반응형
- 논문 링크: https://arxiv.org/pdf/2410.10629
- 프로젝트 페이지: https://nvlabs.github.io/Sana/
- 깃허브: https://github.com/NVlabs/Sana

0. Abstract
- Sana: 효율적으로 이미지를 4096x4096 해상도까지 생성할 수 있는 text-to-image 프레임워크
- Sana의 특징
- 고해상도 이미지 생성 가능
- 강력한 텍스트-이미지 일치도 (text-image alignment)
- 노트북 GPU에서 구동 가능할 정도의 엄청나게 빠른 속도
- Sana의 핵심 디자인
- 심층 압축 오토 인코더 (Deep Compression Autoencoder)
- 이미지를 8x 만 압축하는 기존의 AE (AutoEncoder)와는 다르게 본 논문에서는 32x로 이미지를 압축하는 AE를 학습 → 효과적으로 잠재 (latent) 토큰의 수를 감소
- 선형 DiT (Diffusion Transformers)
- 모든 DiT의 기존 어텐션을 선형 어텐션으로 대체 → 품질을 희생하지 않으면서 고해상도의 이미지에 대해 더욱 효율적
- 디코더 기반의 텍스트 인코더
- T5를 최신의 디코더 기반 소형 LLM으로 대체 → 이미지-텍스트 일치도를 향상시킴
- 효율적인 학습과 샘플링
- Flow-DPM-Solver를 제안 → 샘플링 스텝 수를 감소시킴
- 심층 압축 오토 인코더 (Deep Compression Autoencoder)
- Sana-0.6B 모델의 경우
- 거대한 확산 (Diffusion) 기반 모델 (e.g. Flux-12B)과 경쟁할만한 성능을 달성하면서도 20배 정도 작은 크기를 가지며 100배 이상의 추론 속도 달성
- 16GB 메모리를 가지는 노트북 GPU에서 1024x1024 해상도의 이미지를 생성하는데 1초 이하의 시간 소요 → 생성에 대한 비용을 크게 절감할 수 있음
1. Introduction
- 기존의 잠재 확산 모델 (Latent Diffusion Model)들은 text-to-image 연구에서 뛰어난 발전을 달성했으며 상업적인 가치를 생성해왔음
- 반면 해당 모델의 몇몇 요소들에서 연구자들 사이에 공통된 의견이 생겨남
- U-Net을 트랜스포머 구조로 변경
- 비전-언어 모델 (VLMs, Vision-Language Models)을 사용하여 이미지를 자동으로 라벨링
- VAEs (Variational Autoencoders)와 텍스트 인코더의 개선
- 초 고해상도 이미지 생성
- 그러나 상업 모델들은 지속적으로 크기가 커지고 있음
- PixArt’s (0.6B) → SD3 (8B) → LiDit (10B) → Flux (12B) → Playground V3 (24B)
- 이렇게 모델의 크기가 커질수록 매우 높은 학습과 추론 비용을 요구
- 이에 따라 다음과 같은 질문을 할 수 있음!
- 클라우드나 엣지 장비에서도 빠르게 실행할 수 있도록 계산 효율적이면서 고품질, 고해상도의 이미지를 만들 수 없을까?? 🤔
