLaVA와 MiniGPT-4와 같은 기법들이 instruction-following과 시각적인 추론 능력에서 인상적인 결과를 보임
- 최근의 기법들은 사전학습 데이터나 instruction-following 데이터의 증가, 시각적 인코더나 언어 모델의 발전 등을 통해 성능을 향상시킴
- 본 논문은 LLaVA 프레임워크를 기반으로 더 강력하고 실현가능한 기법을 제안 → 두개의 단순한 개선 제안
- MLP cross-modal connector
- 학술적인 문제와 연관된 데이터 (e.g. VQA)
- 위 기법들을 LLaVA에 적용하는 경우 더 나은 멀티모달 이해 능력 발생
- 특별하게 디자인된 이미지 resampler를 수억 혹은 수십억의 이미지-텍스트 쌍 데이터에 대해 학습하는 InstructBLIP이나 Qwen-VL과는 다르게 LLaVA는 LMM을 위한 단순한 구조를 가지며 600K개의 이미지-텍스트 쌍을 통해서 단순한 완전 연결 투영층(fully connected projection layer)만 학습
- 최종 모델은 8-A100 머신에서 ~1일만에 학습을 수행했으며 넓은 범위의 벤치마크에서 최신 성능 달성
- 또한 Qwen이 학습에 사내 데이터를 포함한 것과 다르네 LLaVA는 오직 공개된 데이터만 사용
2. Background
Instruction-following LMM
- LMM을 위한 공통적인 구조는 다음의 요소들을 포함
- 시각적인 피처를 인코딩하기 위한 사전학습된 시각적 백본 모델
- 사용자의 명령을 이해하고 응답을 생성하기 위한 사전 학습된 대형 언어 모델 (LLM)
- 비전 인코더의 출력을 언어 모델과 align하는 비전-언어 크로스-모달 커넥터
- 그림 1에서 볼 수 있듯이 LLaVA는 LMM을 위한 가장 단순한 구조 중 하나이며 선택적으로 시각적 패치의 수를 줄이기 위한 시각적 리샘플러 (e.g. Qformer)가 사용될 수 있음
- 명령을 따르는 LMM을 학습하는 것은 일반적으로 두 단계로 구성됨
- 비전-언어 정렬 (alignment) 사전학습 단계를 통해 이미지-텍스트 쌍에서 시각적 피쳐가 언어 모델의 단어 임베딩 공간에 정렬하도록 함
- 시각적인 instruction 튜닝 단계는 시각적인 명령에 대해 모델을 튜닝 → 모델이 시각적인 컨텐츠를 포함하는 사용자의 다양한 명령을 수행하는 것이 가능
Multimodal instruction-following data
- 많은 자연어 관련 연구들에서 instruction-following 데이터가 모델의 성능에 큰 영향을 미치는 것을 확인할 수 있음
