반응형


0. Abstract
- 최근 BitNet과 같은 연구들이 새로운 1-bit LLM (Large Language Model)의 시대를 위한 길을 닦고 있음
- 본 논문에서는 1-bit LLM의 변형인 BitNet b1.58을 제안!
- LLM의 모든 파라미터를 {-1, 0, 1}의 세 값 중 하나로 설정
- 대기 시간 (latency), 메모리, 처리량 (throughput), 에너지 소모에 대해 아주 비용 효율적
- 동일한 크기의 FP16이나 BF16 트랜스포머 모델과 비교했을 때 perplexity나 세부 문제들 (end-task)에 대해 유사한 성능을 보임
- 또한 1.58 bit LLM은 다음의 두가지를 정의
- 새로운 스케일링 법칙 (Scaling Law)
- 성능도 좋으면서 비용도 효율적인 새로운 세대의 LLM에 대한 학습 방법
1. The Era of 1-bit LLMs
- 최근 AI 분야에서 LLM의 능력과 함께 사이즈가 크게 증가
- 높은 에너지 소모 → 경제적, 환경적으로 부정적인 영향
- 개선 방안 1: PTQ (Post-Training Quantization)
- 추론을 위해 낮은 비트(bit)의 모델을 생성
- 학습이 완료된 모델의 가중치와 활성화(activation)의 정밀도(precision)를 낮춤 → LLM의 메모리와 계산이 크게 감소
- 최근에는 16비트에서 4비트와 같은 더 낮은 비트 수로 정밀도를 낮추는 추세
- 해당 기법은 산업적으로 널리 사용되지만 최적의 방법은 아님 (sub-optimal)
- 개선 방안 2: 1-bit 모델
- 최근 BitNet과 같은 1-bit 모델 구조가 제안되며 LLM의 성능을 유지하면서도 비용은 감소시키는 새로운 방향이 제시됨
- 장점 1: 연산량 감소
- 기본 LLM은 많은 행렬곱에 일반적으로 16-bit의 부동소수점 값 (i.e. FP16, BF16) 사용 → 16-bit 덧셈과 곱셈 연산에 많은 계산 비용을 사용
- 이와 대조적으로 BitNet의 행렬곱은 오직 덧셈만으로 연산 가능 → LLM의 에너지 비용 절약 + 빠른 연산 가능
- 장점 2: DRAM → SRAM 모델 파라미터 전달 비용 감소
- 추론 동안 DRAM으로 부터 모델 파라미터를 SRAM과 같은 칩 내부의 가속기 (on-chip accelerator)의 메모리로 전달하는 과정 또한 높은 비용이 발생
- 1-bit LLM의 경우 전체 정밀도 (full-precision)을 사용하는 모델에 비해 용량과 대역폭 (bandwidth) 측면에서 훨씬 낮은 메모리를 사용
- 이로 인해 1-bit LLM을 사용하면 DRAM에서 가중치를 불러오는 비용과 시간을 크게 줄일 수 있으므로 더 빠르고 효율적인 추론 가능

