
- Link: https://arxiv.org/pdf/2102.04376.pdf
- Official Code: https://github.com/yfletberliac/adversarially-guided-actor-critic
1. Introduction
- Actor-critic 기반 알고리즘의 경우 복잡한 환경에서 sample inefficiency 문제가 여전히 발생 → 특히 효율적인 exploration이 필요한 문제가 bottleneck
- 제안하는 알고리즘! → Adversarially Guided Actor-Critic (AGAC): 더욱 포괄적인 exploration을 유도
- AGAC는 actor-critic 프레임워크를 재정의하여 세번째 요소인 adversary를 추가
- Adversary는 actor의 행동을 예측하는 것을 목표로 함, 반면 actor는 expected returns의 합을 최대로 하는 optimal action을 찾는 것 뿐 아니라 adversary의 예측과 다르게 행동해야함
- Adversarial method → GAN과 유사하게 생각할 수 있음
- Adversary의 경우 discriminator와, actor의 경우 generator와 유사한 역할 수행
- 본 논문에서 수행할 작업
- 어떻게 AGAC가 explicit하게 에이전트가 보상에 집중하면서도 다양한 행동을 하게 만들지 분석
- 해당 기법을 procedurally-generated 환경에 적용 → 매 새로운 에피소드마다 맵이 다르게 생성됨
- Adversarial network가 hyperparameter sensitivity issue가 있으므로 이에 대해서도 분석
- Contribution
- Adversarial learning으로부터 영감을 받은 새로운 actor-critic formulation 제안
- AGAC를 diversity, exploration, stability 관점에서 경험적으로 분석
- Procedually-generated task를 포함하는 몇몇의 sparse-reward hard-exploration 문제에서 뛰어난 성능 확인
2. Adversarially Guided Actor-Critic
- Adversary의 역할
- Actor의 행동을 정확히 예측하여 adversary가 추정한 action distribution $\pi_{adv}$와 실제 policy $\pi$ 사이의 차이를 최소화 하는 것
- Actor의 역할
- 예측 기대값의 합을 최대로 하는 최적의 행동을 찾는 동시에 adversary의 예측과 차이를 최대로 하는 policy 도출 → $\pi$와 $\pi_{adv}$ 사이의 차이를 최대로
- Policy간의 log-probability 차이를 exploration bonus의 형태로 사용 → expectation은 Kullback-Leibler divergence
- $D_{KL}(\pi(\cdot|s)||\pi_{adv}(\cdot|s)) = E_{\pi(\cdot|s)}[\log \pi(\cdot|s) - \log \pi_{adv}(\cdot|s)]$
- 파라미터
- $\theta$: Policy의 파라미터 ($\theta_{old}$는 이전 iteration에서 policy의 파라미터)
- $\phi$: Critic의 파라미터 ($\theta_{old}$는 이전 iteration에서 critic의 파라미터)
- $\psi$: adversary의 파라미터 ($\psi_{old}$는 이전 iteration에서 adversary의 파라미터)
- Loss (Adversary에 대한 loss 추가) → adversary가 추가되면서 변한 부분 (파란글씨)
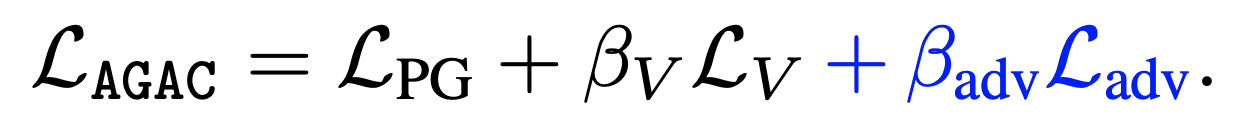
- 새로운 objective $L_{PG}=-\frac{1}{N}\sum_{t=0}^{N}(A_{t}^{AGAC}\log \pi(a_t |s_t , \theta) + \alpha H^{\pi} (s_t, \theta))$
- AGAC에서는 $A_t$를 다음과 같이 변경
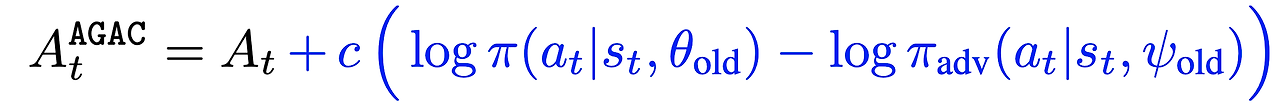
- $c$: action log-probability 차이에 대한 의존도를 조절하는 하이퍼 파라미터
- Asymptotic stability를 방지하지 않고 exploration을 장려하기 위해 $c$를 학습동안에 선형적으로 감소시킴
- $L_V$는 critic의 objective function