- LLaVA의 데이터 처리 방법
- 텍스트만 지원하는 GPT-4를 이용해서 COCO 바운딩 박스와 캡션 데이터를 instruction-following 데이터 (대화 스타일 QA, 자세한 묘사, 복잡한 추론)로 확장
- InstructBLIP의 경우 학술적인 문제 중심의 VQA 데이터셋을 통합하여 모델의 시각적인 능력을 향상
3. Improved Baselines of LLaVA
- LLaVA는 다수의 실생활 관련 instruction-following 벤치마크에서 심지어 이후에 나온 모델들보다도 더 좋은 성능을 보인 반면 주로 단답형의 응답을 요구하는 학술적인 벤치마크에서는 부족한 성능을 보임
- 후자는 LLaVA가 큰 규모의 데이터로 사전학습 되지 않았음을 보임
- 이런 측면에서 본 논문은 데이터, 모델, 입력 이미지 크기의 확장에 대한 효과를 살펴봄 → 표 1 참고
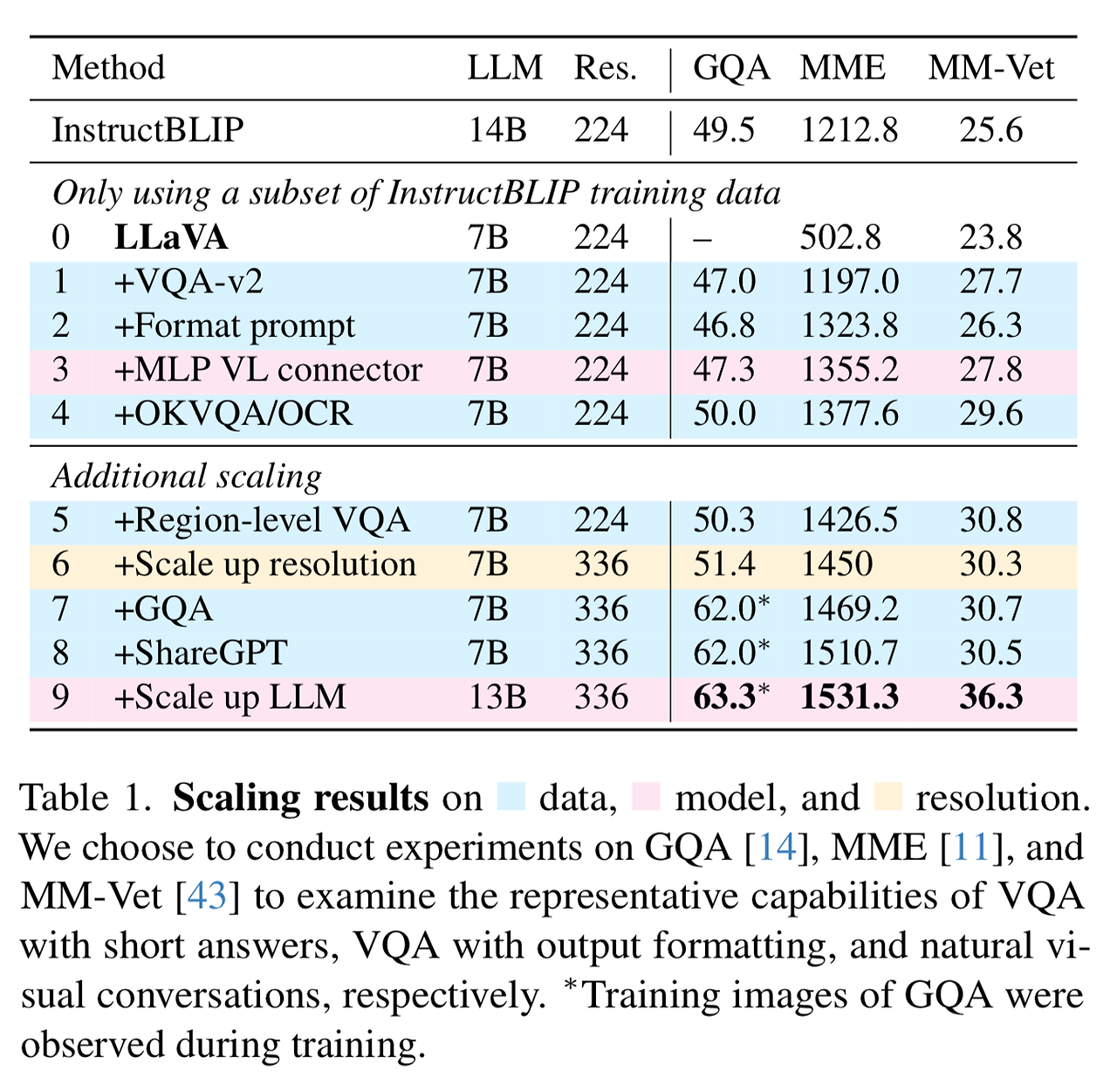
- 그리고 최종 모델을 12개의 벤치마크 셋에서 기존 LMM 모델들과 성능 비교 → 표 2 참고
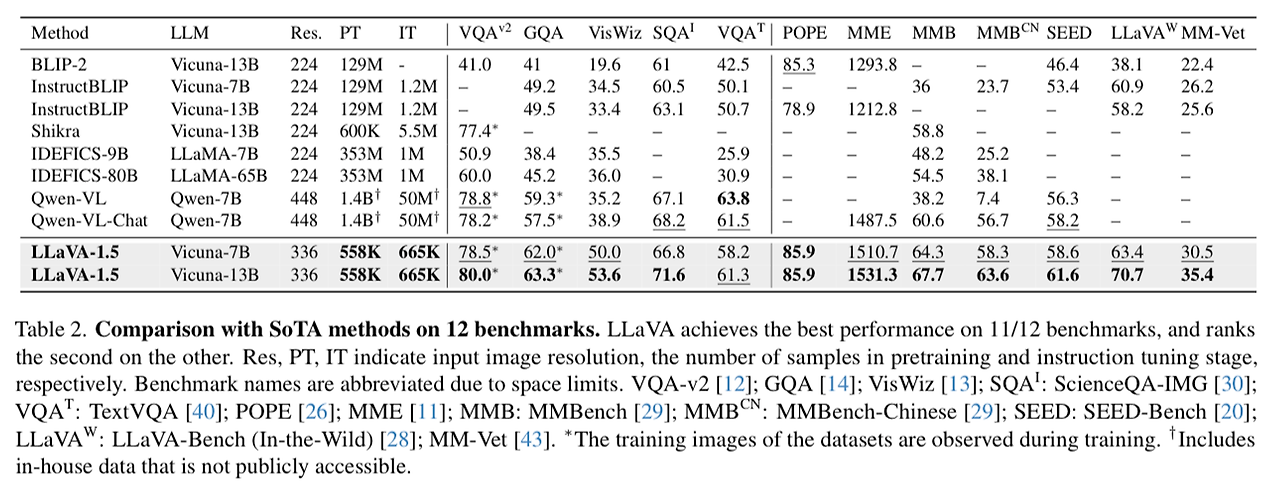
- 해당 결과들을 통해 시각적인 instruction tuning 문제에 대해 LLaVA의 구조가 강력하며 데이터 효율적임을 보임
- 다른 모든 기법들에 비해 훨씬 적은 계산량과 학습 데이터만을 통해서 최고의 성능을 보임
Response formatting prompts
- InstructBLIP과 같은 접근이 짧은 형식과 긴 형식의 VQA에서 다음과 같은 이유들로 대응하지 못하는 것을 확인
- 응답 형식에 대한 애매한 프롬프트
- 예시: Q: {질문 내용} A: {응답 내용}
- 이런 프롬프트는 원하는 출력의 형식을 명확히 하지 않으며 LLM이 짧은 형식의 응답에 오버피팅되도록 할 수 있음
- LLM을 파인튜닝 하지 않음 (not finetuning the LLM)
- 첫번째 이슈는 instruction-tuning에 대해 오직 Qformer만 파인튜닝하는 InstructBLIP에 의해 악화됨
- 이는 Qformer의 시각적 출력 토큰이 LLM의 출력 길이를 짧은 형식과 긴 형식을 모두에 대해 제어할 수 있도록 하는 것을 요구 → 하지만 LLaMA와 같은 LLM과 비교했을 때 Qformer는 이를 수행하기 위한 능력 부족
- 정량적인 예시를 위해 표 6 참고
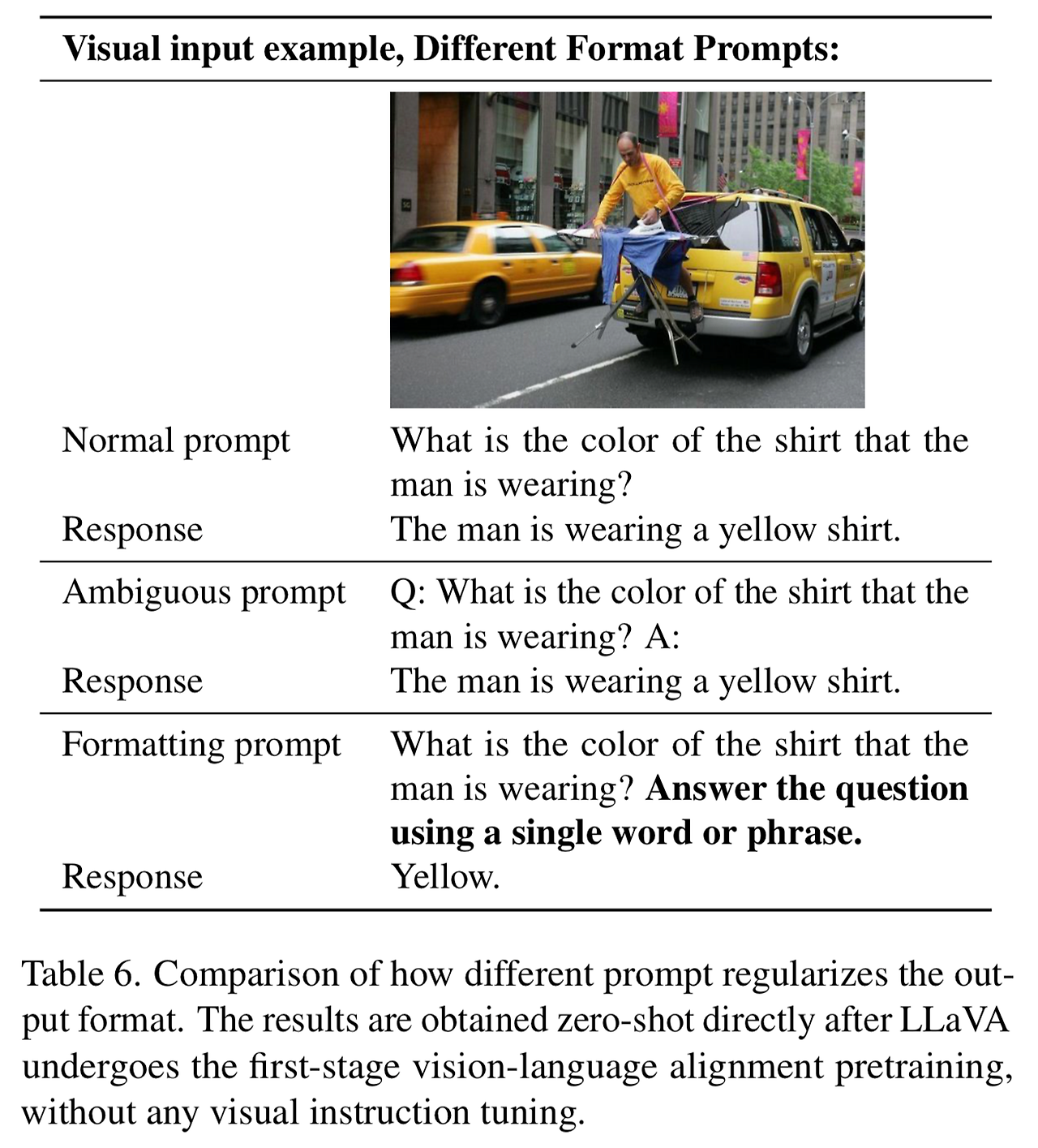
