
- 논문 링크: https://github.com/Kwai-Kolors/Kolors/blob/master/imgs/Kolors_paper.pdf
- 깃허브: https://github.com/Kwai-Kolors/Kolors
0. Abstract

- Text-to-Image 합성을 위한 잠재 확산 모델 (Latent diffusion model) Kolors를 소개!
- Kolors의 특징
- 영어와 중국어에 대한 심도있는 이해
- 실제와 같은 인상적인 이미지
- Kolors 개발을 위한 3가지 주요 요소
- 언어 능력 향상
- 대형 언어 모델을 Stable Diffusion 3나 Imagen에서 사용된 T5가 아닌 General Language Model (GLM)을 사용 → 영어와 중국어 모두에 대한 이해 능력을 향상
- 학습 데이터에 대한 텍스트 캡셔닝을 다시 수행하여 텍스트에 대한 심도있는 이해 능력을 개선
- Kolors의 학습
- 2단계의 학습 과정
- 컨셉 학습 단계 (Concept learning phase): 넓은 범위의 지식을 학습
- 품질 개선 단계 (Quality improvement phase): 미적 품질이 높은 데이터를 선별 및 학습
- 또한 고해상도의 이미지 생성을 최적화하기 위한 새로운 노이즈 스케줄 제안
- 2단계의 학습 과정
- 균형잡힌 카테고리를 가지는 KolorsPrompt를 통해 평가
- 사람 평가에서 기존 오픈소스 모델의 성능을 제치고 Midjourney-v6 수준의 성능 달성
- 언어 능력 향상
1. Introduction
- 확산 기반의 Text-to-Image (T2I) 생성 모델은 이미지 생성 문제에 있어 많은 진보를 가져옴
- U-Net 구조 기반의 대표 모델: Stability AI의 SDXL, Google의 Imagen, Meta의 Emu
- Transformer 기반의 대표 모델: PixArt-$\alpha$, Stable Diffusion 3
- 하지만 위의 모델들은 직접적으로 중국어 텍스트를 사용할 수 없음
- 이에 따라 중국어 프롬프트의 이해 능력 개선을 위해 몇가지 모델들이 소개됨 → AltDiffusion, PAI-Diffusion, Taiyi-XL, Hunyuan-DiT
- 위 기법들의 경우 중국어 텍스트 인코딩을 위해 CLIP 모델을 사용
- Kolors는 U-Net 구조를 기반으로 하며 General Language Model (GLM)을 사용하는 확산 모델
- 멀티모달 대형 언어 모델을 통해 얻은 세분화된 프롬프트를 사용하여 학습한 GLM을 적용 → 영어와 중국어 모두에 대해 높은 이해도를 보이며 텍스트 랜더링 부분에서도 뛰어난 성능을 보임
- 2단계의 학습 과정을 가짐
- KolorsPrompt 벤치마크를 기반으로 사람 평가 수행 → 시각적인 측면에서 뛰어난 성능을 보임
- 코드와 모델 가중치 모두 공개!! → https://github.com/Kwai-Kolors/Kolors
- 논문의 Contribution
- 텍스트 관련
- 영어와 중국어 모두에 대해 적절한 텍스트 표현 (representation)을 생성하기 위해 GLM을 대형 언어 모델로 사용
- 학습 이미지에 대해 멀티모달 대형 언어 모델로 생성된 자세한 설명을 사용
- Kolors는 복잡한 문맥, 특히 다수의 요소들이 있는 시나리오에서 좋은 성능을 보였으며 텍스트 렌더링 측면에서 뛰어난 성능을 보임
- 2단계 학습을 수행
- 컨셉 학습 단계에서는 넓은 지식을, 품질 개선 단계에서는 미적 품질이 높은 데이터를 선별하여 학습
- 고화질의 이미지 생성 최적화를 위한 새로운 스케줄 제안
- 위 전략들을 기반으로 고화질 이미지 생성에서 시각적 품질을 향상
- 균형잡힌 카테고리를 가지는 벤치마크인 KolorsPrompts를 기반으로 성능 평가
- 다수의 오픈, 클로즈 소스 모델들고 비교했을 때 뛰어난 성능을 보임 (e.g. Stable Diffusion 3, DALL-E 3, Playground-v2.5, Midjourney-v6)
- 텍스트 관련
2. Methods
2.1. Enhancing Text Faithfulness
2.1.1. Large Language Model as Text Encoder
- 텍스트 인코더는 text-to-image 생성 모델에 있어 중요한 요소 → 모델에 의해 생성되는 컨텐츠를 제어할 수 있으며 직접적으로 영향을 미침
- 일반적으로 이미지 생성 모델에서 사용되는 텍스트 인코더들을 표 1에서 살펴볼 수 있음