- 본 논문에서 제안하는 기법: BitNet b1.58 (그림 1 참고)
- 모든 파라미터가 {-1, 0, 1}의 세 값중 하나의 값을 가짐
- 기존 1-bit LLM에 비해 0의 값을 추가적으로 사용 = 1.58bit
- 우선 1.58bit은 다음과 같이 1-bit Bitnet이 가지는 장점을 모두 가짐
- 곱셈 연산을 수행하지 않으므로 훨씬 더 최적화가 가능
- 전체 정밀도를 가지는 LLM 모델에 비해 더 효율적인 메모리 사용, 처리량, 대기 시간을 가짐
- BitNet b1.58은 다음과 같은 추가적인 장점들을 가짐
- 모델 가중치에 0을 포함 → 특징 필터링 (feature filtering)을 지원하여 1-bit LLM의 성능을 크게 향상시킴
- 실험 결과에 따라 동일한 설정 (예시: 모델 크기, 학습 토큰 수 등)에서 3B 규모부터 FP16과 동등한 수준의 perplexity와 세부 문제 성능을 달성
2. BitNet b1.58
- BitNet b1.58은 BitNet 구조를 기반으로 함
- 트랜스포머의 nn.Linear를 BitLinear로 대체
- 1.58-bit의 가중치와 8-bit의 활성화 (activations)로 처음부터 (scratch) 학습 수행
Quantization Function
- 가중치를 -1, 0, +1로 제한하기 위해 absmean 양자화 (quantization) 함수를 사용
- 먼저 가중치 함수를 절대값의 평균값으로 스케일하고 각 값을 {-1, 0, 1} 중 가까운 값으로 반올림
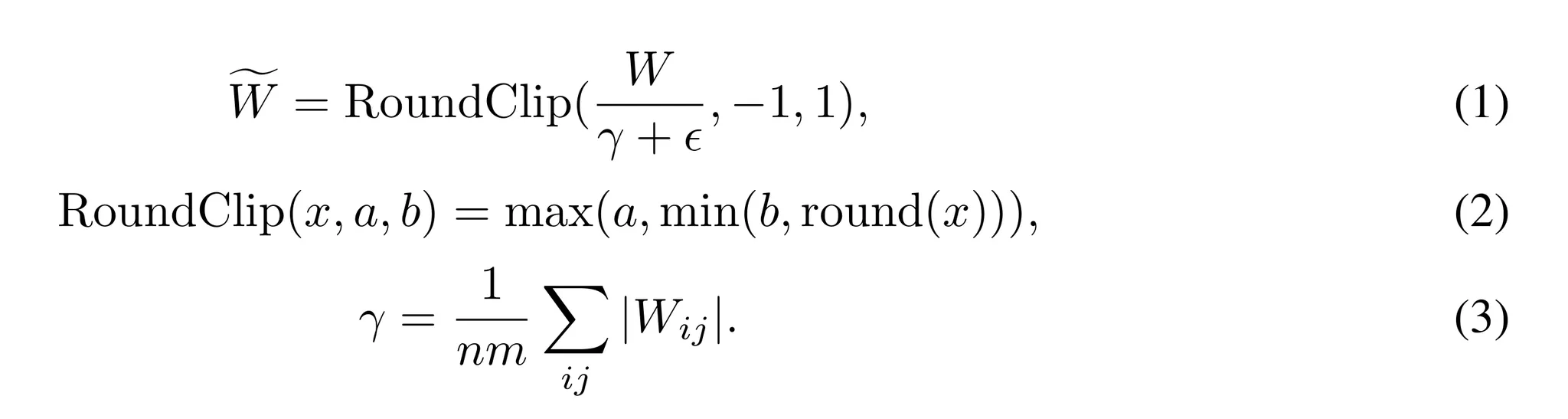
- 활성화에 대한 양자화 함수
- BitNet의 구현과 동일하지만 비선형 함수 이전에 $[0, Q_b]$로 스케일링을 하지 않음
- 대신 활성화는 모두 토큰별로 $[-Q_b, Q_b]$로 스케일링하여 영점 양자화 (zero-point quantization)를 제거
- 이는 구현과 시스템 최적화를 단순화하기 위해 수행되었으며 성능 저하는 거의 없었음
LLaMA-alike Components
- LLaMA와 유사한 설계를 채택 → 오픈소스 생태계와의 호환성을 확보.
- LLaMA로부터 사용한 구성 요소:
- RMSNorm
- SwiGLU
- Rotary embedding
- Bias 제거
- 이에 따라 BitNet을 Huggingface, vLLM, llama.cpp 같은 인기 오픈소스 프레임워크에 쉽게 통합 가능
3. Results
- BitNet b1.58을 다양한 모델 크기에서 FP16 LLaMA LLM과 성능 비교
- 공평한 비교를 위해 모든 모델에 대해 다음과 같은 설정 수행
- RedPajama 데이터셋으로 사전학습 (100B 토큰)
- 다양한 언어 모델 문제에 대해 제로샷 성능 평가
- 사용한 문제들: ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, OpenbookQA, BoolQ
- 또한 WikiText2, C4에 대해서는 perplexity로 성능 비교
- 또한 LLaMA LLM과 BitNet b1.58을 런타임 GPU 메모리와 지연 (latency) 측면에서 성능 비교
- FasterTransformer 코드베이스로 성능 측정 - https://github.com/NVIDIA/FasterTransformer
- BitNet b1.58에는 Ladder의 2-bit 커널도 적용 (https://www.usenix.org/system/files/osdi24-wang-lei.pdf)
- 출력 토큰당 시간으로 성능 비교

- 표 1을 통해 BitNet b1.58과 LLaMA LLM의 비용과 perplexity를 비교한 결과를 살펴볼 수 있음
- BitNet b1.58이 3B 모델부터 전체 정밀도를 가지는 LLaMA LLM과 perplexity 측면에서 유사한 성능을 보이기 시작
- 게다가 속도는 2.71배 빠르며 GPU 메모리는 3.55배 덜 사용
- 특히 BitNet b1.58를 3.9B 모델에 적용한 경우 LLaMA LLM 3B보다 2.4배 빠르고 3.32배 적은 메모리를 사용하면서도 더 좋은 성능을 보임