- 응답 형식에 대한 애매한 프롬프트
- 이를 해결하기 위해 출력의 포맷을 명확히 지시하는 단일 응답 포맷 프롬프트 사용
- 짧은 형식의 응답을 유도하는 경우 VQA 질문의 끝에 다음의 내용을 추가: 질문에 대해 한 단어나 구절로 답변해라 (원문: Answer the question using a single word or phrase)
- 이런 프롬프트를 사용하여 LLM을 파인튜닝 하는 경우 LLaVA는 사용자의 명령에 따라 적절하게 출력의 포맷을 조절
MLP vision-language connector
- 선형 투영 (linear projection)을 MLP로 변경하여 자가 지도 학습 (self-supervised learning)을 수행했을 떄 성능 개선에 영향을 받음
- 이에 따라 비전-언어 커넥터를 두 층의 MLP로 변경하는 경우 성능 개선을 확인 → 기존 선형 투영 디자인과 비교했을 때 LLaVA의 멀티모달 능력을 개선
Academic task oriented data
- 추가적으로 학술적인 문제과 관련된 VQA 데이터셋 추가 → VQA, OCR, region-level 인지 → 모델의 다양한 능력을 향상시키기 위해 (표 1 참고)
- InstructBLIP에서 사용된 4개의 추가적인 데이터 포함: open-knowledge VQA (OKVQA, A-OKVQA), OCR (OCRVQA, TextCaps)
- InstructBLIP에서 사용한 데이터의 일부만을 사용했지만 LLaVA는 표 1의 모든 3개의 문제에서 이미 InstructBLIP의 성능을 능가 → LLaVA의 효율적인 구조를 보여줌
- 또한 region-level VQA 데이터셋 (Visual Genome, RefCOCO)를 추가하는 경우 세분화된 시각적 디테일을 지역화하는 모델의 능력 향상 (원문: improves the model’s capability of localizing fine-grained visual details)
Additional scaling
- 아래의 모든 변경 사항을 통합 → LLaVA-1.5
- 입력 이미지의 해상도를 증가시키는 것은 LLM이 명확하게 이미지의 디테일을 볼 수 있도록 함
- 그리고 추가적인 시각적 지식을 위해 GQA 데이터셋 추가
- ShareGPT 데이터 추가
- LLM의 크기를 13B로 증가시킴 → 시각적 대화 능력을 위해 기반 LLM의 능력의 중요성 평가
- 성능 확인 → 표 1의 마지막 두 행
- 기존 LLaVA의 능력을 월등히 뛰어넘는 인상적인 성능을 보임