- 일반적으로는 CLIP이나 T5 모델을 주로 사용
- CLIP 모델을 텍스트 인코더로 사용한 모델: SD 1.5, DALL-E 2
- CLIP의 경우 contrastive 손실함수로 학습되어 이미지와 텍스트 설명에 대한 align을 수행
- 이는 다수의 대상, 위치, 색 등에 대해 상세한 이미지 설명을 이해하는데 좋지 못한 성능을 보임
- 인코더-디코더 구조의 transformer인 T5를 통해 텍스트 임베딩을 추출하는 경우: Imagen, PixArt-$\alpha$
- 다수의 텍스트 인코더를 사용하는 경우
- eDiff-I: 전역적, 지역적 텍스트 표현을 위해 CLIP과 T5를 결합하여 텍스트 인코더로 사용
- SDXL: 두개의 CLIP 모델을 사용하여 오픈소스 커뮤니티에서 좋은 성능 달성
- Stable Diffusion 3: T5-XXL 텍스트 인코더를 모델 구조에 결합
- LuminaT2X: 사전학습된 LLM 모델인 LLama2를 사용하여 텍스트를 어떤 모달리티로든 변환할 수 있는 통합 구조 제안

- 대부분의 text-to-image 생성 모델들은 CLIP이 영어 기반 모델이라는 한계 때문에 중국어 프롬프트 사용에 어려움이 있음
- HunyuanDiT는 이 문제의 해결을 위해 2개 국어 CLIP과 다국어 T5 모델을 사용하여 중국어 기반 text-to-image 모델을 학습
- 그러나 다국어 T5 모델에는 중국어가 2% 이하로 구성되어있고 2개 국어 CLIP도 복잡한 텍스트 프롬프트를 다루기에는 적절하지 않음
- 위 문제의 해결을 위해서 Kolors에서는 General Language Model (GLM)을 텍스트 인코더로 사용
- GLM은 2개 국어 (영어, 중국어)가 가능한 사전 학습 언어 모델로 자연어 이해 및 생성 문제에서 BERT와 T5의 성능을 크게 능가한 모델
- 본 논문에서는 오픈소스 ChatGLM3-6B-Base 모델을 텍스트 인코더로 사용
- 77 토큰만을 사용하는 CLIP에 비해 ChatGLM3는 256 토큰까지 텍스트 길이를 사용하므로 더 자세하고 복잡한 텍스트 이해가 가능함
2.1.2. Improved Detailed Caption with Multimodal Large Language Model
- 학습을 위한 텍스트-이미지 쌍은 대부분 인터넷을 통해 취득 → 노이지하고 부정확함
- DALL-E 3의 경우 이를 해결하기 위해 학습 데이터에 대한 캡셔닝을 다시 수행
- Kolors의 프롬프트 추종 능력을 향상 시키기 위해 DALL-E 3와 유사하게 멀티모달 대형 언어 모델 (Multimodal Large Language Model, MLLM)을 사용하여 다시 캡셔닝을 수행
- 텍스트 설명의 품질을 평가하기 위한 5가지 기준
- 길이 (Length): 중국어 글자의 전체 .
- 완성도 (Completeness): 이미지 전체에 대한 텍스트 설명 정도 → 5점은 텍스트가 이미지 내의 모든 대상을 묘사하는 경우, 1점은 30% 이하의 대상을 묘사하는 경우
- 상관 관계 (Correlation): 이미지의 전방에 있는 요소를 나타내는 텍스트 설명의 정확도, 5점의 경우 모든 전방의 요소를 설명하는 경우, 1점은 전방 대상의 30% 이하만 설명하는 경우
- 환각 (Hallucination): 이미지 내에 존재하지 않는 것들을 텍스트로 묘사하는 비율, 5점은 환각이 없는 경우, 1점은 텍스트의 50% 이상이 환각을 포함하는 경우
- 주관성 (Subjectivity): 이미지에 대한 시각적인 내용이 아니라 주관적인 인상을 전달하는 텍스트, “편하고 고요한 느낌을 주어 사람들을 편안하게 한다” 같은 문장은 주관적인 문장 → 주관적이지 않은 텍스트는 5점, 텍스트의 50% 이상이 주관적인 내용이면 1점
- 평균 (Avg): 완성도, 상관관계, 환각, 주관성의 평균 점수
- 본 논문에서는 5개의 유명한 MLLM 모델과 10명의 평가자를 통해 500개 이미지를 평가
- 5개의 MLLM 모델 비교
- LLaVA 1.5, CogAgent, CogVLM은 중국어 텍스트를 지원하지만 영어에 비해 성능이 떨어지므로 먼저 영어로 이미지 캡션을 생성하고 중국어로 번역
- InternLM-XComposer-7B와 GPT-4V는 중국어 프롬프트를 직접적으로 사용
- 5개 모델의 캡셔닝 성능을 표 2를 통해 살펴볼 수 있음

