반응형

0. Abstract
- 최근 text-to-image 생성 모델은 다양한 시각적인 창의성을 발휘할 수 있도록 했지만 스토리 시각화, 게임 개발, 에셋 디자인, 광고 등과 같은 실생활 문제들에 적용될 수 있는 일관된 캐릭터 (consistent character) 생성에는 어려움이 있음
- 본 논문에서는 일관된 캐릭터 생성을 자동으로 수행할 수 있는 기법을 제안
- 입력으로는 오직 텍스트 프롬프트만을 사용
- 반복적인 과정을 수행하며 각 단계마다 유사한 특성을 가지는 연관된 이미지 세트를 식별하고 해당 세트로부터 일관된 특성을 추출
- 정량적 결과에서 프롬프트 일치도와 특성 유지 사이에서 기존 베이스라인 기법들보다 더 균형있는 결과를 보임
1. Introduction

- 그림 1과 같이 생성된 이미지 컨텐츠의 일관성을 유지하면서 다양한 장면을 생성하는 것은 다양한 창의적 사용이 가능
- Text-to-Image 생성 모델의 능력은 갈수록 인상적으로 되고 있지만 해당 모델들이 이렇게 일관적인 생성을 하는 것은 어려운 문제
- 본 논문에서는 일관된 캐릭터 생성 (consistent character generation)을 수행하는 연구를 수행 → 캐릭터를 설명하는 텍스트 프롬프트만 입력하면 동일한 캐릭터를 새로운 상황에서 생성하는 것이 가능하도록 함

- 예를 들어 그림 2와 같이 “점토로 된 고양이 캐릭터”의 그림을 생성한 경우 최신의 text-to-image 모델로 캐릭터를 설명하는 프롬프트를 사용해도 다양한 결과를 도출하며 일관성이 부족한 모습을 보임 (위쪽 줄)
- 하지만 본 논문의 기법은 고양이의 일관된 표현 (representation)을 정제하여 동일한 캐릭터가 여러 다른 장면에서 묘사될 수 있도록 함
- 본 연구의 목표
- 일관된 캐릭터를 새로운 장면들에서 생성
- 단일 자연어 설명만을 사용하여 캐릭터의 일관적 특성을 자동적으로 정제 → 입력으로 타겟 캐릭터의 어떤 이미지도 필요로 하지 않음
- 본 연구의 가정
- 특정 프롬프트에 대해 충분히 큰 생성 이미지 세트가 있고 공통의 특징을 가지는 이미지의 그룹들을 포함
- 특정 군집이 주어졌을 때 이미지들 사이에서 “공통점”을 파악할 수 있는 특징 추출이 가능해야함
- 위 가정의 과정을 반복하다보면 입력 프롬프트에 대한 충실도는 높으면서도 생성된 이미지들 간의 일관성을 향상시킬 수 있음
- 본 기법의 진행 과정
- 제공된 텍스트 프롬프트를 기반으로 다수의 이미지를 생성
- 사전학습된 특징 추출 모델 (feature extractor)을 사용하여 이미지를 유클리드 공간에 임베딩
- 해당 임베딩들을 군집화 → 가장 응집된 (cohesive) 군집을 개인화 (personalization) 기법의 입력으로 사용 → 일관된 특징을 추출하도록 학습
- 그리고 학습이 진행된 모델을 사용하여 텍스트 프롬프트를 묘사하면서도 일관성이 향상된 다수의 이미지를 다시 생성
- 위 과정을 수렴할 때까지 진행
- 본 논문의 기법을 정량적, 정성적으로 평가하고 최종적으로 본 논문의 기법을 응용할 수 있는 사례들을 소개
- 본 논문의 contribution
- 일관된 캐릭터 생성 문제를 정의
- 해당 문제를 풀기 위한 새로운 기법을 제안
- 해당 기법을 정량, 정성적으로 평가하고 실제 사람 평가도 수행하여 해당 기법의 효율성을 보임
2. Method
- 본 기법의 목표 → 텍스트 묘사를 기반으로 특정 캐릭터에 대해 일관된 이미지를 생성하는 것
- 제안된 기법의 구현 과정
- 모델에 의해 생성된 이미지의 세트 자체를 학습 데이터로 사용하여 반복적으로 사전학습 된 text-to-image 모델을 학습
- 모델의 출력으로부터 일관된 특징을 반복적으로 정제하여 타겟 캐릭터의 표현을 구체화
- 해당 과정이 수렴하면 결과적으로 취득한 모델은 새로운 장면에서 타겟 캐릭터의 일관된 이미지를 생성하는데 사용될 수 있음
- 정의
- text-to-image 모델 $M_{\Theta}$ ($\Theta$로 파라미터화)
- $\Theta$는 모델 가중치 $\theta$의 세트와 텍스트 임베딩 $\tau$의 세트로 구성되어 있음
- 텍스트 프롬프트 $p$
- $\Theta(p)$ → $M_{\Theta(p)}$로 파라미터화 된 모델은 $p$로 묘사된 캐릭터에 대한 일관적 이미지를 새로운 장면에서 생성할 수 있음
- text-to-image 모델 $M_{\Theta}$ ($\Theta$로 파라미터화)
- 본 논문의 기법을 알고리즘 1과 그림 3을 통해 살펴볼 수 있음
-

