반응형

0. Abstract
- 본 논문에서 제안하는 기법 - Sigmoid loss for Language-Image Pre-training(SigLIP)
- 기존 소프트맥스 정규화 (Softmax Normalization)을 사용하는 일반적인 contrastive 학습과 다르게 sigmoid 손실함수는 이미지-텍스트 쌍에 대해서만 연산 → 정규화를 위해 글로벌한 관점의 pairwise 유사도를 요구하지 않음
- Sigmoid 손실함수는 다음의 두가지 사항을 달성
- 효율적 연산을 통한 배치 사이즈의 증가
- 작은 배치 사이즈에서 좋은 성능을 달성
- Locked-image Tuning (LiT)을 사용하여 TPUv4 칩 4개 만으로 SigLiT 모델을 학습하였으며 이틀만에 ImageNet 제로샷 정확도에서 84.5%를 달성
- 또한 배치 사이즈를 백만까지 늘려가며 실험을 하여 배치 사이즈 증가에 대한 이점이 빠르게 사라지는 것을 확인했으며 배치 사이즈 32k 정도가 적절한 크기라는 것을 알게 되었음
1. Introduction
- Contrastive 사전 학습
- 인터넷 상의 다량의 이미지와 텍스트의 쌍에 대한 학습을 수행
- 이미지와 텍스트 쌍 데이터를 이용하여 이미지와 텍스트를 위한 정렬된 표현 공간 (aligned representation space)을 동시에 학습
- 대표적인 기법 → CLIP, ALIGN
- 일반적인 contrastive 사전 학습의 학습 방법
- 이미지-텍스트 contrastive 목적함수를 사용
- 이미지와 텍스트 임베딩에 대해 매칭되는 (positive) 이미지-텍스트 쌍에 대해서는 align하고 관계없는 (negative) 이미지-텍스트 쌍은 임베딩 공간에서 서로 멀어지도록 학습
- 기존에는 이를 배치 단계의 Softmax 기반 contrastive 손실함수를 통해 학습
- 하지만 Softmax를 기반으로 하는 단순한 구현은 불안정함 → 이를 안정화하기 위해서 Softmax 적용 전에 입력의 최대 값을 빼주는 과정을 수행하는데 이를 위해 전체 배치에 대한 추가적인 연산이 필요
- 본 논문에서는 더욱 단순한 대안 기법을 제안: Sigmoid 손실함수
- 해당 기법은 전체 배치에 대한 연산을 요구하지 않으며 이를 통해 분산된 손실함수 연산에 대한 구현을 굉장히 단순화하며 효율성을 증대시킴
- Sigmoid 기반의 손실함수를 이미지-텍스트 학습을 위한 두개의 기법에 적용: CLIP과 LiT
- 해당 기법들을 각각 Sigmoid Language Image Pretraining(SigLIP)과 Sigmoid LiT (SigLiT)으로 명명
- 본 논문에서 확인한 결과들
- Sigmoid 손실함수가 배치사이즈가 16k 보다 작은 경우에 Softmax 손실함수보다 확연하게 좋은 성능을 보임
- 배치 사이즈가 커질수록 성능이 유사해지긴 하지만 Sigmoid 손실함수는 symmetric하며 단일 연산만을 수행하며 Softmax 손실함수보다 더 적은 메모리를 요구한다는 장점이 있음 → 이를 통해 SigLiT 모델의 경우 백만 크기의 배치에 대해 성공적인 학습을 수행
- 또한 본 논문에서는 합리적인 배치 크기를 발견 → 32k이면 이미지 텍스트 사전 학습에 충분한 성능을 보임
- 표 1은 TPUv4 칩을 통한 합리적 규모의 연산 장치를 기반으로 한 이미지-텍스트 사전 학습 세팅의 결과를 보여줌
- SigLiT은 놀라운 효율성을 보이며 4개의 칩 만으로 하루만에 ImageNet에서 79.7%의 제로샷 성능을 달성
- SigLIP은 처음부터 학습을 수행하여 더 많은 연산량을 요구 → 32개의 TPUv4 칩을 사용하여 5일 동안 학습한 결과 73.4%의 제로샷 성능을 달성
- 기존에 FLIP이나 CLIP이 256개의 TPUv3 코어를 사용하여 각각 5일과 10일 동안 학습한 것에 비해서 훨씬 효율적인 결과를 보임

