
- Link: https://arxiv.org/pdf/2304.08485.pdf
- 프로젝트 링크: https://llava-vl.github.io/
- 깃허브: https://github.com/haotian-liu/LLaVA
0. Abstract
- Instruction tuning 대형 언어 모델 (Instruction tuning LLMs)은 새로운 문제에 대해 zero-shot을 수행하는 발전된 능력을 가졌지만 멀티 모달 영역에서는 이 아이디어가 별로 탐구되지 않음
- 본 논문에서는 언어만을 사용하는 GPT-4를 통해서 멀티 모달 언어-이미지 instruction-following 데이터를 생성하는 첫번째 시도를 수행
- 이렇게 생성된 데이터를 사용하여 instruction tuning을 수행한 모델 소개 → LLaVA: Large Language and Vision Assistant
- End-to-end로 학습된 대형 멀티모달 언어 모델로 비전 인코더와 LLM을 연결하여 범용적인 시각 및 언어 이해를 목표로 함
- LLaVA의 결과는 멀티모달 채팅 능력에서 인상적인 성능을 보임
- 합성 멀티 모달 instruction following 데이터셋을 사용했을 때 GPT-4와 비교했을 때 85.1%의 상대 점수 취득
- ScienceQA로 파인튜닝 했을 때 LLaVA와 GPT-4의 시너지는 92.53%라는 SOTA 성능 달성
1. Introduction
- 사람은 상호작용을 할 때 시각, 언어 등 다양한 채널을 사용하고 이를 통해 더 높은 수준의 이해를 할 수 있음
- 인공지능의 주요한 목표 중 하나는 다양한 실생활의 문제들에 대한 시각적, 언어적 멀티 모달 명령에 사람의 의도에 맞게 효과적으로 따르는 일반적 목적의 어시스턴트를 개발하는 것
- 대형 언어 모델 (LLMs)는 언어로 표현될 수 있는 넓은 범위의 역할을 수행 (e.g. ChatGPT, GPT-4, LLaMA, …)
- 하지만 이런 작업들은 모두 텍스트만 지원
- 본 논문에서는 시각적인 instruction-tuning을 제시 → instruction-tuning을 멀티모달 공간으로 확장하는 최초의 시도
- 본 논문의 contribution
- Multimodal instruction following data
- 첫번째 도전은 시각적-언어적 instruction-following 데이터의 부족
- ChatGPT/GPT-4를 사용하여 이미지-텍스트 쌍 데이터를 변환 → 적절한 instruction-following 형식으로 변경
- Large multimodal models
- Large Multimodal Model (LMM)을 개발 → 시각적 인코더인 CLIP과 언어적인 디코더인 LLaMA를 결합하고 이들을 생성한 instructional 시각적-언어적 데이터를 통해 end-to-end로 파인튜닝
- LMM instruction-tuning을 위해 생성된 데이터를 효과적으로 사용하는 방법이나 일반적 목적의 instruction-following 시각적 에이전트를 구축하는 실용적 팁을 제공
- GPT-4를 사용하여 Science QA 멀티모달 추론 데이터셋에서 SOTA 성능 달성
- Open-source
- 다음의 요소들을 공개
- 생성된 멀티모달 instruction 데이터
- 데이터 생성과 모델 학습을 위한 코드
- 모델 체크포인트
- 시각적 채팅 데모
- 다음의 요소들을 공개
- Multimodal instruction following data
2. GPT-assisted Visual Instruction Data Generation