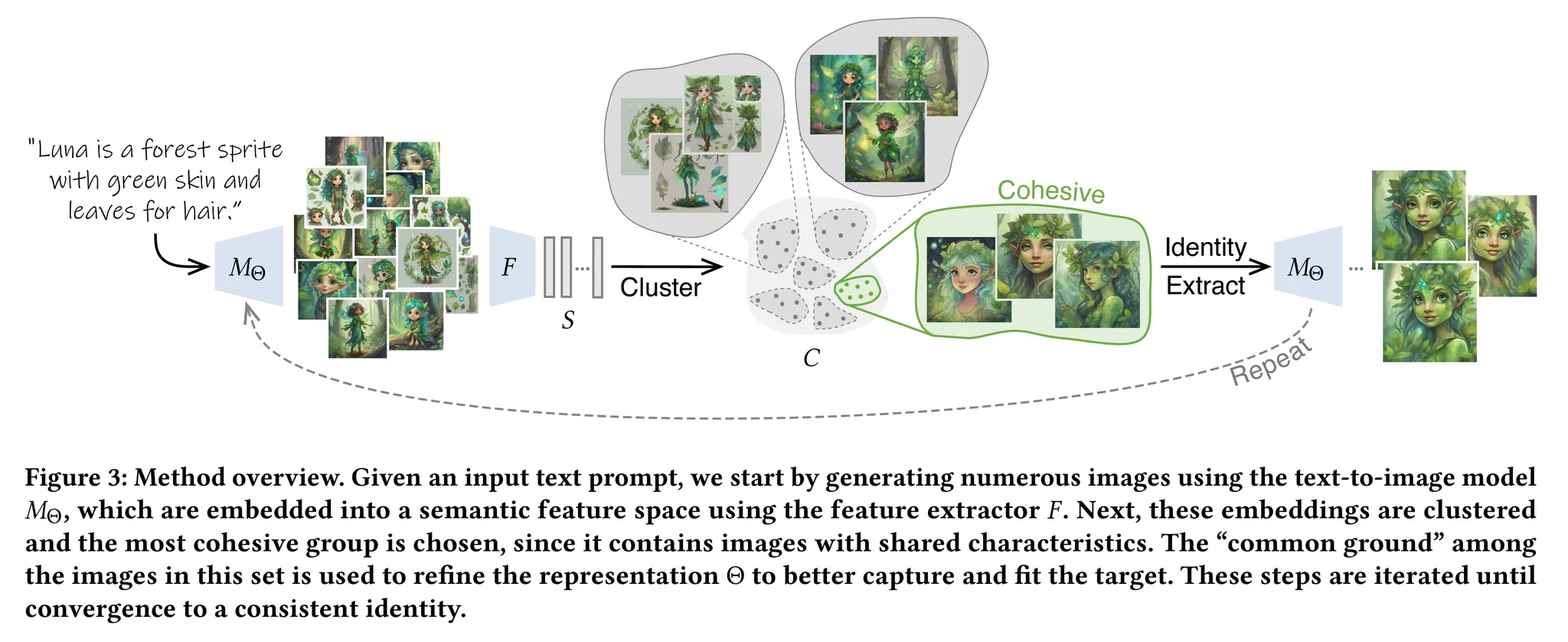
- 동일한 프롬프트로 다른 시드를 사용하여 생성된 충분히 큰 이미지 세트를 기반으로 함
- 이때 이미지들 사이의 공통점은 표현 $\Theta(p)$를 정제하는데 사용될 수 있음
- 이에 따라 본 논문에서는 반복적으로 이미지의 군집을 생성하고 가장 응집된 군집으로 $\Theta(p)$를 정제 → $\Theta(p)$가 수렴할 때까지 반복적으로 수행
2.1. Identity Clustering
- 각 반복은 $M_{\Theta}$ (현재의 표현 $\Theta$로 파라미터화)로 시작됨 → $N$개의 이미지들을 생성 (각 이미지는 다른 시드를 가짐)
- 각 이미지는 고차원의 임베딩 공간으로 임베딩 됨 → 특징 추출 모델 $F$ 사용 → 임베딩 세트 $S=\bigcup_N F(M_{\Theta}(p))$
- 이때는 DINO v2를 사용
- 그리고 K-MEANS++를 사용하여 생성된 이미지의 임베딩들을 군집화 → 임베딩 공간에서 코사인 유사도 사용
- 군집들 $C$에서 크기가 사전에 정의한 $d_{min-c}$보다 작은 군집들은 모두 제거
- 남아있는 군집들 중 가장 응집된 군집을 특징 추출 단계를 위한 입력으로 사용 → 그림 4 참고