2. Method
- Contrastive 학습의 적용 방법 및 가정
- 이미지-텍스트 쌍에 대한 미니배치 $\mathcal{B} = \{(I_1, T_1), (I_2, T_2), …\}$이 주어졌을 때 사전학습의 목적은 매칭된 쌍인 $(I_i, T_i)$의 임베딩이 서로 align 되도록 하는 것
- 반면 매칭되지 않는 쌍 $(I_i, T_{j≠i})$의 임베딩은 서로 멀어지도록 함
- 가정: 모든 이미지 $i$에 대해 다른 이미지 $j$와 연관된 텍스트는 $i$와 연관되어 있지 않으며 그 반대의 경우도 마찬가지 → 해당 가정은 일반적으로 노이지하며 불완전
2.1. Softmax Loss for Language Image Pre-training
- Softmax 손실함수를 사용하는 경우 이미지 모델 $f(\cdot)$과 텍스트 모델 $g(\cdot)$은 다음을 최소화하도록 학습

- $x_i = \frac{f(I_i)}{||f(I_i)||_2}$이고 $y_i = \frac{g(T_i)}{||g(T_i)||_2}$
- 본 논문에서 이미지를 위해서는 Vision Transformer 구조를 사용하며 텍스트를 위해서는 Transformer 구조를 사용
- Softmax 손실함수의 비대칭성 (asymmetry)으로 인해 정규화가 독립적으로 2번 수행되어야 함 → 이미지들에 대해서와 텍스트들에 대해서 각각 수행 (모든 positive pair의 유사도를 모든 negative pair로 정규화)
- 스칼라 $t$는 $\exp (t’)$에 의해 파라미터화 됨 → $t'$는 학습 가능한 파라미터
2.2. Sigmoid Loss for Language Image Pre-Training
- 본 논문에서는 Sigmoid 기반 손실함수를 제안
- Global normalization factor를 필요로 하지 않는 단순한 대안 기법
- 텍스트-이미지 쌍을 독립적으로 처리 → 효율적으로 문제를 모든 데이터 쌍의 조합에 대한 binary 분류 문제로 변환
- 매칭되는 쌍 $(I_i, T_i)$에 대해서는 양의 라벨을, 다른 모든 쌍 $(I_i, T_{j≠i})$에 대해서는 음의 라벨을 설정

- $z_{ij}$는 주어진 이미지, 텍스트 입력에 대한 라벨 → 매칭된 쌍에 대해서는 1, 그렇지 않은 경우 -1로 설정
- 초기화 설정
- 많은 음수들 때문에 큰 불균형이 발생하면서 이것이 손실함수에 큰 영향을 미침
- 이 편향을 해결하기 위해 추가적으로 temperature $t$와 유사한 학습 가능한 변수인 $b$를 추가
- 논문에서는 $t'$와 $b$를 각각 $\log 10$과 $-10$으로 초기화
- 이를 통해 학습이 비교적 prior와 가깝게 시작할 수 있으며 다수의 correction을 요구하지 않음
- 알고리즘 1 → 제안된 언어-이미지 사전학습을 위한 sigmoid 손실함수의 구현 pseudocode

2.3. Efficient “Chunked” Implementation
- Contrastive 학습은 일반적으로 데이터 병렬화를 사용
- 손실함수를 계산할 때 데이터를 D개의 장치에 나누는 경우 다음의 사항들이 필요함
- 모든 임베딩들을 비용이 높은 all-gathers로 모아줘야함
- 데이터 쌍 유사도의 메모리 집약적인 $|\mathcal{B}| \times |\mathcal{B}|$의 materialization
- 손실함수를 계산할 때 데이터를 D개의 장치에 나누는 경우 다음의 사항들이 필요함
- Sigmoid 손실함수는 메모리 효율적이고 빠르고 수치적으로 안정적인 구현이 가능하도록 변경할 수 있음 → 위의 두가지 이슈를 모두 해결
- 연산장치 당 배치 사이즈를 $b=\frac{|\mathcal{B}|}{D}$라고 했을 때 손실함수를 다음과 같이 재정의