- GPT4-V가 가장 높은 성능을 달성했지만 비용과 시간이 너무 많이 필요함
- 다른 4개의 오픈소스 모델 중 LLaVA 1.5와 InternLM-XComposer가 CogAgent-VQA, CogVLM-1.1-chat에 비해 완성도나 상관 관계 측면에서 성능이 현저하게 떨어짐 → 자세한 설명에 대한 성능이 낮음
- CogVLM-1.1-chat에 의해 생성된 설명은 환각이나 주관성 경향을 덜 보임
- 위 결과에 따라 CogVLM-1.1-chat을 통해 학습 데이터셋에 대한 캡션을 생성하도록 함
- 하지만 MLLM은 지식 범위를 넘어서는 이미지의 내용에 대해서는 식별할 수 없음
- 이에 따라 50%의 기존 텍스트와 50%의 합성 캡션을 사용
- 5개의 MLLM 모델 비교
- Kolors의 경우 복잡한 중국어 텍스트를 따르는데 강인한 성능을 보임
- 그림 2를 살펴보면 복잡한 프롬프트에 대해 다른 텍스트 인코더를 사용했을 때 Kolors의 결과를 확인할 수 있음

- 위 결과를 보면 Kolors에 GLM을 사용한 경우 다수의 대상, 상세한 요소들에 대해 더 좋은 성능을 보이는 것을 확인할 수 있음
- CLIP의 경우 위의 프롬프트에서는 상인과 전화를 생성하지 못했으며 아래 프롬프트에서는 색에 대해 혼란이 있음
2.1.3. Enhancement of Chinese Text Rendering Capability
- 텍스트 렌더링 (텍스트를 포함한 이미지를 생성하는 것)은 text-to-image 생성 분야에서 오랫동안 어려운 문제였음
- DALL-E 3나 Stable Diffusion 3와 같은 모델들은 영어 텍스트를 렌더링 하는 것에는 좋은 성능을 보였지만 중국어 텍스트 렌더링을 정확하게 하는 것에는 많은 어려움이 있었음
- 중국어 텍스트 렌더링이 어려운 이유
- 중국어 글자 세트의 크기가 광범위하며 구조가 복잡함
- 학습 데이터에 중국어 텍스트를 포함하는 이미지가 거의 없음
- 해당 문제를 해결하기 위해 2가지 관점의 접근을 사용
- 자주 사용하는 중국어 단어 50,000개를 포함하는 이미지-텍스트 쌍 데이터 1000만개를 학습 데이터로 구축 → 해당 데이터는 컨셉 학습 단계에서만 사용됨
- 생성 이미지의 사실성을 높이기 위해 OCR과 MLLM을 사용하여 실제 이미지 (e.g. 포스터, 텍스트를 포함한 풍경, …)에 대한 설명을 생성 → 100만개 정도의 데이터 사용
- 텍스트 생성 결과는 그림 3 참고