- 이미지-텍스트 쌍과 같은 멀티모달 데이터가 많이 공개되었지만 멀티모달 instruction-following 데이터의 경우 사용 가능한 양이 제한됨 → 수집하는 과정에 너무 많은 시간이 소요되며 크라우드 소싱을 고려했을 때도 비교적 잘 정의되지 않음
- 텍스트 주석 문제에서 GPT 기반 모델들의 성공에 영감을 받아 본 논문에서도 ChatGPT/GPT-4를 기존의 이미지-텍스트 쌍 데이터에 기반한 멀티모달 instruction-following 데이터 수집에 사용
- 이미지-텍스트 쌍을 instruction-following 버전으로 확장하는 단순한 방법
- 이미지 Xv와 이에 대응하는 캡션 Xc가 있을 때 어시스턴트가 이미지의 내용을 설명하도록 지시하는 질문 Xq의 세트를 만들 수 있음
- GPT-4에 프롬프팅을 수행하여 표 8과 같은 질문 리스트를 선별할 수 있음

- 이미지-텍스트 쌍을 instruction-following 버전으로 확장하는 단순한 방법은 다음과 같음
- Human : XqXv <STOP> \n Assistant : X_c <STOP> \n
- 해당 방법은 비록 구축은 간단하지만 명령과 응답 모두 다양성과 심도있는 추론이 부족
- 위와 같은 문제를 피하기 위해 본 논문에서는 GPT-4와 ChatGPT를 강력한 teacher 모델(물론 두 모델 모두 텍스트만을 입력으로 함)로 하여 시각적인 콘텐츠에 대한 instruction-following 데이터를 생성
- 이미지에 있는 시각적인 특징들을 텍스트만 제공하는 GPT에 인코딩하기 위해 2가지 종류의 요소를 사용
- 캡션: 일반적으로 다양한 관점에서 시각적인 장면을 묘사
- 바운딩 박스: 일반적으로 장면 안에 있는 물체들의 위치를 나타냄 → 각 박스는 종류와 공간적인 위치를 인코딩
- 표 1의 위쪽 블록에서 하나의 예시를 살펴볼 수 있음
- 이런 기법들은 이미지를 대형 언어 모델이 인지할 수 있는 형태로 만들어줌
- 이미지에 있는 시각적인 특징들을 텍스트만 제공하는 GPT에 인코딩하기 위해 2가지 종류의 요소를 사용
- 본 논문은 COCO images 데이터를 사용하며 3가지 종류의 instruction-following 데이터 생성 (예시: 표1의 아래쪽 블록에서 살펴볼 수 있음) → 각 경우에 대해 사람이 직접 몇가지 예시를 만들고 이를 GPT-4 쿼리에 포함하여 in-context 학습을 수행하도록 함
- 대화
- 어시스턴트와 사람이 사진에 대해 질문하는 대화를 디자인
- 응답은 어시스턴트가 이미지를 보고 질문에 대답하는 형식
- 이미지의 시각적 내용에 대한 다양한 질문들 포함 (물체의 종류, 물체의 수 세기, 물체의 행동, 물체의 위치, 물체간의 상대 위치 등)
- 오직 질문에 대해 명확한 답변만 고려
- 표 10을 통해 자세한 프롬프트를 참고할 수 있음
- 자세한 묘사
- 이미지에 대한 풍부하고 포괄적인 설명을 위해 질문 리스트를 생성
- GPT4에 프롬프팅하여 질문 리스트를 선별 (표9 참고)
- 각 이미지에 대해 리스트에서 랜덤하게 하나의 질문을 샘플링하고 GPT4에 질문하여 자세한 묘사를 생성
- 복잡한 추론
- 위의 두개는 시각적인 컨텐츠 자체에 집중
- 응답이 엄격한 논리를 따르는 단계적인 추론 과정을 요구할 수 있음


- 대화
- 158K개의 언어-이미지 instruction-following 샘플 수집
- 각각 58K개의 대화, 23K개의 자세한 묘사, 77K개의 복잡한 추론 데이터
3. Visual Instruction Tuning
3.1. Architecture
- 주요 목표 → 사전학습된 LLM과 시각적 모델의 효율성을 동시에 향상시키는 것
- 모델 구조는 그림 1 참고!