- 이는 각 쌍이 손실함수에서 독립적인 항인 sigmoid 손실함수에서 특히 단순한 기법
- 그림 1이 해당 기법을 묘사하고 있음
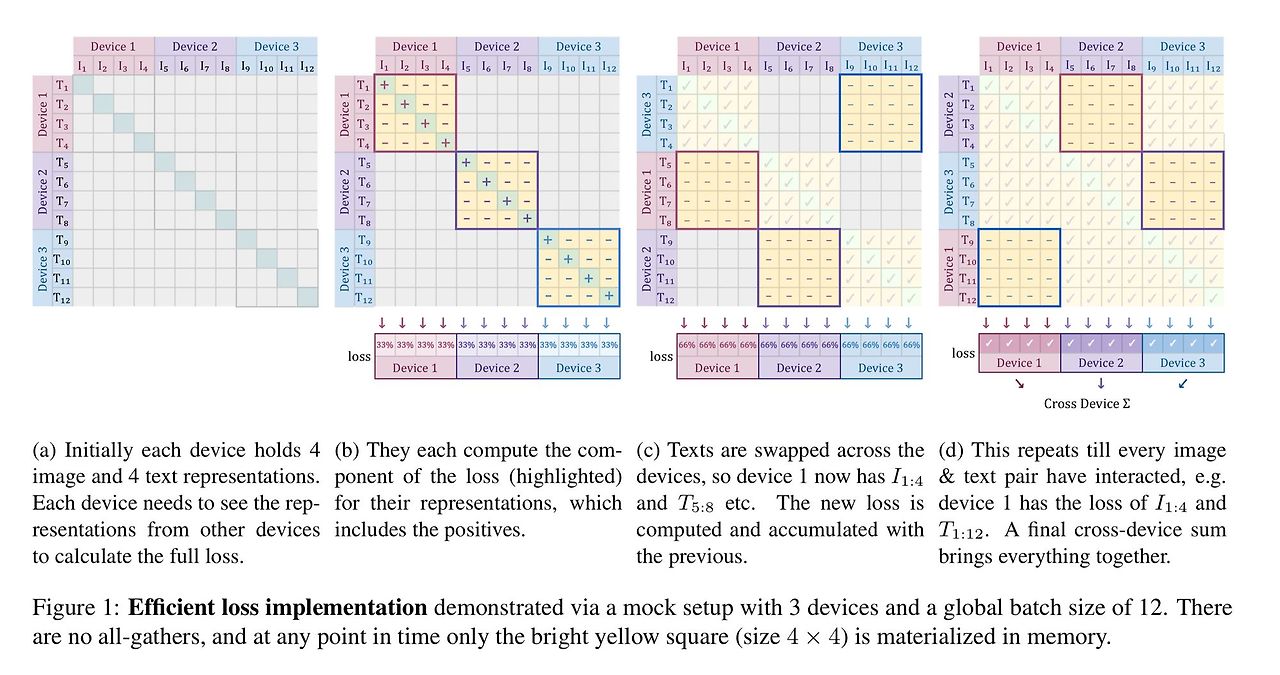
- 해당 기법에서 먼저 매칭되는 쌍과 b-1개의 매칭되지 않는 쌍에 대해 손실함수를 계산
- 그리고 표현들을 연산 장치에 대해 permute 수행 → 각 연산 장치들이 이웃 연산장치들로부처터 매칭되지 않는 쌍들을 취함 (합 B의 다음 단계)
- 그리고 손실함수가 각각의 부분들에 대해 계산됨 (합 C)
- 이는 각 연산장치에 대해 독립적으로 수행됨 → 각 장치는 이들의 로컬 배치 $b$에 대해 손실 함수를 연산
- 손실함수들은 모든 기기에 대해 단순히 합해질 수 있음 (합 A)
- 개별적인 collective permutes (합 B를 위한)는 빠르고 메모리 비용이 $|\mathcal{B}|^2$에서 $b^2$으로 감소 (합 C를 위해)
- 주로 $b$는 상수이며 $\mathcal{B}$는 accelerator의 수 증가에 의해 결정됨
- 배치 사이즈에 따라 이차적으로 (Quadratic) 메모리 사용량이 증가하므로 기존의 손실함수 계산은 확장을 위해 병목을 일으켰지만 이와 같은 chunked 접근은 상대적으로 적은 연산장치만으로 백만이 넘는 배치 사이즈 연산이 가능하도록 함
3. Results
- 제안된 SigLiT과 sigLIP의 성능을 다양한 방식으로 평가
- 모델의 평가를 위해 ImageNet 데이터에서 제로샷 전이 결과와 36개 언어로 구성된 XM3600 데이터에 대한 제로샷 검색 결과 사용
- ScalingViT-Adafactor Optimizer 사용
3.1. SigLiT: Scaling Batch Size to the Limit
- 배치사이즈를 512에서 1M까지 넓은 범위로 변경하며 실험 수행
- 결과는 그림 2의 왼쪽에서 확인할 수 있음