- 위 결과를 통해 중국어 텍스트 렌더링의 품질이 크게 향상된 것을 확인할 수 있음
2.2. Improving Visual Appeal
- LDM (Latent Diffusion Models)는 이미지 생성 품질을 위해 때로 업스케일링이나 얼굴 복원 같은 후보정이 필요함
- 본 논문에서는 데이터와 학습 기법을 발전시켜서 해당 문제를 해결
2.2.1. High Quality Data
- Kolors의 학습은 2 단계로 나눠짐 → 컨셉 학습 단계, 품질 개선 단계
- 컨셉 학습 단계
- 아주 큰 규모의 데이터를 사용하여 모델이 이해력을 취득
- 해당 단계의 데이터는 공공 데이터 (e.g. LAION, DataComp, JourneyDB)와 사설 데이터 사용
- 품질 개선 단계
- 고해상도에서 이미지의 디테일과 미적 품질을 향상시키는 것에 집중
- 해당 단계가 데이터 품질 측면에서 핵심적인 부분!
- 고품질의 이미지-텍스트 쌍을 얻기 위해 전통적인 필터를 사용 (해상도, OCR 정확도, 얼굴 수, 미적 점수, 명료성, …)
- 5단계로 품질을 구분하며 주관적 편향 제거를 위해 각 이미지에 대해 3번의 주석을 달고 최종적으로 투표 과정을 통해 결정
- 이미지 단계의 특징은 다음과 같음
- 1단계: 포르노, 폭력성, 잔인함, 공포와 같이 안전하지 않은 컨텐츠
- 2단계: 인공적인 합성의 표시가 있는 이미지: 로고, 워터마크, 하얀색이나 검은색 경계 등
- 3단계: 블러, 노출 부족, 노출 과다, 명확하지 않은 이미지
- 4단계: 일반적인 스냅샷 사진 같은 평범한 사진
- 5단계: 높은 미적 품질을 가진 사진 → 적절한 노출, 대조, 색의 특성을 가지면서 서사를 전달
- 품질 개선 단계에서는 5단계의 높은 미적 품질을 가지는 이미지를 사용
2.2.2. Training on High Resolutions
- 확산 모델은 고해상도 이미지에 대해 때로 순방향 확산 과정 (forward diffusion process)에서 이미지의 붕괴가 발생하는 성능 저하가 가끔 발생
- 그림 4를 보면 SDXL에서 제공된 스케줄에 따라 노이즈가 추가되는 과정을 확인할 수 있음

- 저해상도 이미지의 경우 최종적으로 거의 순수한 노이즈에 가깝게 되지만 고해상도 이미지의 경우 최종 단계에서도 낮은 주파수로 (low frequency) 요소가 유지됨
- 모델은 추론 단계에서 순수한 가우시안 노이즈부터 시작해야하므로 이런 고해상도에서의 학습과 추론에 대한 차이가 성능 저하를 가져올 수 있음
- Kolors를 위해서 DDPM 기반의 학습 방법에 엡실론 예측 objective를 사용
- 컨셉 학습을 위한 저해상도의 학습 단계에서는 SDXL과 동일한 스케줄 사용
- 고해상도 학습에서는 새로운 스케줄을 사용 → 단순히 스텝의 수를 기존 1,000에서 1,100으로 확장
- $\beta$의 값을 조절하여 $\bar{\alpha_t}$ 커브의 모양을 유지 → $\bar{\alpha_t}$는 $x_t = \sqrt{\bar{\alpha_t}} x_0 + \sqrt{1-\bar{\alpha_t}}\epsilon$을 결정
- 그림 5에서 살펴볼 수 있듯이 $\bar{\alpha_t}$의 경로는 기본 스케줄의 경로를 완전히 포함 → 타 기법의 경로는 편차를 보임

- 그림 6을 확인하면 최적화된 고해상도 학습 기법을 사용하여 고품질 학습 데이터 기반 학습을 수행했을 때 생성 이미지의 품질이 크게 향상된 것을 확인할 수 있음