- 본 논문에서는 Sana를 제안 → 1024x1024부터 4096x4096의 해상도 범위에서 높은 품질을 가지는 이미지들에 대해 효율적인 학습과 합성이 가능한 파이프라인
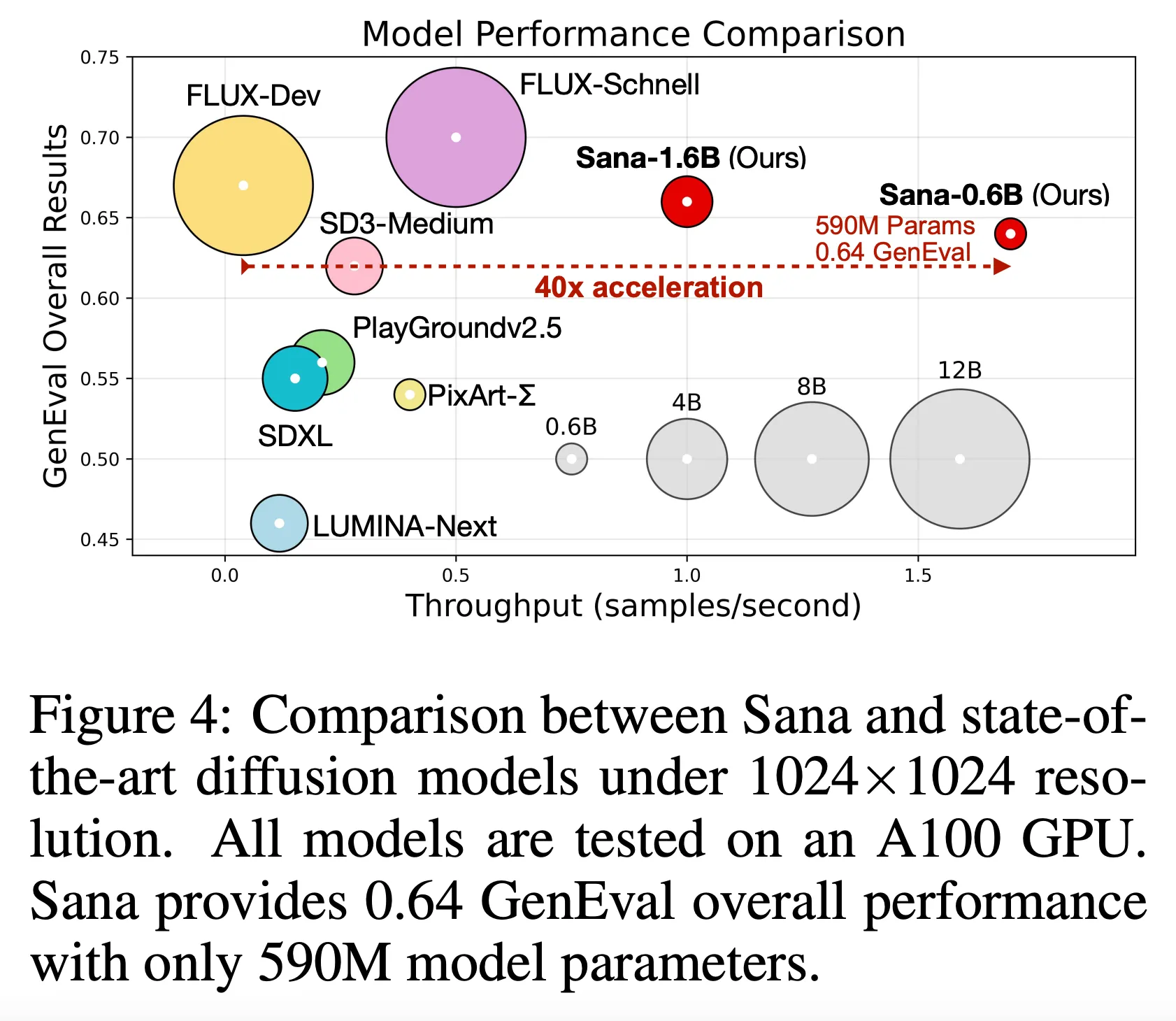
- Sana-0.6B의 경우 4K 이미지 생성에서 현재 SoTA 모델 (FLUX)보다 100배 이상 빠른 추론 속도를 달성 (그림 2 참고)
- 1K 해상도 생성에 대해서는 40배 정도 빠른 속도 달성 (그림 4 참고)
- 또한 Sana-0.6B 모델을 양자화 (Quantize) 후 엣지 장비에서 실행했을 때 일반 4090 GPU에서 1024x1024 이미지 생성에 0.37초만 소요
- 즉 Sana = 실시간 이미지 생성을 위한 강력한 기반 모델!! 💪

- Sana의 핵심 디자인 → 다음 장에서 자세히 살펴볼 것!
- 심층 압축 오토인코더 (Deep Compression Autoencoder)
- 효율적인 선형 DiT (Linear DiT)
- 디코더 기반의 작은 LLM을 텍스트 인코더로 사용
- 효율적인 학습과 추론 전략
2. Methods
2.1. Deep Compression Autoencoder
2.1.1. Preliminary
- 잠재 확산 모델 (Latent Diffusion Models, LDM)
- 픽셀 공간에서 직접 확산 모델을 수행하는 것의 과도한 학습, 추론 비용을 방지하기 위해 사전학습 된 오토인코더를 통해 얻은 압축된 잠재 공간 (Latent Space)에서 작동하는 잠재 확산 모델 (Latent AutoEncoder)이 제안됨
- 기존의 잠재 확산 모델에서 가장 공통적으로 사용된 오토인코더들은 다운샘플링 인수인 $F=8$로 설정 → 픽셀 공간 $\mathbb{R}^{H \times W \times 3}$의 이미지를 잠재 공간 $\mathbb{R}^{\frac{H}{8} \times \frac{W}{8}\times C}$에 맵핑
- 이때 $C$는 잠재 채널의 수를 나타냄
- DiT (Diffusion Transformers) 기법에서는 확산 모델에 의해 처리되는 토큰의 수가 다른 하이퍼파라미터 $P$(패치 크기, Patch Size)에 의해 영향을 받음
- 잠재 특징 (Latent Feature)은 패치의 크기 $P \times P$에 의해 그룹화 되고 이를 통해 $\frac{H}{PF} \times \frac{W}{PF}$ 토큰을 생성
- 일반적으로 기존 연구들에서는 이 패치 크기로 2를 사용
- 정리하자면 이전의 잠재 확산 모델에서는 (e.g. PixArt, SD3, Flux) AE-F8C4P2나 AE-F8C16P2를 사용 → AE는 이미지를 8x로 압축하고 DiT는 2x로 압축
- 본 논문의 Sana에서는 압축 인자를 32x로 공격적으로 설정하고 몇몇의 기법을 통해 성능을 유지
2.1.2. AutoEncoder Design Philosophy
- 이전의 AE-F8과 다르게 본 논문에서는 입축의 비율을 더욱 공격적으로 증가시킴
- 이에 대한 이유는 고해상도 이미지는 자연적으로 풍부한 정보를 가지고 있으므로 이런 고해상도 이미지에 대한 효율적인 학습과 추론은 오토인코더의 높은 압축을 필요로 하기 때문!