- 입력 이미지 Xv에 대해 사전학습된 CLIP 인코더 사용 → ViT-L/14
- 이를 통해 시각적인 피쳐 취득 → Zv=g(Xv)
- 학습 가능한 투영 행렬 (projection matrix) W를 적용하여 Zv를 언어 임베딩 토큰 Hv로 변환 → 이는 언어 모델의 단어 임베딩 공간과 동일한 차원을 가짐

- 이를 통해 최종적으로 시각적 토큰의 시퀀스 Hv를 얻을 수 있음
- 이런 단순한 투영 방식은 가볍고 비용면에서 효율적임
- 더 복잡한 (하지만 비용이 비싼) 기법으로는 이미지와 언어의 표현을 연결하는 방식을 고려할 수 있음 → Flamingo의 gated cross-attention이나 BLIP-2의 Q-former, 혹은 SAM 등의 시각적 인코더를 고려할 수 있음
- LLaVA를 위한 더 효율적이면서 복잡한 구조의 디자인은 future work로
3.2. Training
- 각 이미지 Xv에 대해 다중 턴 대화 데이터 생성 (X1q,X1a,...,XTq,XTa) → T는 전체 턴의 수
- 이 데이터들을 시퀀스로 구성 → 모든 대답을 어시스턴트의 응답으로 처리
- t번째 턴에서 instruction Xtinstruct는 다음과 같음

- 이를 통해 표2와 같이 멀티모달 instruction-following 시퀀스에 대한 통일된 형식을 제공

- 길이 L의 시퀀스에 대해 타겟 정답 Xa 생성의 확률 계산
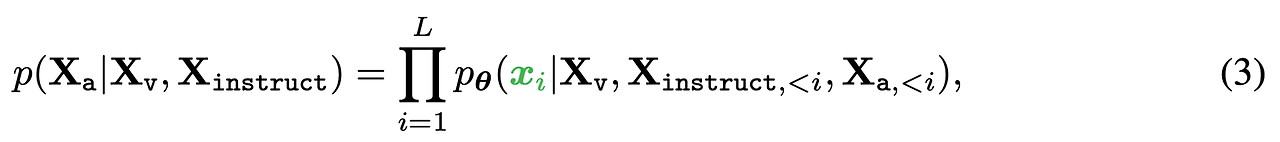
- θ는 학습 가능한 파라미터이며 Xinstruct,<i,Xa,<i는 현재 예측 토큰 xi 이전 모든 턴의 instruction과 정답 토큰 (예측 토큰의 경우 표 2 내용 참고)
- 조건부의 경우 명시적으로 Xv를 추가하여 모든 응답에 대해 이미지가 고정되어 있는 것을 강조, Xsystem−message와 <STOP>은 가독성을 위해 제외했으나 실제로는 조건부에 포함
- LLaVA 모델 학습을 위해 두 단계의 instruction-tuning 과정을 고려
- Stage 1: Pretraining for Feature Alignment
- 데이터 처리
- 컨셉의 범위와 학습 효율성간의 균형을 맞추기 위해 CCM3M를 595K 개의 이미지-텍스트 쌍으로 필터링 (필터링에 대한 상세한 내용은 부록 참고)
- 해당 쌍들은 섹션 2에서 소개한 단순한 확장 방법을 통해 변환된 instruction-following 데이터 사용 → 각 샘플은 단일 턴 대화로 취급
- 이미지 Xv에 대한 (2)의 입력 Xinstruct를 구축하기 위해 표 8의 질문 Xq가 랜덤하게 샘플링 됨 → 이미지에 대해 짧게 묘사하도록 어시스턴트에게 요청하는 언어적 명령
- 예측 응답 Xa는 원본 캡션
- 학습 관련