- 배치사이즈가 16k보다 작은 경우 sigmoid 손실 함수가 softmax 손실함수의 성능을 큰 차이로 능가
- 배치사이즈의 증가에 따라 softmax 손실함수가 빠르게 그 성능을 따라잡고 충분히 큰 배치사이즈에서는 sigmoid 손실함수보다 아주 조금 부족한 성능을 보임
- 하지만 큰 배치사이즈에서도 SigLIP의 방식을 사용하는 것이 좋음 → 단순하며 연산을 절약하고 직관적으로 메모리 효율적인 구현을 수행할 수 있음
- Contrastive 학습은 큰 배치사이즈에서 이점이 있다는 의견이 있지만 대부분의 기존 연구들에서는 64k 배치사이즈 연산만 수행
- 하지만 본 논문에서는 배치 사이즈를 100만까지 증가시켜서 사용 → 이를 통해 32K 배치사이즈 이상부터는 성능이 거의 수렴하는 결과를 보임
- 32K 이상부터는 아주 약간의 성능 향상만 있고 성능은 256k 정도의 배치사이즈에서 가장 좋은 성능을 보임
- 그림 3은 다른 배치사이즈에서 학습을 수행하는 기간에 대한 영향을 보여줌
- 충분히 오래 학습하는 경우 262k 배치 사이즈가 8k 배치 사이즈의 성능을 매우 능가하는 것을 확인할 수 있음
- 짧은 학습 기간에 대해서는 큰 배치 사이즈가 업데이트의 수가 상대적으로 적으므로 성능 향상까지 추가적인 시간이 필요
3.2. SigLIP: Sigmoid Loss is Beneficial for Language-Image Pre-training
- WebLI 데이터셋을 사용하여 SigLIP 모델을 사전학습 → 영어 이미지-텍스트 쌍만을 사용
- 적당한 크기의 모델 사용: 이미지 임베딩을 위해 B/16 ViT, 텍스트 임베딩을 위해 B-사이즈 transformer 사용
- 입력 이미지는 224x224 해상도로 크기 변경
- 텍스트는 32k vocabulary sentencepiece tokenizer에 의해 토큰화 됨
- 그림 2의 중간이 SigLIP의 결과를 보여줌

- 32k 배치 사이즈 이전까지는 SigLIP이 CLIP의 성능을 능가
- 또한 sigmoid 손실함수의 메모리 효율성이 더욱 큰 배치 사이즈 연산이 가능하도록 함
- 4개의 TPU-v4 칩으로 Base SigLIP에 대해 4096의 배치 사이즈 연산이 가능하지만 CLIP의 경우 2048개의 배치 사이즈만 사용 가능
- 배치가 증가함에 따른 변화
- softmax 손실함수와 sigmoid 손실함수 사이의 성능을 줄어들게 됨
- SigLIP 성능의 경우 배치 사이즈 32k에서 가장 좋은 성능을 보이고 softmax 손실함수의 경우 98k 배치사이즈에서 가장 좋은 성능을 보이지만 그것도 sigmoid 기반의 성능을 압도하지는 못함
- 307k개 만큼 큰 배치사이즈를 사용하는 경우는 두 모델 모두 성능이 오히려 저하되는 결과를 보임
3.3. mSigLIP: Multi-lingual pre-training
- WebLI 데이터셋의 100개의 언어를 유지한채로 학습을 수행
- 여기서는 두 토크나이저의 성능을 검증
- 32k 토큰의 작은 다국어 vocabulary를 가지는 토크나이저
- 250k 토큰의 큰 다국어 vocabulary를 가지는 토크나이저
- B-사이즈 ViT와 텍스트 모델을 900M의 데이터들로 학습했지만 큰 토크나이저로 학습했을 때 1% 정도의 성능 향상만 있었음
- 하지만 큰 vocabulary size를 가지는 경우 토큰 임베딩 또한 커지게 됨
- 일반적인 토큰 임베딩 방법
- 다국어 모델을 학습하기 위한 $N \times W$ 크기의 토큰 임베딩 룩업 테이블을 저장
- $N$은 위에서 언급한 vocab 사이즈이고 $W$는 텍스트 모델의 임베딩 차원
- 본 논문에서는 메모리 절약을 위해 “bottlenecked” 토큰 임베딩의 사용을 제안
- $N \times K$ 임베딩 행렬과 추가적인 $K \times W$ 프로젝션을 사용 → $K$를 $W$보다 훨씬 작게 설정
- 이 경우 bottleneck이 적용된 큰 다국어 vocab은 작은 다국어 vocabulary를 사용할때와 같이 스케일 업을 할 수 있음
- 예시: $W=768$의 베이스 구조와 $K=96$의 bottleneck 사이즈를 가진 경우 250k vocab을 사용했을 때에 비해 ImageNet 제로샷 전이 문제에 대해 0.5% 정도의 성능 저하만 발생
- 이런 메모리 향상으로 인해 mSigLIP을 다양한 배치 사이즈로 학습할 수 있고 최대 30B개의 데이터로 학습 수행
- 표 2와 그림 2 (가장 오른쪽)를 통해 결과를 살펴볼 수 있음