- 표 1에서는 MJHQ-30K에서 비록 기존 기법 (e.g. SD v1.5)이 AE-F32C64를 시도했으나 SDXL의 AE-8C4에 비해 엄청나게 품질 저하가 발생한 것을 알 수 있음
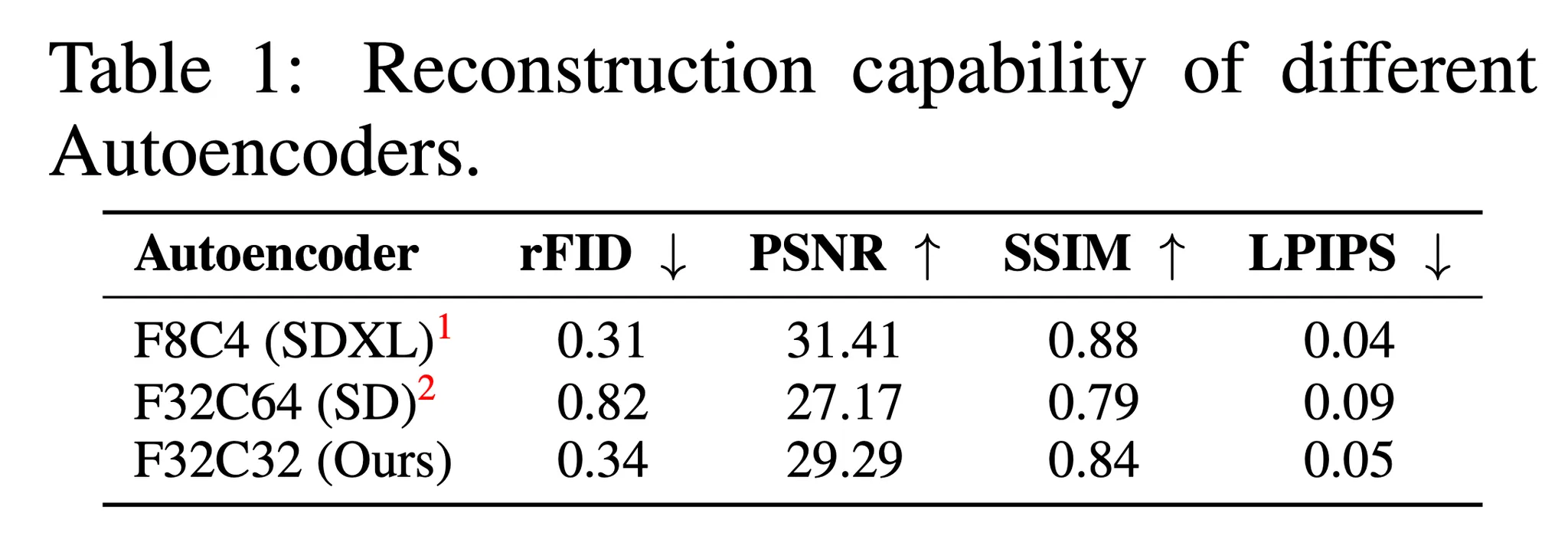
- 본 논문에서는 패치 크기 $P$를 증가시키는 대신 오토인코더가 압축에 대해 모든 책임을 지고 잠재 확산 모델이 오직 디노이징 (Denoising)에 집중해야한다고 주장
- 이에 따라 본 논문에서는 AE가 다운샘플링 인자 $F=32$, 채널 $C=32$를 사용하도록 하고 패치 크기는 1로 하여 잠재 공간에서 확산 모델을 실행 → AE-F32C32P1
- 해당 디자인은 토큰의 수를 4x 감소시키고 더 적은 GPU 메모리를 요구하여 학습과 추론 속도를 눈에 띄게 향상시킴
2.1.3. Ablation of AutoEncoder Designs
- 모델 구조의 관점에서 수렴을 가속하기 위해 몇가지 조정을 수행
- 특히 기본 셀프 어텐션을 선형 어텐션 블럭으로 대체 → 고해상도 생성의 효율성을 향상
- 추가적으로 학습 관점에서는 멀티 스테이지 학습 전략을 사용하여 학습 안정성을 향상시킴 → AE-F32C32를 1024x1024 이미지로 파인튜닝하여 고해상도 데이터에 대해 더 나은 복원 (Reconstruction)이 가능하도록 함
DiT의 토큰을 더 큰 패치크기로 압축할 수 있을까?
- AE-F8C16P4, AE-F16C32P32, AE-F32C32P1을 비교
- 이 세가지 설정은 1024x1024 이미지를 동일한 수의 토큰인 32 x 32로 압축
- 그림 3(a)에서 볼 수 있듯이 비록 AE-F8C16이 가장 뛰어난 복원 능력을 가지지만 (rFID: F8C16 < F16C32 < F32C32) 경험적으로는 생성 결과에서 F32C32가 가장 뛰어난 성능을 보임 (FID: F32C32P1 < F16C32P2 < F8C16P4)

- 이는 오토인코더가 고비율의 압축에 집중하고 확산 모델이 디노이징에 집중하는 것이 최적의 선택임을 나타냄
AE-F32의 채널 설정
- 본 논문에서는 다양한 채널에 대한 설정 끝에 $C=32$를 최적의 설정으로 최종 선정
- **그림 3(b)**에서 확인할 수 있듯이 채널의 수가 적으면 더욱 빠르게 수렴을 달성하지만 복원 품질은 더 안 좋아짐
- 35K 학습을 수행 → 수렴 속도는 C=16과 C=32가 유사하지만 C=32가 더욱 나은 복원 지표를 보임 → 더 나은 FID, CLIP 점수
- 비록 C=64가 거 나은 복원 능력을 보이지만 DiT의 학습과 수렴 속도가 C=32에 비해 현저하게 느림
2.2. Efficient Linear DiT Design
- DiT에서 사용된 셀프 어텐션은 $O(N^2)$의 계산 복잡도를 가짐 → 고해상도 이미지 처리시 낮은 계산 효율성
- 이 문제의 해결을 위해 본 논문에서는 처음으로 선형 DiT를 제안
- 기존 셀프 어텐션을 선형 어텐션으로 대체 → 고해상도 이미지 생성시 성능 저하 없이 높은 계산 효율성을 보임
- 추가적으로 본 논문에서는 Mix-FFN을 사용하여 기존의 MLP-FFN을 대체
- 3x3으로 깊이에 대한 합성곱 (depth-wise convolution)을 수행 → 토큰 정보를 더 효과적으로 통합
선형 어텐션 블럭
- 그림 5를 통해 본 논문에서 사용되는 선형 어텐션 모듈의 개요도를 살펴볼 수 있음

- 계산 복잡도 감소를 위해 기존의 소프트맥스 기반 어텐션을 ReLU 선형 어텐션으로 대체
- ReLU 선형 어텐션이나 다른 변형들은 원래는 고해상도의 예측 문제들에 (High-resolution dense prediction tasks) 적용되었으며 본 논문에서는 이미지 생성에서 선형 어텐션의 효율성을 보임
- 본 논문의 접근에 대한 계산적 이득에 대해 살펴보자
- 식 1에서 볼 수 있듯이 각 쿼리에 대해 어텐션을 계산하는 대신 공유된 아래 2 항을 한번씩만 계산