- 시각적 인코더와 LLM의 가중치는 모두 고정하고 오직 학습 가능한 파라미터 θ=W (투영 행렬)의 likelihood를 최대화하도록 학습
- 이를 통해 이미지 피쳐 Hv가 사전 학습된 LLM의 단어 임베딩과 일치할 수 있음
- 이 단계는 고정된 LLM에 호환되는 시각적 토크나이저를 학습하는 과정으로 이해할 수 있음
- 데이터 처리
- Stage 2: Fine-tuning End-to-End
- 이미지 인코더의 가중치만 고정하고 투영 행렬과 LLM의 사전학습된 가중치만 업데이트 → 학습 가능한 파라미터 → θ={W,ϕ}
- 다음과 같은 2개의 시나리오를 고려
- Multimodal Chatbot
- 158K개의 언어-이미지 instruction-following에 대한 챗봇 파인튜닝 수행
- 응답의 세 타입 중 대화는 멀티 턴, 다른 둘은 단일 턴 → 학습 중 랜덤하게 샘플링
- Science QA
- ScienceQA 벤치마크에 해당 기법 적용
- 각 질문은 이미지나 언어 모델 형태의 컨텍스트에 의해 제공됨
- 어시스턴트는 추론 과정을 자연어 형태로 제공하고 다수의 정답 중 하나를 선택
- 싱글 턴 대화로 데이터 구성 → 질문과 컨텍스트는 Xinstruct로 추론과 정답은 Xa로
- Multimodal Chatbot
- Stage 1: Pretraining for Feature Alignment
4. Experiments
4.1. Multimodal Chatbot
- LLaVA의 이미지 이해 및 대화 능력을 확인하기 위해 챗봇 데모 개발
- 먼저 표 4, 5와 같이 GPT-4 논문에 있던 예제를 사용 → 비교를 위해 GPT-4 논문, BLIP-2, OpenFlamingo의 응답을 함께 추가했음


- LLaVA의 경우 적은 수의 멀티모달 instruction-following 데이터셋 (~80K 이미지)으로 학습했음에도 두 예시에서 멀티모달 GPT-4와 유사한 추론 성능을 보임
- 두 이미지 모두 LLaVA의 학습 도메인 바깥의 예시들이며 LLaVA는 해당 장면들을 이해하고 질문에 잘 응답
- 반면 BLIP-2와 OpenFlamingo는 사용자의 명령에 따라 적절히 응답하는 것 대신 이미지 묘사에만 집중
- 더 많은 예시는 그림 3, 4, 5를 통해 살펴볼 수 있음




Quantitative Evaluation
- 모델의 생성된 응답의 품질을 평가하기 위해 GPT-4 사용 → COCO 평가 데이터셋 중 30개 사용, 제안된 데이터 생성 파이프라인을 사용하여 3개 종류의 질문 생성 (대화, 자세한 묘사, 복잡한 추론)
- LLaVA는 질문과 시각적인 이미지 입력을 기반으로 응답을 예측하고 GPT-4가 질문에 대한 참고 예측, 바운딩 박스, 캡션을 생성