- 32k 개보다 많은 배치를 사용하는 경우 특별한 성능 향상을 발견하지 못함 → 다국어에서도 32k 배치사이즈면 충분
- mSigLIP은 XM3600 텍스트-이미지 검색 문제에서 SOTA 성능을 달성 → 기존의 최고 성능인 28.5%에 비해 6% 높은 34.9% 달성
3.4. SigLiT with four TPU-v4 chips
- 실제 많은 연구자들에게 중요한 질문은 다음의 질문! → 제한된 자원으로 학습을 할 수 있을까?
- 이에 따라 여기서는 오직 4개의 TPU-v4 칩을 사용하여 SigLiT 모델을 학습
- 공개적으로 사용 가능한 ViT-AugReg-B/8 모델을 고정된 비전 타워로 사용하며 학습을 가속하기 위해 미리 계산된 임베딩들을 사용
- 텍스트 모델은 Transformer를 사용하지만 24 레이어 대신 12 레이어의 모델을 사용
- LION optimizer로 학습하며 decoupled weight decay를 $1 \times 10^{-7}$로 사용
- 6.5k 스텝까지는 학습률을 $1 \times 10^{-4}$가 되도록 선형적으로 warm up하고 0까지 cosine decay
- 총 65,000 스텝만큼 32k의 배치사이즈로 학습 → 하루 정도의 학습 시간 소요
- 제로샷 ImageNet 분류 정확도 79.7%를 달성
- ViT-g/14 모델을 비전 타워로 사용하고 큰 텍스트 모델을 사용하는 경우
- 4개의 칩에 대해 20k 배치 사이즈로 학습을 수행하며 107k 스텝만큼 학습 (이틀 소요)
- 제로샷 ImageNet 분류 정확도가 84.5%로 향상
3.5. SigLIP with a Small Amount of TPU-v4 Chip
- SigLIP의 경우도 CLIP과 비교했을 때 더 적은 양의 칩으로 큰 배치 사이즈 학습이 가능
- 이번에는 사전 학습 된 가중치로 SigLIP 모델을 효과적으로 학습할 수 있는 방법에 대해 살펴보자
- 사전학습된 가중치로 이미지 모델을 초기화하여 학습 속도를 가속화
- 공개된 모델 ViT-AugReg-B/16을 본 논문의 비전 타워에 초기화 하고 학습 가능하도록 하여 SigLIP을 위해 사용한 WebLI 영어 데이터를 동일하게 파인튜닝
- 그림 4는 랜덤하게 초기화되어 처음부터 학습한 결과와의 비교를 나타냄