- 다음으로 표 2는 세부 문제들에 대한 제로샷 성능을 보여줌
- lm-evaluation-harness의 파이프라인을 사용하여 평가 수행
- 해당 결과에서는 모델 크기가 커질수록 BitNet b1.58과 LLaMA LLM의 성능 차이가 줄어드는 것을 확인
- Perplexity 결과와 유사한 다음의 결과들을 보임
- BitNet b1.58이 3B 크기에서 전체 정밀도 베이스라인과 유사한 성능을 보임
- BitNet b1.58을 3.9B에 적용한 결과 더 적은 메모리와 지연 비용으로 LLaMA LLM 3B의 성능을 능가
Memory and Latency

- 그림 2를 보면 모델을 7B, 13B, 70B로 확장하면서 지연과 메모리에 대한 비용을 평가
- 속도의 경우 모델의 크기가 커질 수록 비율이 같이 증가하는 것을 확인할 수 있음
- BitNet b1.58 70B의 경우 LLaMA LLM에 비해 4.1배나 빠름
- 메모리 소모도 유사한 경향을 보임
- 속도의 경우 모델의 크기가 커질 수록 비율이 같이 증가하는 것을 확인할 수 있음
Energy
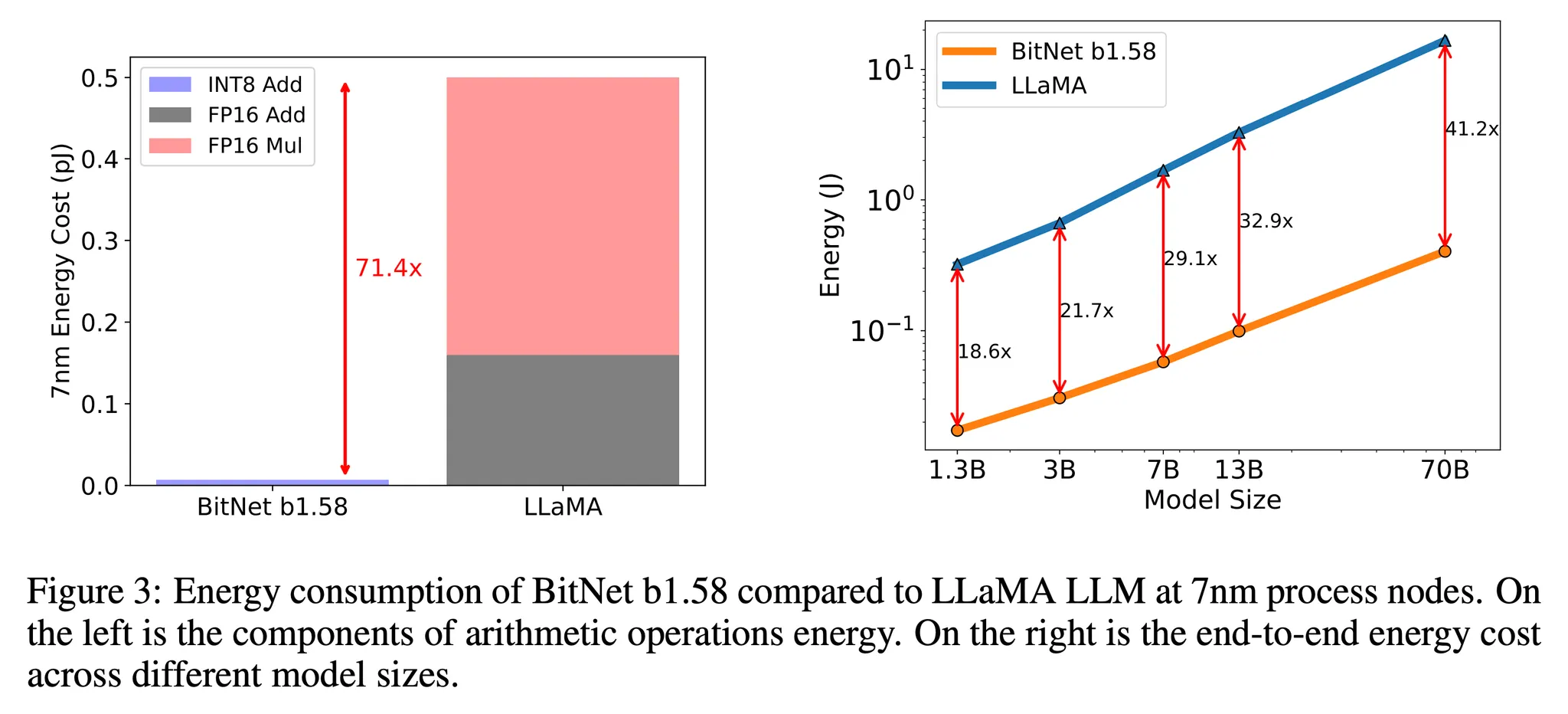
- 산술적 연산에 대한 에너지 소모 비용을 추정 → 특히 LLM의 주된 계산 비용인 행렬곱을 주로 살펴봄 (그림 3)
- BitNet b1.58의 경우 대부분의 계산이 INT8 덧셈인 반면 LLaMA LLM은 FP16 덧셈과 곱셈 계산을 사용
- BitNet b1.58가 7nm 칩에서 71.4배의 산술적 연산 에너지 소모를 절약하는 것을 알 수 있음
- 해당 결과는 모델 사이즈 증가에 따라 BitNet b1.58이 에너지 소모 측면의 효율성이 증가한다는 것을 보임
- 왜냐하면 모델 내부의 nn.Linear의 비율도 모델 사이즈에 따라 함께 증가하기 때문!
Throughput