- 두 모델 모두에게 응답을 얻은 후 두 모델의 응답, 질문, 시각적 정보 (캡션, 바운딩 박스)를 GPT-4에 입력하여 응답의 유용성, 연관성, 정확성, 응답의 자세함과 같은 항목을 평가하고 최종적으로 1-10 사이의 점수를 도출
- 학습 셋을 다양하게 해서 다른 종류의 instruction-following 데이터를 사용했을 때 효과에 대한 스터디 → 표 3 참고
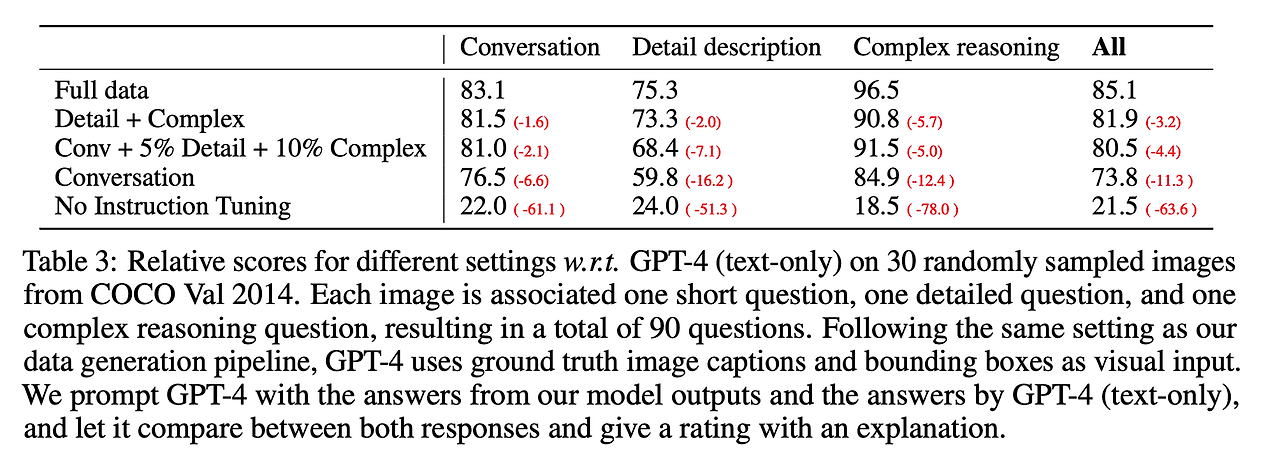
- 첫번째로 instruction tuning을 수행하는 경우 모델이 사용자의 명령을 따르는 능력이 50점 이상 증가
- 두번째로 적은 양의 자세한 묘사와 복잡한 추론 질문을 더해주는 경우 모델의 평균 능력이 7점 정도 크게 향상 → 이 경우 추가하지 않은 대화 관련 점수도 향상되는 것을 확인 → 추론 능력의 향상이 대화 능력과 상호 보완적임을 알 수 있음
- 마지막으로 모든 세 종류의 데이터를 사용하는 경우 최고 성능인 85.1%를 달성
4.2. ScienceQA
- ScienceQA는 3가지 과목, 26가지 주제, 127가지 카테고리, 379가지 스킬에 대한 21K개의 멀티모달 객관식 질문을 포함
- 벤치마크 데이터셋은 12,726개의 학습 데이터, 4,241개의 검증 데이터, 4,241개의 테스트 데이터로 나눠짐
- 2개의 대표적인 기법 사용 → GPT-3.5 모델에 CoT (Chain-of-thoughts) 포함 혹은 미포함, LLaMA-Adapter + MM-CoT (Multimodal chain-of-thoughts)
- 결과는 표 6 참고

- LLaVA에 대해서는 마지막 레이어 전에 시각적인 피쳐를 사용하며 모델이 먼저 추론을 수행하고 대답하도록 요청
- 12 epoch 동안 학습 수행 → 90.92%의 정확도 도출 (SoTA 91.68%에 근접)
- GPT-4에 프롬프팅을 수행하여 2-shot in-context-learning을 사용하여 82.69%의 정확도 도출 (GPT-3.5의 75.17%에 비해 7.52% 높음)
- 본 논문의 결과와 GPT-4를 결합하는 2가지 기법 고려
- A GPT-4 complement
- GPT-4가 응답을 제공하는데 실패할 때 제안하는 기법의 예측을 사용
- 이를 통해 90.97%의 정확도를 얻음 → 본 기법만 사용했을때와 거의 유사
- GPT-4 as the judge
- GPT-4와 LLaVA가 다른 응답을 하는 경우 GPT-4에 다시 프롬프팅을 수행하여 질문과 두 결과에 기반해서 다시 최종 답변을 제공하라고 요청
- 이 경우 GPT-4가 전반적으로 향상된 답변을 도출했으며 92.53%라는 SoTA 성능을 도출
- A GPT-4 complement
Ablations
- 몇가지 디자인 설정에 대해 ScienceQA를 사용하여 ablation 수행 → 표 7 참고