- 마지막으로 adversary의 objective function $L_{adv}$

- $\beta_V$와 $\beta_{adv}$는 고정된 하이퍼파라미터
- 제안된 actor-critic formulation에서는 행동을 샘플링하는 확률은 변경된 advantage가 양수일때 증가
- (i) 반환값이 예측된 가치보다 클떄
- (ii) action log-probability 차이가 클 때
- 더 구체적으로는 평균 행동보다 행동이 덜 정확하게 예측될 때 transition을 선호
- $\log \pi (a|s) - \log \pi_{adv}(a|s) \geq D_{KL}(\pi(\cdot |s) || \pi _{adv}(\cdot |s))$
- 이는 특히 $\lambda \rightarrow 1$ 일 때 볼 수 있음 → generalized advantage가 $A_t = G_t - V_{\phi_{old}}(s_t)$ 인 경우
- 이를 통해 변경된 advantage

- $G_t$: 관측된 return, $\hat{V}{t}^{\phi{old}}$: 예측된 return, $\hat{D}{KL}^{\phi{old}}(\pi(\cdot|s_t )||\pi_{adv}(\cdot |s_t ))$는 예측된 KL-divergence
- Instability를 피하기 위해 adversary는 분리된 estimator로 사용하고 actor보다 작은 learning rate 사용
- actor의 policy 보다 더 지연되고 느린 버전 → 에이전트가 계속 adversary를 속이는데만 집중하는 것을 방지
2.1 Building Motivation
- Actor와 adversary 간의 attraction & repulsion dynamics에 의한 AGAC의 해석
- AGAC의 modified action-value

- iteration $k$에서 policy가 $\pi_k$일 떄 Entropic penalty를 포함한 새로운 policy $\pi_{k+1}$은 다음과 같음

- 이 objective를 다음과 같이 다시 쓸 수 있음
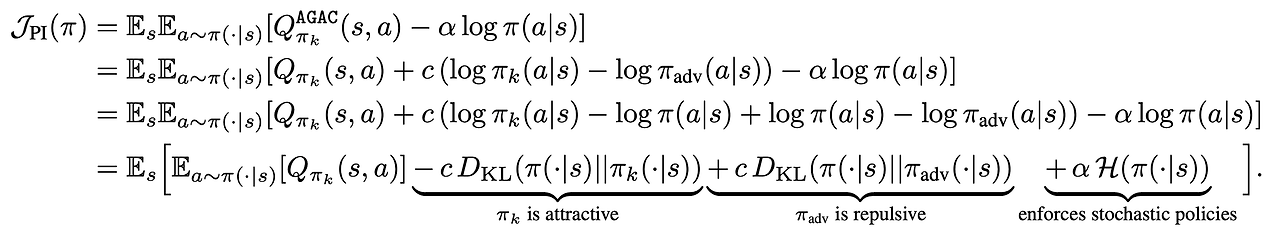
- 이 Policy iteration scheme에서 AGAC는 Q-value를 최대화하는 policy를 찾는 동시에 현재 policy가 이전 policies의 조합과 최대한 멀어지게 해야함 ($i.e., \pi_{k-1}, \pi_{k-2}, ...$)
2.2 Implementation
- PPO를 baseline으로 제안하는 알고리즘 적용

- $N$: 파라미터 한번 업데이트를 위한 temporal length, $\epsilon$: clipping parameter
- episodic state visitation count에 따라 PPO를 discount (VizDoom 제외)
- Actor, Critic, Adversary는 DQN과 동일한 conv 구조 사용
- Optimizer → Adam
- Frame stacking 사용
- Policy, Critic, Adversary가 network를 공유하지 않음 → 하지만 AGAC와 PPO 사이의 계산 복잡도는 크게 차이나지 않음
- 계수 $c$ (adversarial bonus)는 선형적으로 annealed
- 각 학습 스텝의 stochastic optimization step에서 stop-gradient를 사용하여 $L_{AGAC}$를 최소화

3. Experiments
- Experimental study를 통해 다음의 4가지를 살펴볼 예정
- Adversarial bonus만 (e.g. episodic state visitation count 제외)하고도 VizDoom에서 다른 기법들의 성능을 뛰어 넘을 수 있는지
- 다른 기법들과 비교해서 reward의 sparsity가 매우 높은 partially observable 환경이나 procedually-generated 환경에서도 좋은 성능을 낼 수 있는지
- Extrinsic reward 없이 AGAC가 얼마나 환경 내부를 잘 탐험할 수 있는지
- 제안하는 기법의 학습 안정성
- 본 기법의 코드!! → https://github.com/yfletberliac/adversarially-guided-actor-critic
Environments