- 16 TPU-v4 칩을 사용했으며 16k 배치 사이즈로 총 2.4B 데이터를 통해 학습
- 하지만 이 경우 파인튜닝 셋업이 out-of-the-box에 대해 좋은 성능을 보이지 않음 → 이미지 모델을 파인튜닝하는 것이 시각적 표현의 품질을 저하시킴
- ImageNet 10 shot 선형 분류에서 파인튜닝 세팅이 초기부터 학습한 베이스라인보다 살짝 좋은 성능을 보임
- 본 논문에서는 사전 학습 가중치에 기본적으로 적용된 weight decay가 효율성을 감소시킨다고 가정
- 이에 따라 weight decay를 사용하지 않는 다른 논문들의 학습 방법을 참고하여 SigLIP 학습을 위한 사전학습 가중치에 weight decay를 적용하지 않음
- 이에 따라 weight decay는 랜덤하게 초기화 된 가중치를 가지는 텍스트 모델에만 적용되도록 설정
- 이런 단순한 변경만으로 SigLIP의 성능을 크게 향상시킴
- 그림 4를 보았을 때 해당 기법으로 SigLIP은 16k의 배치 사이즈를 사용하여 ImageNet의 제로샷 정확도에서 71%를 달성했으며 16개의 칩으로 3일 동안 학습 수행
- 처음부터 학습을 수행한 경우는 표 1의 아래쪽 줄에 나와있음
- 32 TPUv4 칩으로 2일 동안 학습
- SigLIP은 제로샷 정확도 72.1%를 달성
- 이는 학습 비용에 따라 엄청난 절감을 수행한 것! → CLIP의 경우 2500 TPUv3-days로 학습하여 72.6% 성능 달성)
3.6. Scaling up SigLIP and mSigLIP
- SigLIP을 확장하여 학습 → 표3의 결과 참고

- ViT-B, ViT-L, So-400m을 비전 인코더로 사용하고 텍스트 인코더의 크기는 고정
- 두 모델 경우 32k의 배치사이즈로 40B의 데이터로 학습하지만 (256/16)^2=256 이미지 패치와 64 텍스트 토큰 (16 대신)을 사용
- SigLIP 모델의 학습은 다른 해상도로 학습 수행
- 5B 더 많은 데이터로 타겟 해상도에 대해 학습하며 100x 작은 학습률과 사용, weight decay는 적용하지 않음
- 표3에서 ImageNet, ObjectNet, ImageNet-v2, ImageNet ReaL에 대한 제로샷 분류 결과와 MSCOCO에 대한 제로샷 이미지-to-텍스트 (I → T) 검색과 텍스트-to-이미지 (T → I) 검색 결과를 확인할 수 있음
- mSigLIP ViT-B 모델도 동일한 방식으로 확장
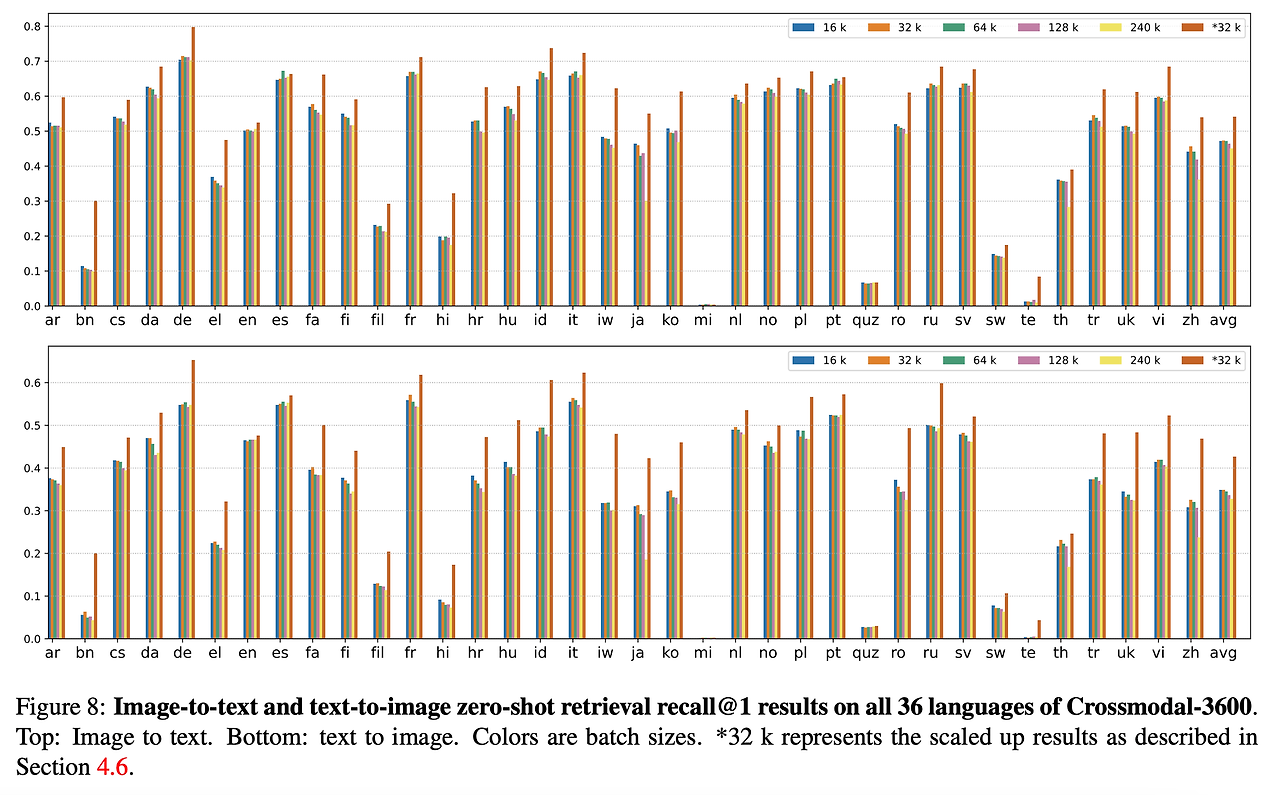
- 36개 언어에 대한 XM3600 벤치마크에 대해 이미지-텍스트 검색 결과를 확인
- mSigLIP ViT-B 모델이 이미지 검색의 recall@1에서 42.6%, 텍스트 검색의 recall@1에서 54.1%를 달성
- 결과는 부록의 표9와 그림 8에서 *32k로 표시된 내용을 참고