- 이런 공유된 항들은 각 쿼리에 대해 재사용 될 수 있으며 선형 계산 복잡도 O(N)을 가짐
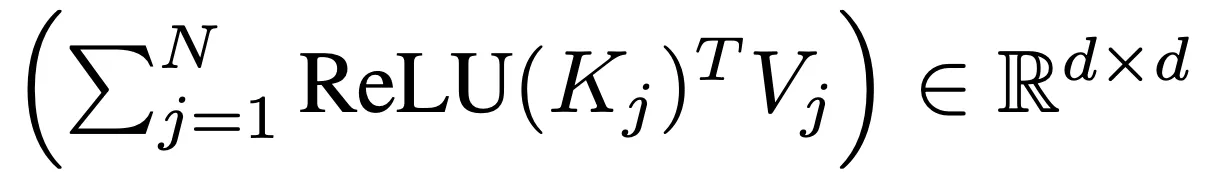
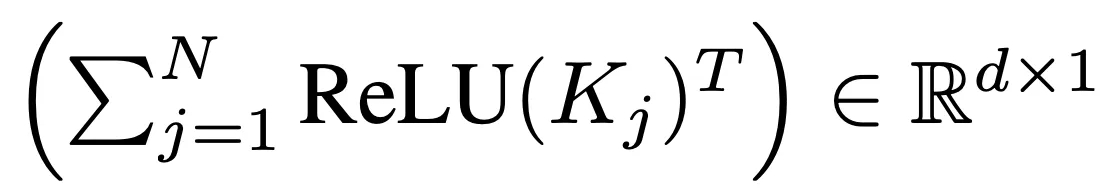
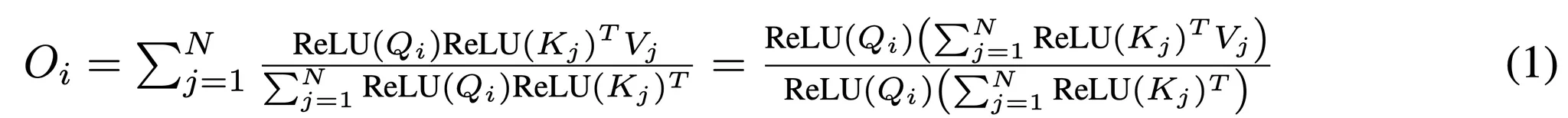
Mix-FFN 블럭
- 선형 어텐션을 사용하는 경우 소프트맥스 어텐션에 비해 계산 복잡도가 감소되며 낮은 지연 시간을 가짐
- 그러나 비선형 함수의 부재는 성능 저하를 초래할 수 있음 → 선형 어텐션 모델은 최종적으로는 유사한 성능을 달성하지만 훨씬 느린 수렴 속도를 가짐
- 학습 효율성을 개선하기 위해 기존 MLP-FFN은 Mix-FFN으로 대체
- Mix-FFN은 inverted residual 블럭, 3x3의 깊이에 대한 합성곱, GLU (Gated Linear Unit)로 구성
- 깊이에 대한 합성곱은 모델이 지역적인 정보 파악하는 능력을 향상시킴 → ReLU 선형 어텐션이 지역적인 정보를 잘 파악하지 못하는 것을 보완
- 모델 디자인에 따른 성능 ablation은 표 8 참고
Positional Encoding을 없앤 DiT (NoPE)
- 놀랍게도 본 논문에서는 Positional Embedding을 제거하고도 성능에서 손실이 발생하지 않음
- 제로 패딩을 사용한 3x3 합성곱이 내재적으로 위치 정보를 포함
- 기존의 DiT 기반 기법들은 대부분 absolute PE, learnable PE, RoPE 등을 사용하지만 본 논문을 NoPE를 제안 → DiT에서 positional embedding을 완전히 제거한 첫번째 디자인
- 최신 연구들 중에는 NoPE가 더 나은 길이 일반화 능력을 가진다는 연구 결과들도 있음
Triton을 통한 학습/추론 가속화
- 선형 어텐션 연산의 가속화를 위해 Triton을 사용 → 선형 어텐션 블록의 순방향, 역방향 연산에 대해 커널을 결합하여 학습, 추론 속도 향상
- 활성 함수, 정밀도 변환, 패딩 연산, 나눗셈 등 모든 요소별 (element-wise) 연산을 행렬곱에 통합 → 데이터 전송에 따른 오버헤드를 줄임
2.3. Text Encoder Design
왜 인코더를 T5 대신 디코더 기반의 LLM으로 사용할까?
- 최근의 LLM 중 대부분은 디코더만 존재하는 GPT 구조를 가지며 많은 양의 데이터로 학습
- 2019년에 공개된 T5와 비교했을 때 디코더 기반의 LLM은 강력한 추론 능력을 가짐 → CoT (Chain-of-Thought) 등을 사용하여 복잡한 사람의 명령 (Complex Human Instruction, CHI)도 잘 따를 수 있고 ICL (In-context Learning)도 가능
- 추가적으로 Gemma-2와 같이 작은 몇몇 LLM은 큰 LLM과 유사한 성능을 가질 정도로 효율적 → 이에 따라 Gemma-2를 본 기법의 텍스트 인코더로 사용
- 표 9에서 볼 수 있듯이 T5-XXL과 비교했을 때 Gemma-2-2B는 6배 빠른 추론 속도를 가지지만 CLIP 점수나 FID를 비교했을 때 유사한 성능을 보임

LLM을 텍스트 인코더로 사용했을 때의 안정성
- Gemma-2 디코더의 마지막 레이어의 결과를 추출하여 텍스트 임베딩으로 사용
- 그리고 텍스트 임베딩을 크로스 어텐션 (cross attention의) key, value에, 이미지 토큰을 query에 적용하여 학습 → 이 경우 엄청나게 학습이 불안정해서 손실함수 값이 빈번하게 NaN이 발생
- 불안정성의 이유는?
- T5의 텍스트 임베딩 분산이 디코더 기반 LLM (e.g. Gemma-1-2B, Gemma-2-2B, Qwen-2-0.5B)의 텍스트 임베딩 분산에 비해 훨씬 작음
- 이에 따라 LLM 기반 텍스트 임베딩 출력의 절대값이 크게 도출되는 경우가 많음
- 이 문제의 해결을 위해 정규화 레이어 (i.e. RMSNorm)을 디코더 기반 텍스트 인코더 출력 뒤에 추가
- 텍스트 임베딩의 분산을 1로 정규화
- 불안정성의 이유는?