- 두개의 A100 80GB를 사용하여 BitNet b1.58과 LLaMA LLM 70B의 처리량을 비교 (표 3 참고)
- 배치 사이즈는 GPU 메모리의 한계까지 사용했고 시퀀스 길이는 512로 설정
- BitNet b1.58 70B가 LLaMA LLM에 비해 11배 더 많은 배치 사이즈를 사용할 수 있으며 8.9배 더 많은 처리량을 보임
BitNet b1.58 is enabling a new scaling law with respect to model performance and inference cost
- 그림 2, 3의 결과를 통해 서로 다른 모델 크기에서 1.58-bit과 16-bit을 비교한 결과가 다음과 같음
- 13B BitNet b1.58이 3B FP16 LLM에 비해 지연 시간, 메모리, 에너지 소모 측면에서 효율적
- 30B BitNet b1.58이 7B FP16 LLM에 비해 지연 시간, 메모리, 에너지 소모 측면에서 효율적
- 70B BitNet b1.58이 13B FP16 LLM에 비해 지연 시간, 메모리, 에너지 소모 측면에서 효율적
Training with 2T Tokens
- 학습 토큰 수는 LLM에 있어 중요한 요소!
- 토큰 측면에서 BitNet b1.58의 확장성을 테스트하기 위해 StableLM-3B의 데이터 레시피를 따라 BitNet b1.58을 2T 토큰으로 학습
- 모델 평가 벤치마크: Winogrande, PIQA, SciQ, LAMBADA, ARC-easy

- 제로샷 정확도 결과는 표 4 참고
- BitNet b1.58이 모든 문제에서 더 나은 성능을 보이는 것을 확인 → 1.58-bit LLM의 강력한 일반화 능력을 보여줌!
4. Discussion and Future Work
1-bit Mixture-of-Experts (MoE) LLM
- MoE는 LLM을 위한 비용 효율적인 기법
- 이는 연산 FLOPs를 크게 줄이지만 메모리 사용량이 크게 증가하며 칩 간 통신 (inter-chip communication) 비용이 큼
- 이 문제는 1.58-bit LLMs로 해결될 수 있음
- 메모리 감소 → MoE 모델들을 배치할 때 요구되는 기기의 수 감소
- 네트워크 간 활성화 (activations)를 전송하는 비용을 크게 감소
- 궁극적으로 만약 전체 모델이 단일 칩에 배치된다면 이런 통신 비용은 아예 발생하지 않음
Native Support of Long Sequence in LLMs
- LLM에 있어 긴 시퀀스의 입력을 처리하는 능력은 매우 중요한 요소!
- 하지만 긴 시퀀스 추론에 있어 문제가 되는 주된 요소는 KV 캐시에 의한 메모리 소모
- BitNet b1.58은 이런 긴 시퀀스를 지원하는데 큰 도움을 지원 → 활성화를 16-bit에서 8-bit로 감소시킴으로서 동일 자원에서 컨텍스트의 길이를 2배로 사용할 수 있음
LLMs on Edge and Mobile
- 1.58-bit LLM의 사용은 엣지와 모바일 기기에서 언어 모델의 성능을 크게 향상시킬 수 있음
- 이런 기기들은 메모리나 계산 자원이 한정적인만큼 LLM의 성능이나 크기가 제한됨
- 그러나 1.58-bit LLM의 감소된 메모리와 에너지 소모를 통해 언어 모델이 이런 기기에 배포될 수 있음
- 또한 1.58-bit LLM은 엣지와 모바일 기기에서 주로 사용되는 처리장치인 매우 CPU 기기에 친숙한 기법이므로 1.58-bit LLM이 이런 기기들에서 더욱 효율적으로 실행되며 성능을 향상시킬 수 있음
New Hardward for 1-bit LLMs
- 최근에 Groq은 LLM을 위한 새로운 하드웨어 (e.g. LPUs) 설계에 대한 의미있는 결과와 큰 가능성을 보임
- 이보다 한단계 나아가서 본 논문에서는 1-bit LLM을 위해 최적화 된 하드웨어와 시스템이 디자인 될 필요가 있음을 주장
반응형