- 또한 다양한 비율의 이미지를 생성할 수 있도록 학습 과정에서 NovelAI의 bucketed sampling 기법을 사용
- 다른 해상도로 생성된 이미지 결과는 그림 1과 그림 9에서 살펴볼 수 있음
3. Evaluations
- Kolors의 생성 능력 평가를 위해 3가지 평가 지표를 사용
- KolorsPrompt: 다양한 카테고리와 문제들을 포함하는 프롬프트 세트
- Multi-dimensional Preference Score (MPS)
- FID
3.1. KolorsPrompt
- text-to-image 생성 모델을 평가하기 위해 벤치마크인 KolorsPrompt 공개
- PartiPrompts, ViLG-300 등의 공공 데이터와 몇몇 사설 데이터로부터 구성한 수천개의 프롬프트
- 실생활의 14개의 시나리오 (e.g. 사람, 음식, 동물, 예술 등)를 포함
- KolorsPrompt를 프롬프트의 특성에 따라 12개의 문제로 분류
- KolorsPrompt의 분포는 그림 7에서 살펴볼 수 있음
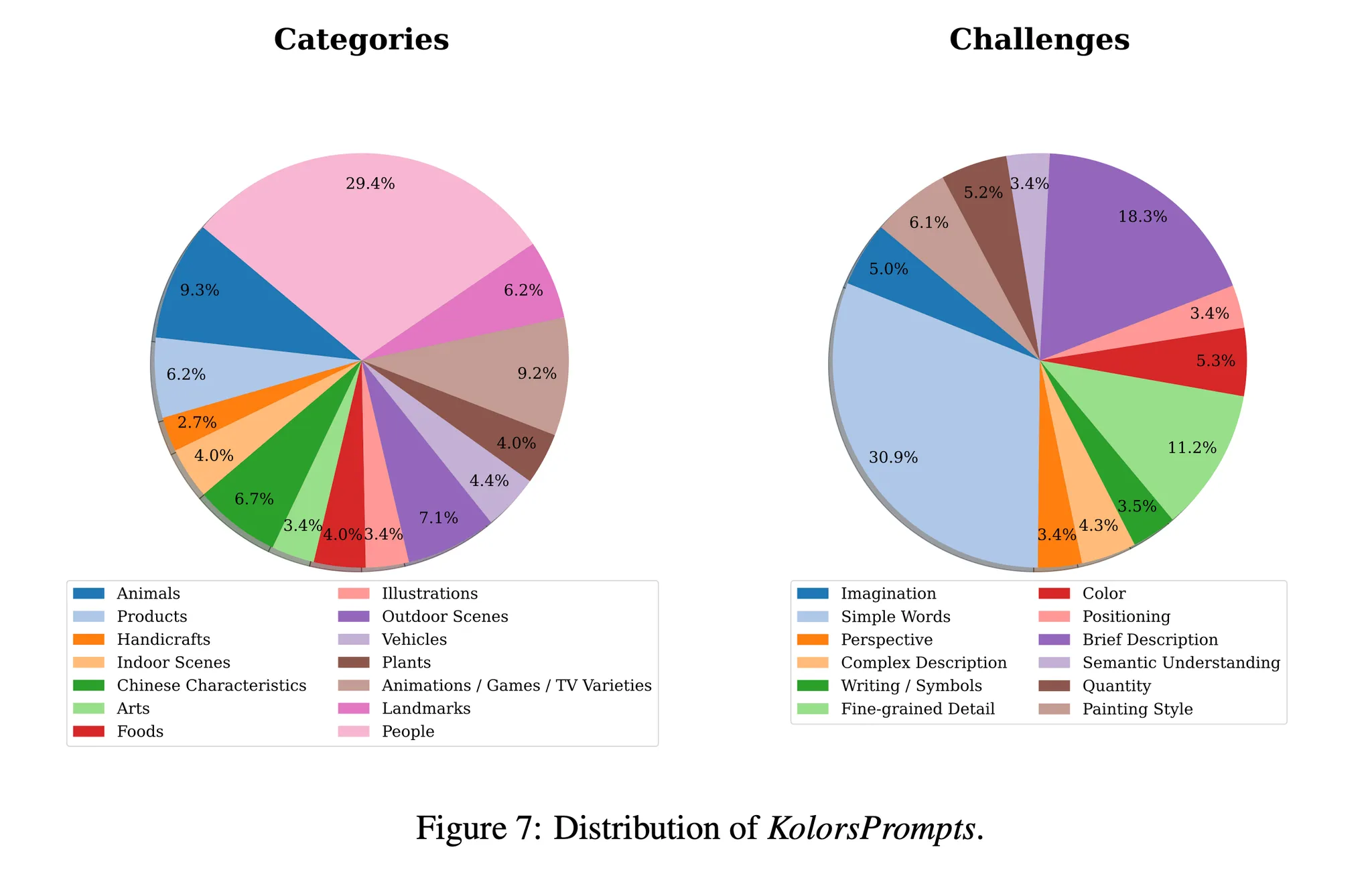
- 왼쪽은 KolorsPrompts의 카테고리 분포를 나타냄 → 사람 (People)이 가장 많은 29.4%를 차지
- 오른쪽은 문제의 분포를 나타냄 → 단순한 단어 (Simple words)가 가장 많은 30.9%를 차지
3.2. Human Evaluation
- 모델 성능 평가를 위해 3가지 사람 평가 지표를 사용
- 시각적 매력도 (Visual Appeal)
- 색, 모양, 텍스쳐 등 다양한 시각적인 요소들을 고려한 생성 이미지의 미적 품질을 평가
- 동일 프롬프트를 기반으로 다른 모델로 이미지를 생성 → 평가자에게 텍스트는 보여주지 않음 → 시각적인 부분에 대한 평가에 집중
- 점수는 1-5 범위로 평가 → 5는 완벽한 이미지, 1은 낮은 품질의 이미지
- 텍스트 신뢰도 (Text Faithfulness)
- 얼마나 생성된 이미지가 프롬프트를 정확하게 따르는지 평가
- 이미지의 품질과는 상관없이 오직 텍스트 설명과 이미지에만 집중
- 점수는 1-5의 범위로 평가
- 전체적인 만족도 (Overall Satisfaction)
- 이미지의 전체적인 평가를 나타냄
- 프롬프트와 이미지와 함께 표시됨
- 평가자는 이미지의 품질, 시각적 매력도, 프롬프트와 이미지 간의 일치도 등을 평가
- 시각적 매력도 (Visual Appeal)
- 평가 조건
- 모델은 프롬프트 당 4개의 이미지를 생성하여 평가됨
- 50명의 프로 리뷰어가 각 이미지를 구체적인 가이드라인과 함께 5번 평가
- 최종 점수는 5번의 평가 점수를 평균냄
- 각 이미지는 1024x1024 해상도로 랜더링
- 대조군 모델: Adobe Firefly, DALL-E 3, Stable Diffusion 3, Midjourney-v5, Midjourney-v6, Playground-v2.5
- 프롬프트는 영어를 사용
- 구체적인 결과는 그림 8에서 살펴볼 수 있음 → 가장 높은 전체적 만족도를 달성하였으며 Midjourney-v6와 유사한 성능 달성