4. Discussion
Comparison with SoTA
- LLaVA-1.5의 성능을 넓은 범위의 학술적인 VQA 벤치마크와 instruction-following LMM을 위해 제안된 벤치마크에서 테스트 → 총 12개의 벤치마크
- 본 논문의 기법이 12개 중 11개에서 가장 뛰어난 성능을 보였음 → 다른 기법들에 비해 적은 양의 사전 학습, 파일튜닝 데이터 사용
- LLaVA-1.5의 장점
- 가장 단순한 구조로 가장 뛰어난 성능을 보임
- 향후 연구를 위해 완전히 재현 가능하고 사용할만한 크기의 베이스라인을 제공
- 이 결과들은 또한 LMM의 능력 향상에 사전 학습보다 시각적인 instruction 튜닝이 더 중요한 역할을 담당하는 것을 보여줌
- LLaVA-1.5는 비록 7B 모델임에도 불구하고 80B IDEFICS 의 성능을 뛰어넘음
- IDEFICS: 크로스 모달 연결을 위해 수십억개의 학습 파라미터를 사용하는 Flamingo와 유사한 LMM
- 이는 멀티모달 instruction-following 능력 측면에서 비전 샘플러의 이점과 추가적인 대규모 사전 학습 필요성에 대해 다시 생각하도록 함
Zero-shot format instruction generalization
- LLaVA-1.5는 오직 제한된 수의 포맷을 가지는 명령들로 학습되었지만 다른 명령들로 일반화 됨
- VizWiz
- 제공된 정보가 질문에 대답하기에 불충분하여 모델의 출력이 “대답할 수 없음” 되도록 해야함
- 본 논문의 응답 프롬프트는 표 8의 내용 참고

- 모델이 대답할 수 없는 질문에 대해 대답할 수 없다고 응답하는 경우의 비율 증가 (11.1% → 67.8%)
- 추가적으로 LLaVA 1.5가 까다로운 질문 (표 3)에 대해 검증하거나 제한된 JSON 형식 (표 4)로 응답하는 정성적인 결과를 보임


Zero-shot multilingual capability
- 비록 LLaVA-1.5가 다국어 멀티모달 명령을 따르도록 파인튜닝 되지 않았지만 다국어 명령을 따르는 능력이 있는 것을 확인 → ShareGPT에 포함된 다국어 명령 때문에
- 모델이 MMBench에서 중국어로 일반화되는지 정량적으로 평가 수행 → MMBench의 질문을 중국어로 변환
- 놀랍게도 LLaVA-1.5는 Qwen-VL-Chat을 7.3% 앞서는 결과를 보임 (63.6% vs. 56.7%) → Qwern은 중국어 멀티모달 명령으로 파인튜닝 되었으나 LLaVA-1.5는 그렇지 않음