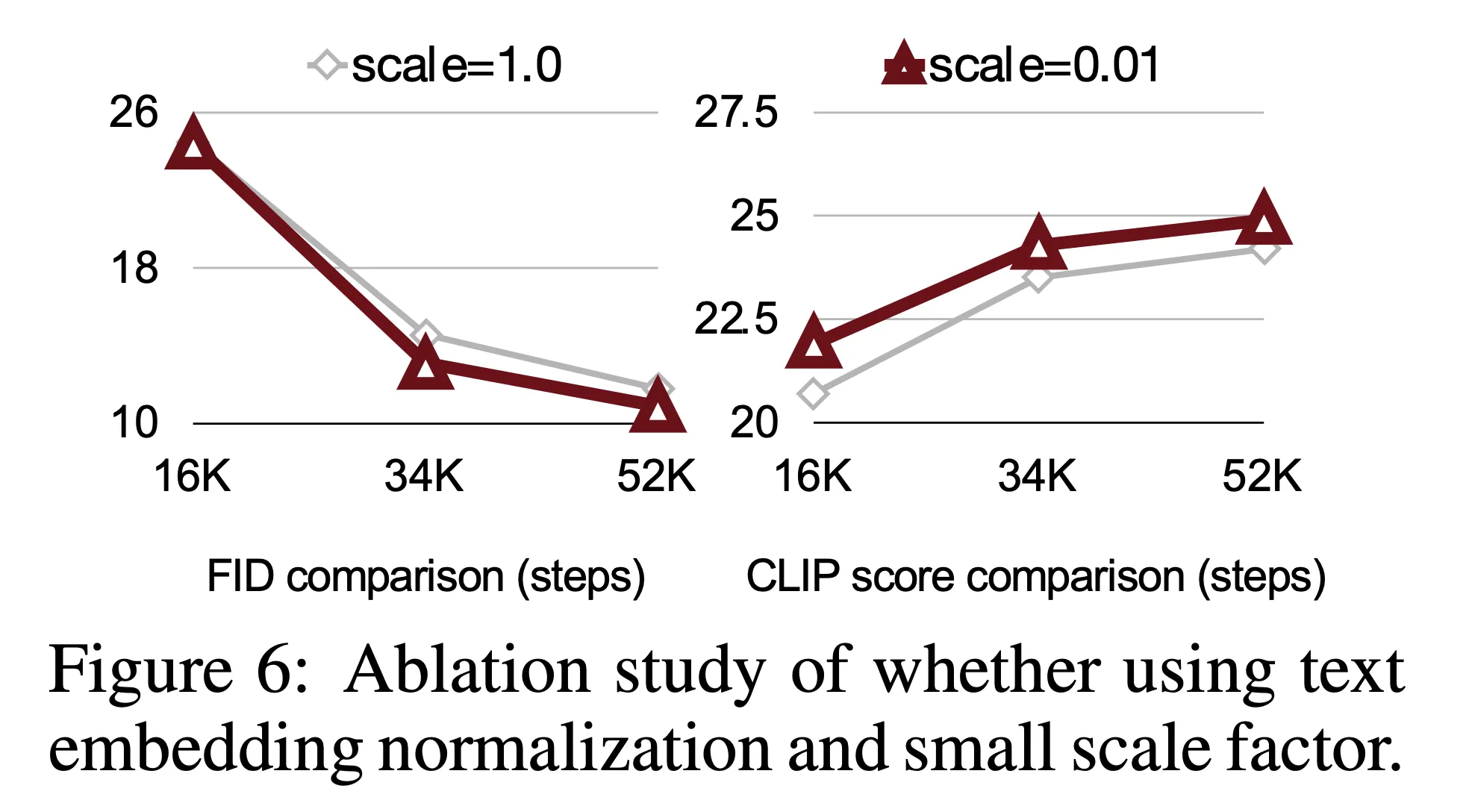
- 그리고 모델의 수렴 속도 향상을 위해 초기에 학습 가능한 작은 크기의 스케일 인자 (e.g. 0.01)를 초기화하고 이를 텍스트 임베딩에 곱해줌
- 결과는 그림 6 참고
복잡한 사람의 명령 (CHI)이 텍스트-이미지 일치도를 개선
- 위에서 언급한대로 Gemma는 명령을 따르는 능력이 T5보다 뛰어나지만 채팅 모델인 만큼 결과가 예측 불가능한 면이 있음
- 이에 따라 인코더의 프롬프트에 명령을 추가 → 본 논문에서는 CHI를 디자인하기 위해 LLM의 ICL을 사용
- 표 2에서 볼 수 있듯이 학습 중에 CHI를 결합하는 것이 처음부터 학습하는 경우에도, 파인튜닝 하는 경우에도 이미지-텍스트 일치도 능력의 성능을 향상시키는 것을 확인할 수 있음

- 그림 7에서 볼 수 있듯이 “a cat”이라는 짧은 프롬프트를 제공했을 때 CHI는 모델이 더욱 안정적인 결과를 도출하도록 도움
- CHI를 사용하지 않은 모델이 종종 프롬프트와 상관없는 결과를 도출하는 것도 살펴볼 수 있음

3. Efficient Training / Inference
3.1. Data Curation and Blending
멀티 캡션 자동 라벨링 파이프라인
- 각 이미지에 대해 해당 이미지가 기존에 프롬프트를 가지고 있던지 아니던지 4개의 VLM을 사용하여 라벨링을 수행
- 4개의 VLM: VILA-3B, VILA-13B, InternVL2-8B, InternVL2-26B
- 다수의 VLM은 캡션을 더욱 정확하면서도 다양하게 만들어줌
CLIP 점수 기반 캡션 샘플러
- 멀티 캡션은 학습 도중 이미지를 위한 다수의 캡션들 중에 하나를 선택해야하는 문제가 있음
- 본 논문에서는 CLIP 점수 기반 샘플러를 사용 → 높은 품질의 텍스트가 샘플링 될 확률을 증가시킴
- 먼저 이미지에 대응하는 모든 캡션들에 대해 CLIP 점수 $c_i$를 계산
- 여기서는 추가적인 하이퍼파라미터인 temperature $\tau$를 사용 → 확률에 대한 식 $P(c_i) = \frac{\exp (c_i / \tau)}{\sum_{j=1}^{N}\exp(c_j / \tau)}$에서 temperature는 샘플링 확률을 조절하는데 사용
- Temperature가 0에 가까운 경우 가장 CLIP 점수가 높은 텍스트가 샘플링 됨
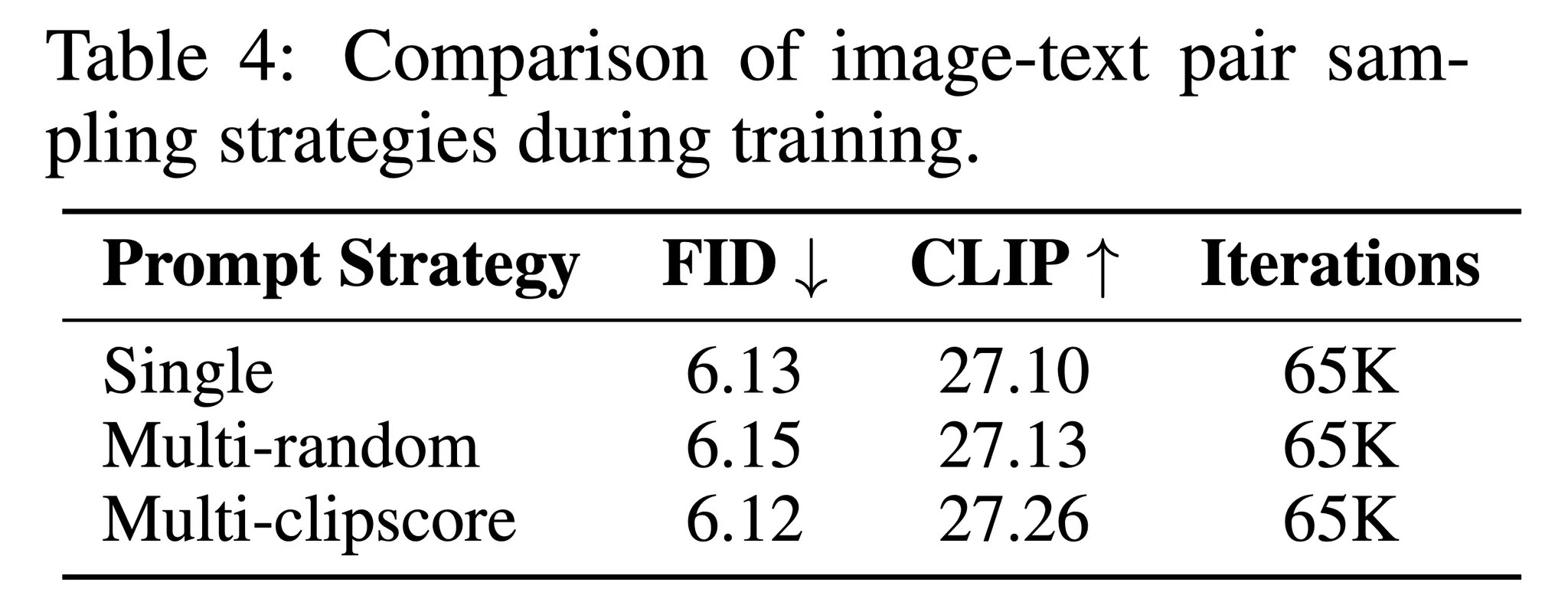
- 표 4의 결과를 통해 캡션의 다양성이 이미지 품질 (FID)에서는 적은 효과를 가지지만 학습 동안 의미적인 일치도를 개선하는 것을 알 수 있음