- 군집 $c$의 응집도는 중심 $c_{cen}$과 $c$를 구성하는 각 요소들의 사이의 거리의 평균으로 결정

- 그림 4를 통해 DINO v2의 임베딩 공간을 시각화 한 결과를 살펴볼 수 있음 → 고차원의 임베딩 $S$를 t-SNE를 통해 2차원으로 투영하고 K-MEANS++에 의해 결정된 군집에 따라 색을 설정
- 검정색 군집이 가장 응집된 군집
2.2. Identity Extraction
- 그림 3에서 볼 수 있듯이 가장 응집된 군집인 $c_{cohesive}$도 어느정도 일관되지 않은 특징을 보임
- 이는 $\Theta$가 아직 일관적인 생성을 위해 준비되지 않았기 때문 → 이를 $c_{cohesive}$의 이미지들을 통해 학습하는 방식으로 정제하여 더욱 일관된 특징을 추출
- 해당 정제는 text-to-image 개인화 기법들을 통해 수행됨 (e.g. Textual Inversion, DreamBooth)
- 일관된 특징을 가진 몇장의 주어진 이미지 세트에서 특징을 추출하는 기법
- 비록 이미지들이 완전히 일관된 특징을 가지지 않더라도 해당 이미지 간의 유사성을 통해 공통된 특징을 추출하는 것이 가능
- 해당 기법을 위한 기반 모델은 사전학습된 Stable Diffusion XL (SDXL)
- 2개의 텍스트 인코더 사용: CLIP, OpenCLIP
- Textual Inversion 기법을 사용하여 2개의 인코더 각각에 새로운 텍스트 토큰 $\tau$의 쌍을 추가
- 모델의 가중치 $\theta$는 LoRA (Low-Rank Adaptation)을 통해 업데이트
- 일반적인 디노이징 손실함수 사용