- Robust exploration 전략과 본적 없는 상태에 대한 generalization 성능 검증을 위해 다음의 특성들을 가진 환경들을 통해 검증
- High-dimensional observations, sparse reward, procedurally generated environments
- 환경들
- VizDoom: 3D 환경에서 reward feedback 없이 복도를 지나 방으로 이동하는 방법을 학습해야함
- MiniGrid: partially observable, sparse reward gridworld, 3가지 종류의 환경으로 구성
- MultiRoom: 첫 방에서 시작해서 가장 먼 방에 있는 골로 이동
- KeyCorridor: 다른 방에 있는 열쇠를 줍고 잠긴 문을 연 다음 이동해야 함
- ObstructedMaze: 박스나 공 안에 있는 열쇠를 찾아서 문을 열고 3x3 maze 구석에 있는 박스를 집어야함
Baselines
- Hard Exploration task에 특화된 알고리즘들과 성능 비교
3.1 Adversarially-based Exploration (No Episodic Count)

- 표의 결과를 통해 AGAC가 명확하게 sample efficiency 측면에서 다른 기법들의 성능을 능가하는 것을 확인할 수 있음
3.2 Hard-Exploration Tasks with Partially-Observable Environments

- 위의 결과를 봤을 때 MiniGrid에서도 AGAC가 다른 기법들에 비해 sample-efficiency나 성능 측면에서 훨씬 좋은 결과를 보인다는 것을 확인할 수 있음
- 고려된 문제들에서 에이전트는 매우 큰 state space에서 generalize하는 것을 학습해야 함 → 왜냐하면 layout들이 procedurally 생성되기 때문
3.3 Training Stability

- 하이퍼 파라미터 변화에 따른 안정성 분석
- AGAC에서 가장 중요한 파라미터
- $c$: adversarial bonus의 계수
- $\nu = \frac{\eta_2}{\eta_1}$: learning rates
- 하이퍼 파라미터 변화에 따라서 학습 속도가 조금 달라지기는 하지만 reasonable한 정도, $c$가 $\nu$에 비해 더 sensitive함
3.4 Exploration in Reward-free Environment

- AGAC를 또다른 어려운 환경 (Procedurally generated)에서 extrinsic reward 없이 학습
- Reward-free AGAC도 약 15% 정도 성공률을 보이는 것을 확인
3.5 Visualizing Coverage and Diversity

- State visitation map → 많이 방문할수록 진한 색 (10M time step 학습)
- Singleton에서는 RIDE만 5번째 방까지, AGAC는 마지막 방까지 이동
- Procedurally generated에서는 조금 더 좋지 못한 결과를 보임

- Extrinsic reward 없이 procedurally generated 환경에서 10 에피소드 결과
- Extrinsic reward가 없지만 여전히 행동을 다양화 하며 다음으로 이동
4. Discussion
- 기존 actor-critic framework를 변경하여 세번째 요소로 adversary network를 추가한 AGAC 알고리즘 소개
- Adversary는 에이전트가 현재 policy와 유사하면서도 이전 policy와는 멀어지도록 학습시킴
- Adversary의 효과 → actor를 conservatively diversified
- 몇몇 실험을 수행
- 기존의 유명한 exploration 기법들 (RIDE, AMIGo, Count, RND, ICM) 보다 월등하게 좋은 성능 보임
- Procedurally-generated 환경에서의 성능 검증을 통해 unseen scenario에 대한 generalization 성능 확인
- Training stablity, reward가 없는 세팅에서 exploration 성능 등을 검증
- 위와 같은 결과들을 통해 adversary가 성공적으로 actor의 행동을 다양화하는 것을 확인
Appendix
A.1 MiniGrid Performance

A.2 State Visitation Heatmaps in Singleton Environment with no Extrinsic Reward

A.3 (Extremely) Hard-Exploration Tasks with Partially-Observable Environments
- 환경 → KeyCorridorS8R3, ObstructedMaze-Full

A.4 Mean Intrinsic Reward

B. Illustration of AGAC

C. HyperParameters

D. Implementation Details

'논문 리뷰 > Reinforcement Learning' 카테고리의 다른 글
| [M-RL] Munchausen Reinforcement Learning (1) | 2024.09.16 |
|---|---|
| [RND] Exploration by Random Network Distillation (1) | 2024.09.13 |
| [RND] Exploration by Random Network Distillation (5) | 2024.09.11 |
| [R2D2] Recurrent Experience Replay in Distributed Reinforcement Learning (2) | 2024.09.10 |
| [APE-X] Distributed Prioritized Experience Replay (0) | 2024.09.10 |