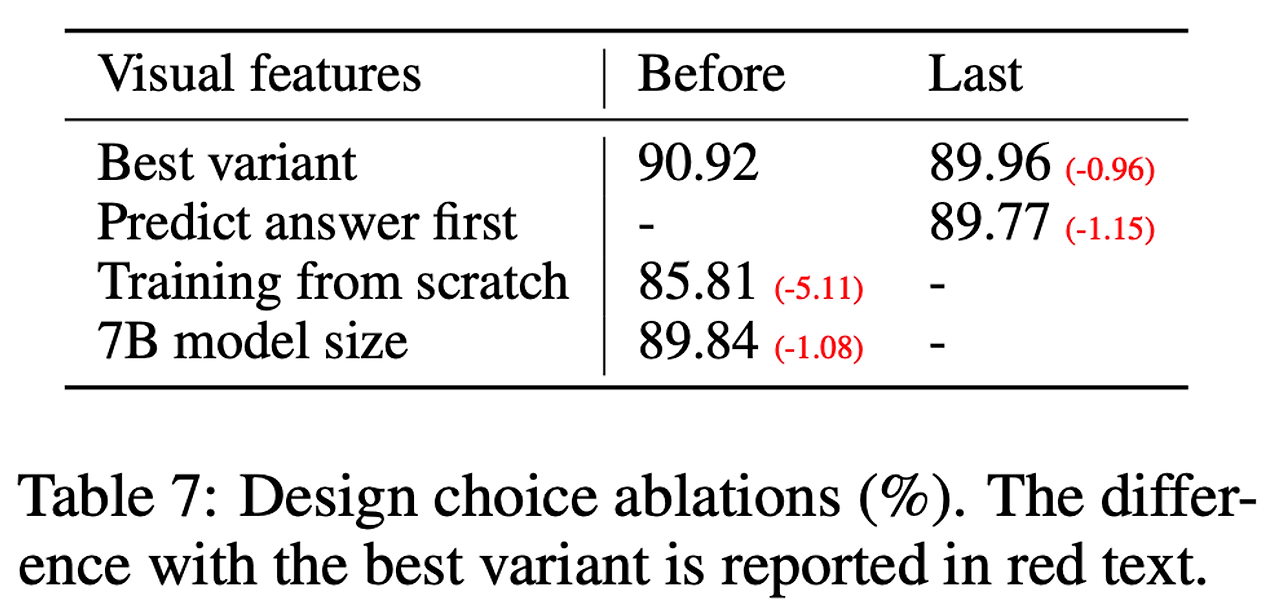
- 시각적 피쳐
- CLIP 비전 인코더의 마지막 레이어 피쳐를 사용 → 마지막 레이어 이전의 피쳐를 사용하는 것 보다 0.96% 감소한 89.96% 달성
- 이 이유는 CLIP의 마지막 레이어 피쳐가 마지막 이전 레이어 피쳐보다 더 글로벌한 이미지 특성에 집중하기 때문으로 추정 → 지역적인 특성에 집중하는 경우 특정 이미지의 자세한 부분을 더 잘 이해할 수 있음
- CoT
- 모델 예측에서 응답과 추론 과정 사이에 순서를 결정하기 위해 두 가지 변형을 모두 실행한 결과, answer-first가 12번의 에포크에서 89.77%의 정확도로 가장 높은 수치를 보이는 반면, reasoning-first는 6번의 에포크에서 89.77%의 정확도에 빠르게 도달 → 하지만더 많은 훈련 (24 에포크)을 해도 성능의 개선은 없었음
- CoT와 같은 reasoning-first 전략은 수렴성 향상에 크게 도움이 되지만 최종 성능에는 상대적으로 적게 기여하는 것을 알 수 있음
- 사전 학습
- 사전 학습은 뛰어넘고 바로 처음부터 ScienceQA로 학습 수행 → 85.81%로 성능 하락
- 5.11%라는 큰 폭의 성능 감소 → 거대한 사전 학습 지식은 유지하면서 멀티모달 피쳐들을 일치시키는 사전 학습 단계의 중요성을 나타냄
- 모델 크기
- 모든 설정을 13B와 동일하게 하고 7B 모델 학습 → 89.84%로 1.08% 성능 감소
- 시각적 피쳐
5. Discussions
- 본 논문은 언어만 가능한 GPT-4를 사용하여 시각적 instruction tuning을 수행하는 효율성을 보임
- 언어-이미지 instruction-following 데이터를 생성하는 자동 파이프 라인 소개
- 해당 파이프라인을 통해 얻은 데이터로 LLaVA 학습 수행 → 사람의 의도를 따라 시각적 문제를 해결하는 멀티모달 모델
- ScienceQA에서 파인튜닝 수행시 SoTA 정확도를 달성했으며 멀티모달 채팅 데이터로 시각적 채팅 수행시에도 좋은 성능을 보임
- 해당 프로젝트는 계속 진행중이며 아래와 같은 부분을 더 수행할 수 있음
- 데이터 크기
- 사전 학습 데이터로 CC3M의 일부 데이터만 사용하고 COCO의 일부 데이터로 파인튜닝 수행
- 적용 범위를 늘리기 위해 더 큰 이미지-텍스트 데이터로 사전학습
- 멀티모달 채팅 어시스턴트 파인튜닝을 위해 더 큰 언어-이미지 데이터에 (GLIP, GLGEN) 데이터 생성 파이프라인 적용
- 더 많은 시각 모델을 통한 연결
- SAM과 같이 더 강력한 시각 모델을 LLaVA에 적용하여 현재 멀티모달 GPT-4가 가지지 못한 능력을 제공
- 데이터 크기