- Kolors가 시각적 매력도 부분에서 뛰어난 성능을 보임
- Kolors의 추가적인 결과들은 그림 9에서 살펴볼 수 있음


3.3. Automatic Evaluation Benchmark
3.3.1. Multi-Dimensional Human Preference Score (MPS)
- 현재 text-to-image 모델을 평가하기 위한 지표들은 대부분 특정에만 의지 (e.g. FID, CLIP Score) → 사람의 선호를 나타내기 어려움
- Multi-Dimensional Human Preference Score (MPS)가 제안됨 → 다양한 측면에서 사람의 선호를 평가하고 text-to-image 모델의 효율성을 나타냄
- MPS의 결과는 표 3에서 살펴볼 수 있음

- Kolors가 사람 평가와 일치하는 높은 성능을 달성
- 해당 일치도는 KolorsPrompts 벤치마크를 사용했을 때 사람의 선호와 MPS 점수 사이에 높은 관계성이 있다는 것을 나타냄
3.3.2. Fidelity Assessment on COCO Dataset
- Kolors 모델을 text-to-image의 표준 평가 지표를 통해 평가 수행 → MS-COCO 256x256 검증 데이터를 사용하여 Zero-shot FID-30K 지표를 도출
- 결과는 표 4의 내용을 참고

- Kolors는 약간 높은 FID 점수를 달성하여 좋지 못한 결과를 보임
- 하지만 많은 연구들이 COCO를 이용한 zero-shot FID는 시각적인 미적 품질과 음의 상관관계가 있다는 것을 보임
- 이에 따라 본 논문에서는 text-to-image 모델의 성능 평가는 통계적인 지표보다 사람의 측정이 더 정확하다고 주장
- 이에 따라 실제 사람의 선호와 일치하는 MPS 같은 자동 평가 시스템이 구축되어야한다는 필요성을 강조
4. Conclusions
- 본 논문에서는 U-Net 구조 기반의 잠재 확산 모델인 Kolors 모델을 제안
- General Language Model (GLM)과 CogVLM에 의해 생성된 상세한 캡션을 사용하여 복잡한 문맥에 대한 이해도를 높이고 다수의 객체, 텍스트 랜더링 능력 등을 향상시킴
- Kolors는 두 단계로 학습됨 → 컨셉 학습 단계, 품질 개선 단계
- 높은 수준의 미적 데이터와 고해상도 이미지 생성을 위한 새로운 스케줄을 사용 → 고해상도 이미지에서 시각적인 품질을 크게 향상시킴
- 카테고리에 대한 균형이 잡힌 KolorsPrompt 벤치마크를 사용하여 text-to-image 모델을 평가
- Kolors가 사람 평가에서 뛰어난 성능을 보임 → Stable Diffusion 3, Playground-v2.5, DALL-E 3 등 대부분의 오픈소스 성능을 능가하며 Midjourney-v6과 유사한 성능을 보임
- 추후 수행할 것
- Kolors에 대한 다양한 플러그인 공개 → ControlNet, IP-Adapter, LCM, …
- Transformer 구조 기반의 새로운 확산 모델 공개