계단식 (Cascade) 해상도 학습
- AE-F32C32P1의 이점으로 인해 256px 사전 학습은 스킵하고 바로 512px 해상도로 사전학습 진행
- 그리고 점진적으로 모델을 1024px, 2K, 4K 해상도로 파인튜닝
- 256 해상도의 경우 자세한 정보를 잃기 때문에 이미지-텍스트 일치도 학습에 대해 모델이 느리게 학습
3.2. Flow-baesd Training / Inference
Flow 기반 학습
- SD3의 Rectified Flow의 뛰어난 성능에 대해 분석
- 노이즈를 예측하는 DDPM과 다르게 1-Rectified Flow (RF)와 EDM 모두 데이터나 속도 예측을 사용 → 빠른 수렴과 개선된 성능 달성
- 이런 모든 기법들은 공통된 확산 공식을 사용 → $x_t = \alpha_t \cdot x_i + \sigma_t \cdot \epsilon$
- $x_0$: 이미지 데이터
- $\epsilon$: 랜덤 노이즈
- $\alpha_t, \sigma_t$: 확산 과정의 하이퍼파라미터
- DDPM 학습에서는 목표가 노이즈를 예측 하는 것 → $\epsilon_\theta (x_t, t) = \epsilon_t$
- 그러나 EDM과 RF는 다른 접근을 사용
- EDM은 데이터 예측을 수행 → 목표: $x_\theta (x_t, t) = x_0$
- RF는 속도 예측을 수행 → 목표: $v_{\theta} (x_t, t) = \epsilon - x_0$
- 노이즈 예측에서 데이터나 속도 예측으로 전환은 $t=T$에 가까울수록 더욱 많은 영향을 미침
- 노이즈 예측은 불안정할 수 있는 반면 데이터나 속도 예측은 더욱 정확하고 안정적인 예측이 가능하도록 함
- 이런 변경은 샘플링 하는 동안 효율적으로 누적 에러를 감소시키고 빠른 수렴, 개선된 성능을 달성
Flow 기반 추론
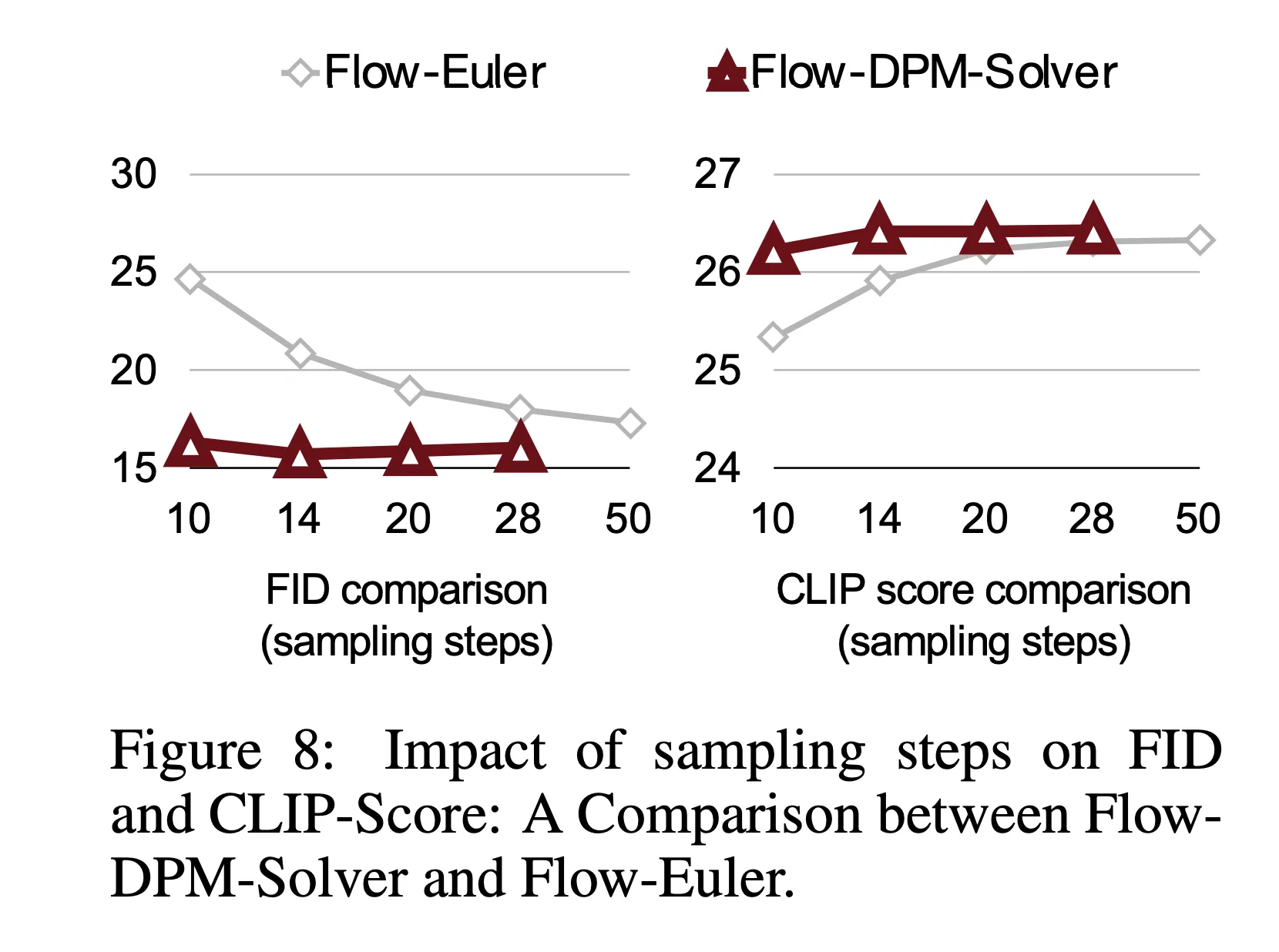
- 기존 DPM-Solver++를 수정 → Rectified Flow의 수식을 적용 ⇒ Flow-DPM-Solver
- 주요한 변경사항
- 스케일링 계수를 $\alpha_t$를 $1-\sigma_t$로 대체 ($\sigma_t$는 변경없이 유지하되 시간 스텝을 [1,1000] 대신 [0,1] 범위로 새롭게 정의 → 이런 시간 스텝의 변경은 더 적은 신호-노이즈 비율을 달성
- 추가적으로 본 모델은 속도장 (Velocity Field)를 예측 → 이는 원래 DPM-Solver++의 데이터 예측과 다름