3.7. Stabilizing Large-batch Training
- 큰 배치사이즈로 학습하는 경우 적당한 크기의 모델 (B)에서도 transformer는 점점 불안정해짐
- 이런 불안정함은 gradient norms에서 큰 스파이크를 발생시킴
- 이런 불안정한 학습 과정은 그림 5에서 살펴볼 수 있음

- 이때 Adam과 AdaFactor의 $\beta_2$를 기본인 0.999에서 0.95로 감소시키는 경우 기울기에 대한 스파이크가 빠르게 회복되는 것을 확인
- 이에 따라 $\beta_2=0.95$로 본 논문의 모든 실험을 수행
3.8. Negative Ratio in Sigmoid Loss
- Softmax의 “맞는 클래스를 선택해라”의 관점을 Sigmoid의 “이 쌍을 평가해라”로 관점을 옮기면 일치하는 쌍과 일치 하지 않는 쌍의 불균형이 문제가 될 수 있음
- 배치 사이즈 $|\mathcal{B}|$에 대해 $|\mathcal{B}|$개의 일치하는 쌍과 $|\mathcal{B}^2 - |\mathcal{B}||$개 만큼의 일치하지 않는 쌍이 존재하게 됨
- 예를 들어 16k의 배치 사이즈를 사용하는 경우 268M개의 일치 하지 않는 쌍이 발생하며 16k개의 일치하는 쌍이 발생
- 이에 대한 영향을 확인하기 위해 특정 “매칭 : 비매칭” 비율을 목표로 하기 위해 충분한 비매칭들을 마스킹하여 배치를 구성하는 비율을 다양하게 조절
- 마스킹 방법
- Random: 무작위로 비매칭 쌍을 선택하여 마스킹
- Hard: 가장 어려운 비매칭 쌍 (손실함수가 큰)을 유지
- Easy: 가장 쉬운 비매칭 쌍 (손실함수가 작은)을 유지
- Hard + matching total pairs seen: 특정 스텝 동안 학습할 때 데이터를 마스킹하면 학습에 적용되는 데이터 쌍의 수가 줄어들게 됨 → 학습에 사용되는 데이터 쌍의 수를 일정하게 유지하기 위해 마스킹 되는 비율만큼 훈련 스텝 수를 늘림
- 그림 6을 통해 결과 확인 가능