Computational cost
- LLaVA-1.5는 LLaVA와 동일하게 사전 학습 데이터로 LCS-558K를 사용하며 학습 iteration이나 배치 사이즈도 거의 유사하게 사용함
- 단, 이미지 입력의 해상도가 336px로 증가하면서 LLaVA-1.5의 학습이 LLaVA에 비해 ~2배 정도 소요 → 사전 학습 ~6 시간, 파인튜닝 ~20시간 (A100 x 8 사용)
Limitations
- LLaVA-1.5의 몇가지 한계점
- LLaVA는 전체 이미지 패치를 활용 → 잠재적으로 각 학습 iteration을 연장
- 시각적 리샘플러는 LLM의 시각적 패치의 수를 감소시키는 반면 동일한 양의 학습 데이터로 LLaVA만큼 효율적으로 수렴을 달성하지 못함 → 리샘플러의 학습 가능한 파라미터가 더 많기 때문으로 생각됨
- 이에 따라 더욱 샘플 효율적인 시각적 리샘플러의 개발이 instruction-following 멀티모달 모델의 확장에 기여할 것으로 생각됨
- LLaVA-1.5는 다수의 이미지를 처리할 수 있는 능력이 없음 → 원인: 해당 형식의 instruction-following 부족과 컨텍스트 길이의 한계 때문에
- LLaVA-1.5가 특정 도메인에서는 제한된 문제 해결 능력을 보임 → 더욱 좋은 언어 모델과 높은 품질, 타겟팅 된 튜닝 데이터를 사용하여 개선할 수 있음
- LLaVA는 할루시네이션이 발생하고 때로는 잘못된 정보를 도출하는 경우가 있으므로 정확성이 중요한 응용 분야 (e.g. 의료)에 사용할때는 주의해야함
- LLaVA는 전체 이미지 패치를 활용 → 잠재적으로 각 학습 iteration을 연장
'논문 리뷰 > Multi-Modal' 카테고리의 다른 글
| Visual SKETCHPAD: Sketching as a Visual Chain of Thought for Multimodal Language Models (0) | 2025.01.21 |
|---|---|
| MyVLM: Personalizing VLMs for User-Specific Queries (10) | 2024.09.01 |
| SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities (4) | 2024.09.01 |
| [LLaVA] Visual Instruction Tuning (4) | 2024.08.31 |
| [SIGLIP] Sigmoid Loss for Language Image Pre-Training (1) | 2024.08.31 |