- 데이터는 관계 (Relation)를 통해 얻어짐: data ← $x_0 = x_T - \sigma_T \cdot v_{\theta} (x_T, t_T)$
- $v_{\theta}(\cdot)$은 모델에 의해 예측된 속도
- 주요한 변경사항
- 결과적으로 그림 8과 같이 본 논문의 Flow-DPM-Solver는 14-20 스텝만에 수렴하면서도 더 좋은 성능을 보이지만 Flow-Euler 샘플러는 수렴에 28-50 스텝이 걸리면서 성능도 더 나쁨
4. On-Device Deployment
- 엣지 환경에서 배포 개선을 위해 모델을 8비트 정수 (8-bit INT)로 양자화
- 활성함수에 대해서는 토큰 단위 대칭 (per-token symmetric) INT8 양자화를, 가중치에는 채널 단위 대칭 (per-channel symmetric) INT8 양자화 적용
- 실행 시간을 최소화하면서도 16비트와의 높은 의미적 유사성 유지를 위해 아래 층들은 전체 정밀도 (full precision) 사용
- 크로스 어텐션 블록의 정규화 층, 선형 어텐션, key-value 프로젝션층
- CUDA C++로 W8A8 GEMM 커널을 구현하고 불필요한 활성화 불러오기 및 저장에 따른 오버헤드 감소를 위해 커널 퓨전 (kernel fusion) 기법을 적용하여 전체 성능 향상
- 선형 어텐션의 $ReLU(K)^TV$ 곱을 $QKV$ 프로젝션 층에 통합
- GLU (Gated Linear Unit)를 Mix-FFN의 양자화 커널에 융합
- GEMM 및 Conv 커널에서 transpose 연산이 발생하지 않도록 활성화 레이아웃 조정
- 표 5는 4090 GPU를 가진 엣지 기기에서 최적화 적용 전후의 속도 비교 결과를 보임
- 최적화 구현 적용시 2.4배 속도 향상을 달성하여 0.37초만에 1024px 이미지 생성 (이미지 품질에서는 거의 손실이 없음)
5. Experiments
모델 세부 사항
- 표 6은 네트워크 구조에 대한 세부적인 내용을 설명

- Sana-0.6B는 오직 590M 정도의 파라미터로 구성
- Sana-1.6B는 파라미터의 수가 증가 → 20 레이어와 레이어 당 2240 채널, FFN에서 채널을 5600으로 증가시킴
- 모델 레이어를 20 - 30으로 사용하는 것이 효율과 품질 사이에서 좋은 균형을 보임
5.1. Performance Comparison and Analysis
- Sana를 최신의 text-to-image 확산 모델과 성능 비교 → 표 7 참고