- $c_{cohesive}$: 선택된 군집
- $E(x)$: SDXL의 VAE 인코더
- $\epsilon$: 샘플의 노이즈
- $t$: 타임스텝
- $z_t$: 타임스텝 $t$의 latent $z$
- $\mathcal{L}_{rec}$은 $\Theta=(\theta, \tau)$에 대해 최적화 수행 → LoRA 가중치와 새롭게 추가된 텍스트 토큰
2.3. Convergence
- 앞서 알고리즘 1과 그림 3을 통해 설명했듯이 위 과정은 반복적으로 수행됨
- 각 반복에서 추출된 표현 $\Theta$는 다음 반복을 위한 $N$개의 이미지 세트를 생성하는데 사용됨
- 그리고 생성된 이미지들은 일관적 특징을 정제하는데 사용됨
- 고정된 수의 반복을 수행하는 것이 아니라 본 논문에서는 수렴에 대한 기준을 세우고 early stopping을 가능하도록 함
- 각 반복 후에 새롭게 생성된 이미지들의 $N$개의 임베딩 사이의 모든 쌍에 대한 Euclidean 거리의 평균을 계산하고 이것이 사전에 설정한 $d_{conv}$보다 작다면 반복을 정지
3. Experiments
3.1. Qualitative and Quantitative Comparison
- 본 논문의 기법을 기존의 개인화 기법들과 비교
- 각 실험에서 각 기법들은 입력 프롬프트 $p$로부터 SDXL을 통해 생성된 단일 이미지에서 특징을 추출하는 방법을 사용
- Textual Inversion (TI)
- 동일한 컨셉의 몇장의 이미지로 텍스트 토큰을 최적화 → SDXL의 두 텍스트 인코더에 대해 2개의 텍스트 토큰을 학습하여 변환
- LoRA DreamBooth (LoRA DB)
- 일반적인 DB보다 오버피팅이 덜 발생함
- 이미지 인코더 기반 기법들과도 성능 비교
- 단일 이미지를 확산 모델의 텍스트 공간으로 인코딩하여 새로운 장면에서 대상을 생성
- 기법: BLIP-Diffusion, ELITE, IP-adapter
- 모든 비교 모델에 대해 동일한 프롬프트 $p$를 통해 생성된 단일 이미지로 최적화를 통해 특징을 추출하거나 (TI, LoRA DB) 인코딩을 통해 특징을 추출 (ELITE, BLIP-diffusion, IP-adapter)
- 그림 5를 보면 정성적인 결과 비교를 수행한 것을 확인할 수 있음

- TI, BLIP-Diffusion, IP-adapter는 프롬프트를 따라 이미지를 생성하지만 캐릭터의 일관성을 잘 유지하지 못함
- LoRA DB의 경우 일관된 생성은 잘 하지만 캐릭터가 동일한 포즈로 고정되어 버림
- ELITE는 프롬프트를 잘 따르지 못하고 생성된 캐릭터가 변형되어버림
- 본 논문의 기법의 경우 일관성도 유지하면서 다른 포즈나 각도 등에서 생성을 잘 수행함
- 또한 정량적 성능 비교도 수행
- ChatGPT를 사용하여 다른 종류의 캐릭터들(e.g. 동물, 물건 등)을 다른 스타일 (e.g. 스티커, 애니메이션, 실제적인 이미지 등)로 생성하기 위한 프롬프트를 생성
- 각 프롬프트는 본 논문의 기법과 다른 기법들을 통해 일관된 캐릭터를 추출하는데 사용됨
- 본 논문에서는 두가지 평가 지표 사용
- 프롬프트 유사도
- 생성된 이미지와 텍스트 프롬프트 입력 사이의 일치도 측정
- CLIP 유사도 사용 → 입력된 이미지에 대한 CLIP의 이미지 임베딩과 입력 프롬프트 사이의 정규화된 코사인 유사도 사용
- 특징의 일관성
- 동일한 프롬프트로 생성된 이미지들의 CLIP 이미지 임베딩 사이의 유사도 계산
- 프롬프트 유사도
- 그림 6의 왼쪽을 보면 프롬프트 유사도와 특징의 일관성 사이에 trade-off가 있는 것을 알 수 있음
- LoRA DB와 ELITE는 높은 특징 일관성을 보이지만 프롬프트 유사도를 희생
- TI와 BLIP-Diffusion은 높은 프롬프트 유사도를 가지지만 낮은 특징 일관성을 가짐
- 본 논문의 기법은 IP-Adapter보다 높은 특징 일관성을 보임
3.2. User Study
- Amazon Mechanical Turk (ATM) 플랫폼을 통해 유저 스터디를 통한 평가 수행
- 1-5점으로 프롬프트 일치도와 특징의 일관성을 평가자들을 통해 평가 수행
- 프롬프트 유사도 랭킹을 위해서 타겟 프롬프트와 이에 대한 모든 기법들의 결과를 보고 평가자들이 이미지들을 평가하도록 함
- 특징 일관성을 위해서는 각 생성된 컨셉에 대해 다른 타겟 프롬프트로 생성된 결과들을 랜덤하게 선택하여 평가자들이 1-5점으로 평가하도록 함
- 그림 6의 오른쪽을 통해 결과 확인 가능 → 제안된 기법이 특징 일관성과 프롬프트 유사도 사이에서 좋은 균형 잡힌 성능을 보임
3.3. Ablation Study
- 다음의 사항들에 대해 Ablation 스터디 수행
- (1) 군집화 생략: 군집화 과정을 생략하고 입력 프롬프트에 의해 생성된 5장의 이미지만 사용
- (2) LoRA 생략: 특징 추출 단계에서 최적화 가능한 $\Theta$를 축소 → 새롭게 추가된 텍스트 토큰만 사용하고 추가적인 LoRA 가중치를 사용하지 않음
- (3) Re-initalization 추가: 각 최적화 반복에서 최신의 $\Theta$를 사용하는 대신 각 반복마다 초기화 (initialization)를 수행
- (4) 단일 반복: 수렴할때까지 반복하는 것이 아니라 단일 반복 이후에 정지
- 그림 6의 왼쪽을 보면 일관된 특징을 달성하기 위해 어떤 요소들이 중요한지 확인할 수 있음
- (1)의 경우 군집화가 생략되어 학습 세트가 너무 다양해져서 일관성 추출에 나쁜 영향을 줌
- (2)는 underfittin을 유발 → 충분한 파라미터를 가지지 못해서 특성을 제대로 학습하지 못함
- (3)과 (4)는 모델이 단일 특성으로 수렴하지 못하도록 함
3.4. Applications
- 그림 7을 통해 본 논문의 기법이 사용될 수 있는 다양한 사례들을 보임