- 다양한 마스킹 전략에 따른 결과 확인 가능
- 균형을 맞추기 위해 무작위로 부정 쌍을 제거하면 성능이 저하됨
- Easy의 경우 아예 효과가 없고 Hard의 경우 거의 성능 품질을 유지 → 예상대로 비매칭 쪽에서의 학습은 어려운 예시에서 이루어진다는 것을 확인 (Hard + Matching Total Pairs Seen의 경우 성능 소폭 향상)
- 예상대로 비매칭 예시가 적을수록 편향과 로짓의 값이 긍정적으로 변하는 것을 확인했지만 비매칭 쌍의 부정 비율이 더 줄어도 긍정 쌍의 평균 로짓 값은 거의 변하지 않음
- 해당 연구의 분석 결과
- 불균형은 크게 우려할만한 사항이 아님
- 더 많은 비매칭 예시를 효율적으로 포함시키는 방법을 고려할 수는 있지만 쉽지 않음
3.9. Bias Term in Sigmoid Loss
- 손실함수의 편향 항에 대해서 ablation study 진행
- 실험 조건
- Base 구조, 8k 배치사이즈, 900M 데이터 학습
- ImageNet, Oxford-iiit pet, Cifar 100에 대해서 제로샷 전이 결과 확인 → 표4 참고

- 편향의 경우 -10으로 초기화하는 것이 모든 문제에서 일관되게 좋은 성능을 보임
- 이유: 편향을 통해 학습이 prior와 유사하게 시작할 수 있도록 함 → 최적화 초기에 over-correction을 방지
- 0으로 설정하는 경우 해당 over-correction을 방지하지 못하므로 확연하게 나쁜 결과가 발생
- 또한 해당 효과는 temperature $t'$가 작게 초기화 되었을 때 더 명확함
- 이에 따라 본 논문에서는 편향과 temperature를 다음과 같이 설정
- $b=10, t'=\log10$
3.10. Label Noise Robustness
- 이전의 연구들을 살펴보면 sigmoid 손실함수를 분류 모델에 사용하는 경우 더욱 라벨 노이즈에 강인한 경향을 보임
- 이에 따라 본 연구에서도 SigLIP을 M/16 이미지 모델과 M 텍스트 모델을 배치사이즈 16384로 3.6B 데이터로 학습
- 노이즈는 다음과 같은 방식으로 추가
- Image: 확률 $p$를 적용하여 이미지를 uniform 랜덤 노이즈로 변환
- Text: 확률 $p$를 적용하여 토큰화 된 텍스트를 특정 길이만큼 랜덤하게 샘플링 된 새로운 토큰들의 시퀀스로 대체
- Batch alignment: 배치의 $p%$%를 랜덤하게 섞어줌
- Image & Text: 이미지와 텍스트 각각에 대해 $p$ 확률로 수행
- Image, text & batch: 위의 사례에 배치의 $p$%를 랜덤하게 섞는 것 까지 수행
- 이에 대한 비교 결과를 그림 7에서 살펴볼 수 있음

- Sigmoid 손실함수로 학습한 모델이 모든 방식의 노이즈 추가에 더 강인한 성능을 보임
4. Conclusion
- 언어-이미지 사전학습에 sigmoid 손실함수를 적용한 2개의 모델 소개: SigLiT과 SigLIP
- 본 논문의 결과에서는 sigmoid 손실함수를 사용하는 경우가 softmax 손실 함수 사용에 비해 더 좋은 성능을 보였으며 특히 작은 배치 사이즈에서 더 좋은 성능을 보임
- 손실 함수는 또한 메모리 효율적 → 추가적인 자원 없이 더 큰 배치 사이즈에 대해 연산 가능
- 본 논문의 실험을 통해 32k 정도의 배치 사이즈가 거의 최적의 성능에 도달하면서도 적절한 크기의 사이즈임을 확인
- 또한 sigmoid 손실함수의 편향에 따른 영향, 데이터 노이즈에 대한 강인성, sigmoid 손실함수 계산시 매칭되는 쌍과 매칭되지 않는 쌍의 비율에 대한 영향을 확인하였음
반응형
'논문 리뷰 > Multi-Modal' 카테고리의 다른 글
| Visual SKETCHPAD: Sketching as a Visual Chain of Thought for Multimodal Language Models (0) | 2025.01.21 |
|---|---|
| MyVLM: Personalizing VLMs for User-Specific Queries (10) | 2024.09.01 |
| SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities (4) | 2024.09.01 |
| [LLaVA 1.5] Improved Baselines with Visual Instruction Tuning (7) | 2024.09.01 |
| [LLaVA] Visual Instruction Tuning (4) | 2024.08.31 |