- 512x512 해상도 → Sana-0.6B vs. PixArt
- 비슷한 사이즈임에도 5배 빠른 추론속도를 보임
- FID, CLIP 점수, GenEval, DPG-Bench에서 월등하게 뛰어난 성능을 보임
- 1024x1024 해상도
- 대부분의 <3B 파라미터 모델에 비해 강력한 성능과 빠른 추론속도 달성
- FLUX-dev와 같이 큰 최신 모델과 비교했을 때도 경쟁력 있는 성능을 보임
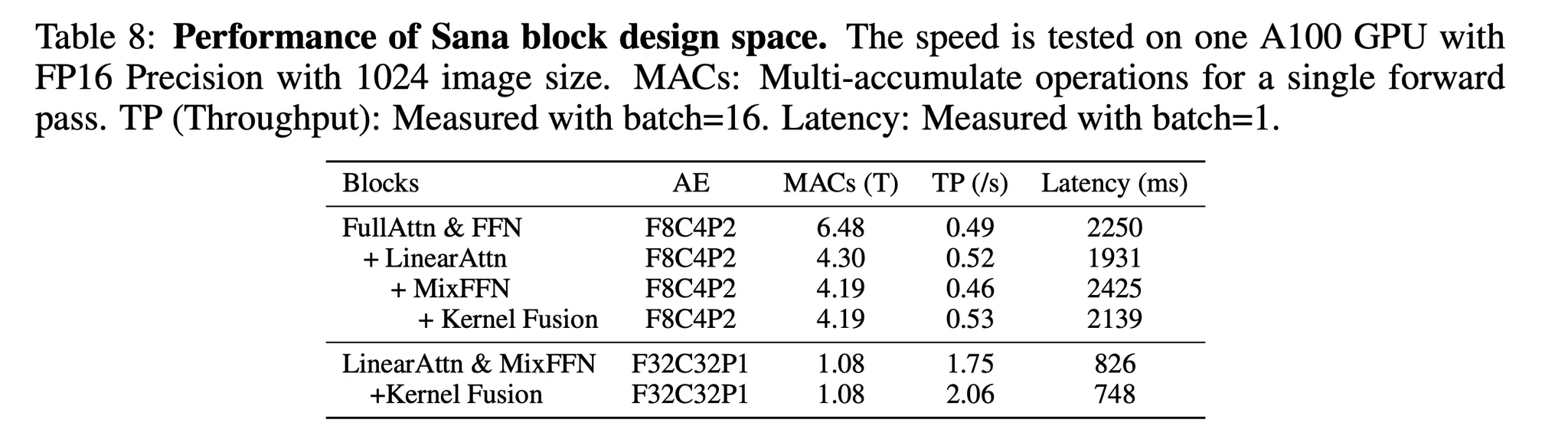
- 표 8에서 1024x1024 해상도 이미지 세팅이서 기존 DiT의 모듈을 선형 DiT 모듈로 대체했을 때 효율을 분석

- AE-F8C4P2를 사용했을 때
- 기존 어텐션을 선형 어텐션으로 대체했을 때 지연이 2250ms 에서 1931로 감소하는 것을 확인할 수 있으나 생성 성능 저하 발생
- 기존 FFN을 Mix-FFN으로 변경한 경우 약간의 효율을 희생하여 성능 저하를 보완
- Triton의 커널 퓨전을 사용한 경우 선형 DiT는 1024px 스케일에서 기존 DiT보다 약간 빨라지며 더 고해상도에서는 더욱 빨라짐
- AE-F8C4P2를 AE-F32C32P1으로 업그레이드 한 경우
- MACs가 4x 감소했으며 연산 시간도 4x 개선
- Triton 커널 퓨전은 ~10%의 속도 향상을 달성
- 그림 9의 왼쪽에서는 Sana의 생성 결과를 Flux-dev, SD3, PixArt와 비교
- 첫번째 행은 텍스트 랜더링 결과
- PixArt는 텍스트 랜더링 능력이 떨어지는 반면 Sana는 텍스트를 정확하게 랜더링
- 두번째 행에서는 Sana와 FLUX의 이미지 생성 품질의 유사한 정도이며 SD3는 텍스트를 부정확하게 이해
- 첫번째 행은 텍스트 랜더링 결과
- 그림 9의 오른쪽에서는 Sana가 노트북에 성공적으로 적용된 결과를 보임

6. Conclusion
- 본 논문은 Sana라는 효율적인 text-to-image 파이프라인을 소개
- 다음과 같은 개선점들을 가지고 있음
- 심층 압축 오토인코더
- DiT의 셀프 어텐션을 선형 어텐션으로 대체
- 디코더 기반 LLM 텍스트 인코더
- 자동 이미지 캡션 파이프라인
- Flow 기반 DPM-Solver
- Sana는 최대 4096x4096 해상도까지 이미지를 생성할 수 있으며 최신 기법에 비해 100x 빠른 추론 속도를 보이면서도 경쟁할만한 성능을 달성
- 본 기법의 한계
- 생성된 이미지의 안전성 및 제어 가능성을 보장하지 못함
- 텍스트 랜더링, 얼굴이나 손 생성 등 복잡한 특정 케이스에 대해 어려움이 있음
반응형