- (a) 다른 장면들에서 동일한 캐릭터를 사용하여 이야기에 대한 그림 생성 가능
- (b) Blended Latent Diffusion과 결합하여 텍스트에 기반하여 이미지의 일부를 수정하는 기능으로 사용 가능
- (c) ControlNet을 사용하여 동일한 캐릭터를 다양한 포즈로 생성 가능
4. Limitations and Conclusions
- 본 논문의 기법은 다음과 같은 한계들을 가짐 → 그림 8 참고

- (a) 일관되지 않은 특징
- 특정 경우에서 완전히 일관적인 특징으로 수렴하지 못함
- 그림 8 (a)를 보면 로봇 그림에서 색이나 모양이 다른 경우들이 종종 발생
- 이는 프롬프트가 너무 일반적이어서 특징을 군집화할 때 충분히 응집된 세트를 찾지 못해서 발생하는 것으로 생각됨
- (b) 일관되지 않은 추가적인 대상
- 입력된 캐릭터 외에 다른 캐릭터가 추가되는 경우 (e.g. 입력 캐릭터의 애완동물) 일관적이지 않은 특성을 보임
- 그림 8 (b)를 보면 프롬프트에서 한 여자아이와 그녀의 고양이를 생성하도록 요청 → 다른 고양이들이 생성되는 것을 확인할 수 있음
- (c) 가짜 특성들
- 입력 프롬프트와 관계 없는 추가적인 특성들이 함께 생성되는 경우
- 그림 8 (c)를 보면 입력 프롬프트는 “황갈색 고양이의 스티커”지만 생성된 스티커에 계속 초록색 잎들이 추가된 겻을 확인할 수 있음
- 이는 특징 군집화 단계에서 가장 응집된 군집인 $c_{cohesive}$에 잎들이 있어서 추가된 것으로 생각
- 이를 피하기 위해서는 자동적으로 군집을 선택하는 것이 아니라 사용자가 직접 선택하는 방법이 있음
- (d) 엄청난 계산량
- 본 기법의 각 단계는 많은 이미지 생성, 가장 응집된 군집의 특성 학습을 포함
- 일관된 특성으로 수렴하는데 약 20분 소요
- (e) 단순화된 캐릭터
- 본 논문의 기법은 단순한 장면들을 생성할 수 있음 (중심에 위치한 단일 객체)
- 이는 특징 추출 단계의 “평균” 효과에 의해 발생
- (a) 일관되지 않은 특징
- 결론적으로 본 논문의 기법은 일관된 캐릭터 생성 문제에 대해 최초로 완전히 자동화 된 해결책을 제시
반응형



